Python 爬虫从入门到进阶之路(三)
之前的文章我们做了一个简单的例子爬取了百度首页的 html,本篇文章我们再来看一下 Get 和 Post 请求。
在说 Get 和 Post 请求之前,我们先来看一下 url 的编码和解码,我们在浏览器的链接里如果输入有中文的话,如:https://www.baidu.com/s?wd=贴吧,那么浏览器会自动为我们编码成:https://www.baidu.com/s?wd=%E8%B4%B4%E5%90%A7,在 Python2.x 中我们需要使用 urllib 模块的 urlencode 方法,但我们在之前的文章已经说过之后的内容以 Python3.x 为主,所以我们就说一下 Python3.x 中的编码和解码。
在 Python3.x 中,我们需要引入 urllib.parse 模块,如下:
import urllib.parse
data= {"kw":"贴吧"}
# 通过 urlencode() 方法,将字典键值对按URL编码转换,从而能被web服务器接受。
data = urllib.parse.urlencode(data)
print(data) # kw=%E8%B4%B4%E5%90%A7
# 通过 unquote() 方法,把 URL编码字符串,转换回原先字符串。
data = urllib.parse.unquote(data)
print(data) # kw=贴吧
下面我们来看一下 Get 请求
GET请求一般用于我们向服务器获取数据,比如说,我们用百度搜索 贴吧,结果如下
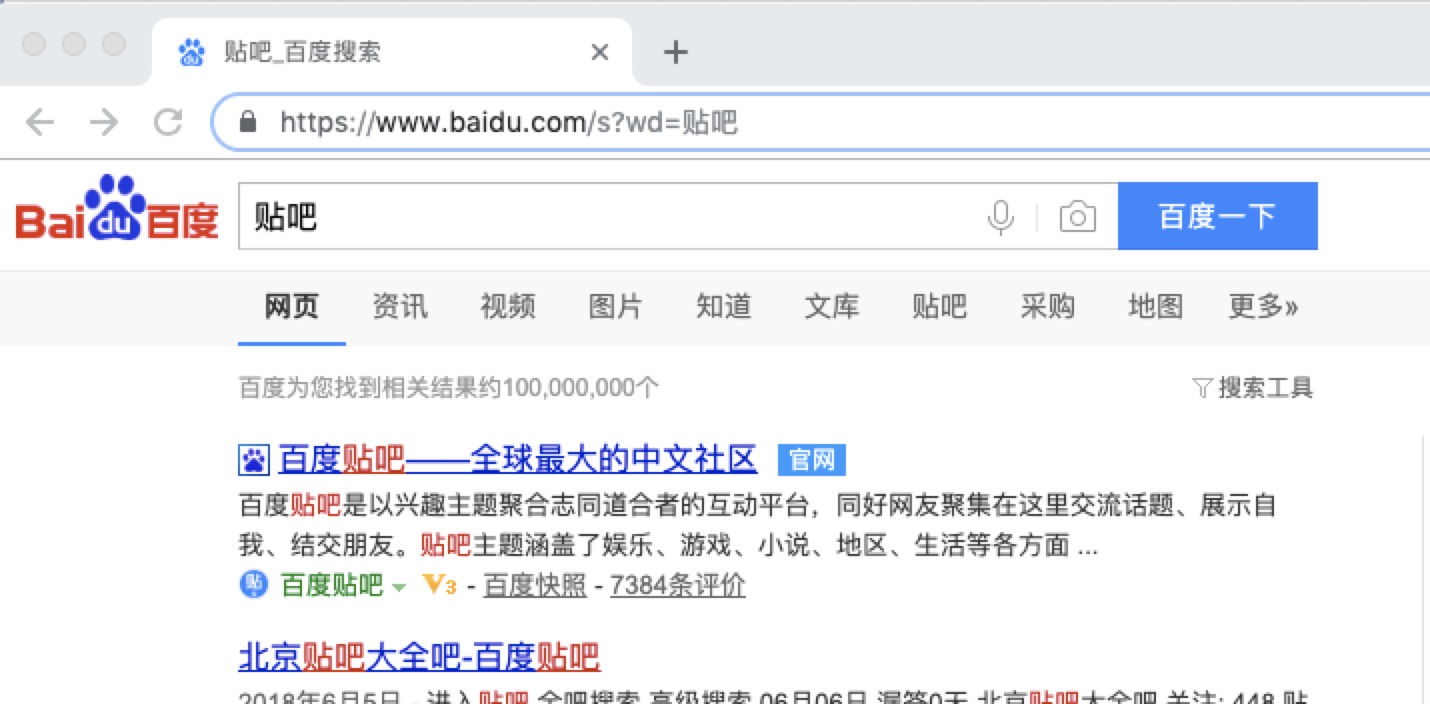
在其中我们可以看到在请求部分里,http://www.baidu.com/s? 之后出现一个长长的字符串,其中就包含我们要查询的关键词 贴吧,于是我们可以尝试用默认的 Get 方式来发送请求。
import urllib.request
import urllib.parse
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context # url 地址
url = "http://www.baidu.com/s"
word = {"wd": "贴吧"}
word = urllib.parse.urlencode(word) # 转换成url编码格式(字符串)
url = url + "?" + word # url首个分隔符就是 ? # User-Agent
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"} # url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request(url, headers=headers) # Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request) # 类文件对象支持 文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read().decode("utf-8") # 打印字符串
print(html)
