使用bs4中的方法爬取星巴克数据
import urllib.request # 请求url
url = 'https://www.starbucks.com.cn/menu/' # 模拟浏览器发出请求
response = urllib.request.urlopen(url) # 获取响应数据(read读方法返回字节形式二进制数据.decode解码)
content = response.read().decode('utf-8') from bs4 import BeautifulSoup # 服务器响应的文件生成对象
soup = BeautifulSoup(content,'lxml')
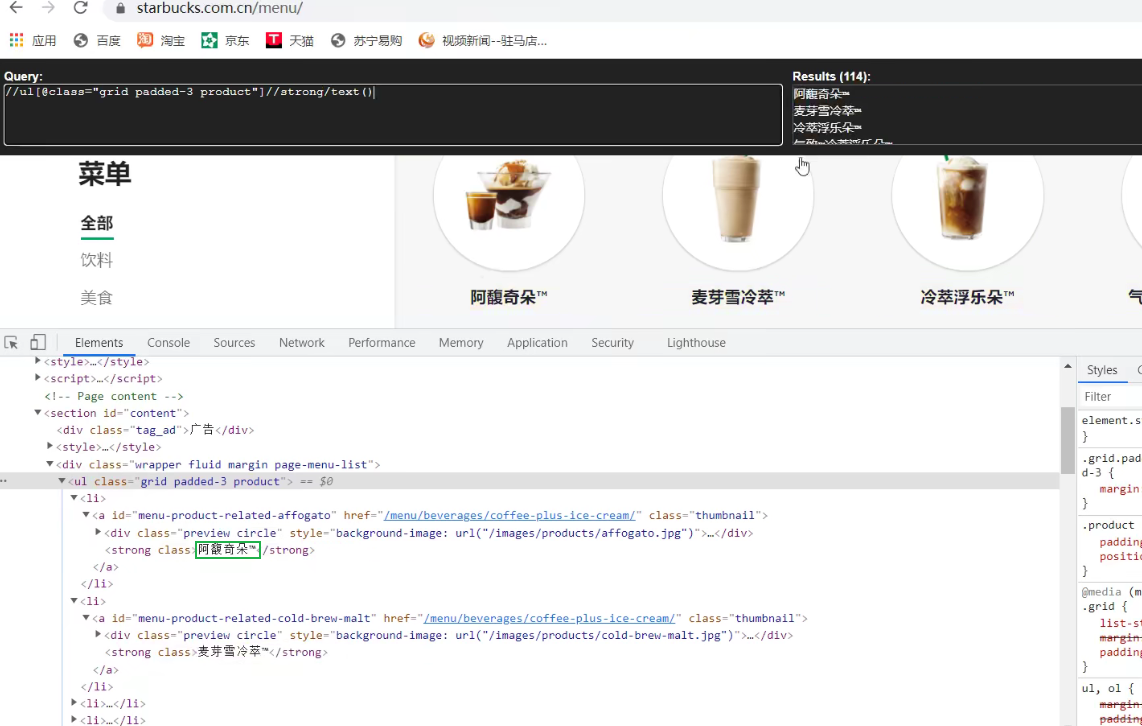
# //ul[@class="grid padded-3 product"]//strong/text()
# 返回一个,ul的class="grid padded-3 product" 的后代 所有strong标签
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())

使用bs4中的方法爬取星巴克数据的更多相关文章
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- node 爬虫 --- 将爬取到的数据,保存到 mysql 数据库中
步骤一:安装必要模块 (1)cheerio模块 ,一个类似jQuery的选择器模块,分析HTML利器. (2)request模块,让http请求变的更加简单 (3)mysql模块,node连接mysq ...
- nodejs中使用cheerio爬取并解析html网页
nodejs中使用cheerio爬取并解析html网页 转 https://www.jianshu.com/p/8e4a83e7c376 cheerio用于node环境,用法与语法都类似于jquery ...
- 简单又强大的pandas爬虫 利用pandas库的read_html()方法爬取网页表格型数据
文章目录 一.简介 二.原理 三.爬取实战 实例1 实例2 一.简介 一般的爬虫套路无非是发送请求.获取响应.解析网页.提取数据.保存数据等步骤.构造请求主要用到requests库,定位提取数据用的比 ...
- python爬虫25 | 爬取下来的数据怎么保存? CSV 了解一下
大家好 我是小帅b 是一个练习时长两年半的练习生 喜欢 唱! 跳! rap! 篮球! 敲代码! 装逼! 不好意思 我又走错片场了 接下来的几篇文章 小帅b将告诉你 如何将你爬取到的数据保存下来 有文本 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- 吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB
本博文使用的数据库是MySQL和MongoDB数据库.安装MySQL可以参照我的这篇博文:https://www.cnblogs.com/tszr/p/12112777.html 其中操作Mysql使 ...
- Java爬取同花顺股票数据(附源码)
最近有小伙伴问我能不能抓取同花顺的数据,最近股票行情还不错,想把数据抓下来自己分析分析.我大A股,大家都知道的,一个概念火了,相应的股票就都大涨. 如果能及时获取股票涨跌信息,那就能在刚开始火起来的时 ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
随机推荐
- JDK源码阅读(4):HashMap类阅读笔记
HashMap public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, ...
- node-pre-gyp以及node-gyp的源码简单解析(以安装sqlite3为例)
title: node-pre-gyp以及node-gyp的源码简单解析(以安装sqlite3为例) date: 2020-11-27 tags: node native sqlite3 前言 简单来 ...
- 第30篇-main()方法的执行
在第7篇详细介绍过为Java方法创建的栈帧,如下图所示. 调用完generate_fixed_frame()函数后一些寄存器中保存的值如下: rbx:Method* ecx:invocation co ...
- vue 动态菜单以及动态路由加载、刷新采的坑
需求: 从接口动态获取子菜单数据 动态加载 要求只有展开才加载子菜单数据 支持刷新,页面显示正常 思路: 一开始比较乱,思路很多.想了很多 首先路由和菜单共用一个全局route, 数据的传递也是通过s ...
- bzoj5210最大连通子块和 (动态dp+卡常好题)
卡了一晚上,经历了被卡空间,被卡T,被卡数组等一堆惨惨的事情之后,终于在各位大爹的帮助下过了这个题qwqqq (全网都没有用矩阵转移的动态dp,让我很慌张) 首先,我们先考虑一个比较基础的\(dp\) ...
- python socket zmq
本篇博客将介绍zmq应答模式,所谓应答模式,就是一问一答,规则有这么几条 1. 必须先提问,后回答 2. 对于一个提问,只能回答一次 3. 在没有收到回答前不能再次提问 上代码,服务端: #codin ...
- 全连接层dense作用
参考来源
- [Beta]the Agiles Scrum Meeting 12
会议时间:2020.5.27 21:00 1.每个人的工作 今天已完成的工作 成员 已完成的工作 issue yjy 帮助解决技术问题 tq 撰写技术博客 wjx 博客评分界面美化 dzx 博客评分界 ...
- 大闸蟹的项目分析——CSDN APP
大闸蟹的软件案例分析 项目 内容 这个作业属于那个课程 班级博客 这个作业的要求在哪里 作业要求 我在这个课程的目标是 学习软件工程的相关知识 这个作业在哪个具体方面帮我实现目标 从多角度分析软件 一 ...
- 设置nginx进程可打开最大的文件数
涉及到的nginx配置参数: worker_processes: 表示操作系统启动多少个工作进程在运行,一般这个参数设置成CPU核数的倍数 worker_connections:表示nginx的工作进 ...