我们在请求页面的时候将我们要传的值直接通过转码拼接在 url 地址后面,然后就可以获取到我们想要的内容了,最终结果如下:

通过开发者工具看页面的 HTML 和我们得到的结果是完全一致的。
接下来我们看一下 post 请求,先来看一个 post 请求接口:https://movie.douban.com/j/chart/top_list?type=11&interval_id=100:90&start=0&limit=10,该接口为豆瓣的一个电影列表接口,为 post 请求,url 问号后面的为请求参数,结果如下:
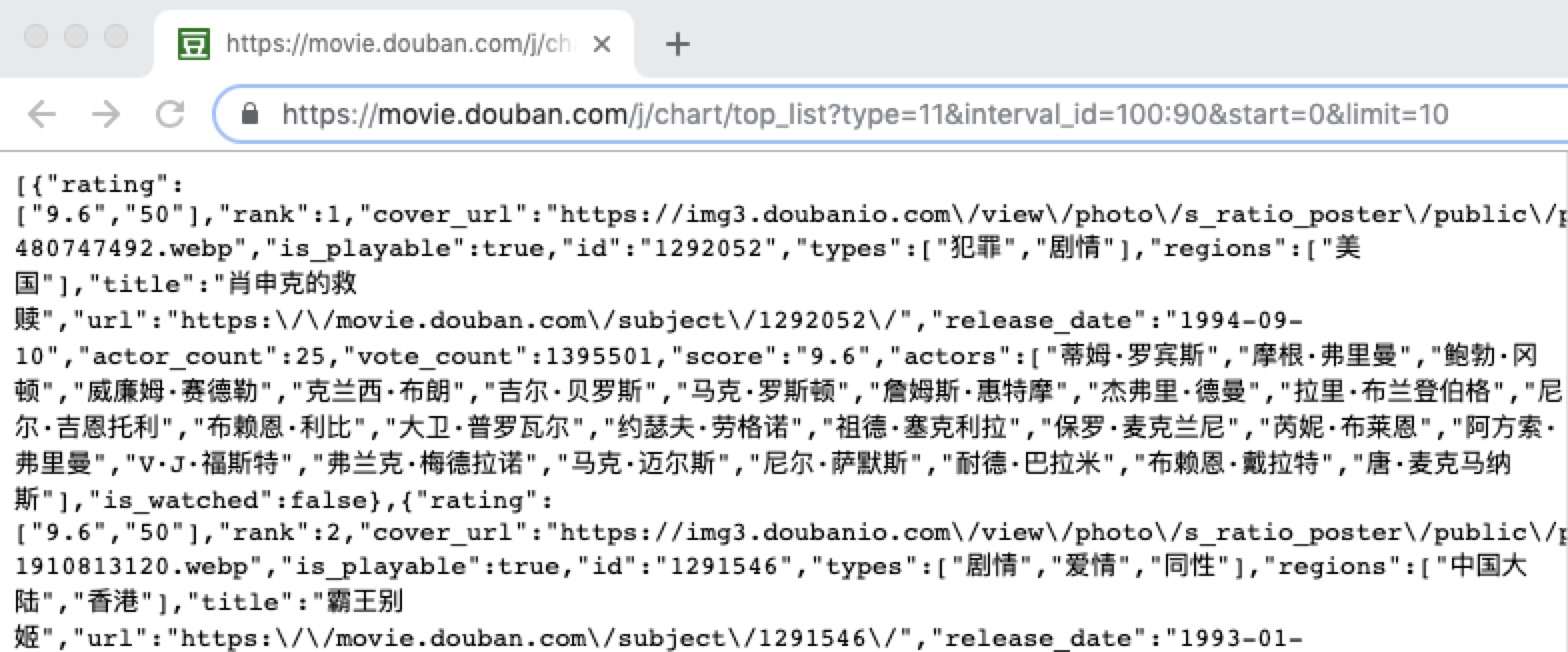
如果我们要使用 urllib 的 post 请求,则要在 Request 第二个参数加入我们想要的参数,如下:
import urllib.request
import urllib.parse
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context # User-Agent
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
# post 请求参数
data = {
"type": "",
"interval_id": "100:90",
"start": "",
"limit": ""
}
data = urllib.parse.urlencode(data).encode("utf-8") # url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("https://movie.douban.com/j/chart/top_list?", data=data, headers=headers) # Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request) # 类文件对象支持 文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read().decode("utf-8") # 打印字符串
print(html)
urllib 默认的是 get 请求,urllib.request.Request() 里第一个参数为 url 地址,第二个参数为请求报头 headers,请求包头可以不写。
urllib 默认的是 get 请求,urllib.request.Request() 里第一个参数为 url 地址,第二个参数为请求数据 data,第三个参数为请求报头 headers,请求包头可以不写。
最终结果如下:

和我们在页面请求的结果是一样的。
为什么有时候POST也能在URL内看到数据?
GET方式是直接以链接形式访问,链接中包含了所有的参数,服务器端用Request.QueryString获取变量的值。如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。
POST则不会在网址上显示所有的参数,服务器端用Request.Form获取提交的数据,在Form提交的时候。但是HTML代码里如果不指定 method 属性,则默认为GET请求,Form中提交的数据将会附加在url之后,以
?分开与url分开。表单数据可以作为 URL 字段(method="get")或者 HTTP POST (method="post")的方式来发送。
Python 爬虫从入门到进阶之路(三)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- Jmeter之聚合报告
1.添加线程组,添加请求接口 2.设置线程组 3.线程组右击添加—>监听器—>聚合报告
- 洛谷 P3960 列队
https://www.luogu.org/problemnew/show/P3960 常数超大的treap #pragma GCC optimize("Ofast") #incl ...
- 2017zstu新生赛
1.b^3 - a^3 = c(zy) zy说要卡nlogn的,然而他实际给的组数只有100组,然后因为在windows下随机的,所以给出的 c <= 100000.然后只要胆子大.... 通过 ...
- SqlParameter 操作 image 字段
public static void AddEmployee( string lastName, string firstName, string title, DateTime hireDate, ...
- JAVA Map的使用
学JAVA那么多天了,所以就不写那啥了,哈哈 Map 是一个很实用的东西,它查询的速度也是飞快的.还有很多好的地方, 至于好在哪里,我也说不清. 还是用代码来说吧: import java.util. ...
- Web版简易五子棋
前些时候把大三写的C++版五子棋改成Web板挂到了网上,具有一定傻瓜式智能,欢迎体验使用拍砖:http://www.zhentiyuan.com/Games/QuickFiveChess.aspx 现 ...
- iOS猜拳游戏源码
利用核心动画和Quartz2D做的一个小游戏.逻辑十分简单. 源码下载:http://code.662p.com/<ignore_js_op> 详细说明:http://ios.662p.c ...
- 保密安全风险自评估单机版检查工具V1.0
下载链接:http://download.csdn.net/download/moremoretea1983/10273128
- elasticsearch httpclient认证机制
最近公司单位搬迁,所有的服务都停止了,我负责的elasticsearch不知道怎么回事,一直不能运行呢,因此,我一直在负责调试工作.经过两天的调试工作,我发现新的服务器增加了httpclient认证机 ...
- 错误: 代理抛出异常错误: java.rmi.server.ExportException: Port already in use: 1099; nested exception is: java.net.BindException: Address already in use: JVM_Bind
在使用SpringMVC测试的时候, 遇到了这样一个问题, 说的是端口已经被使用了. 代理抛出异常错误: java.rmi.server.ExportException: Port already i ...