HIVE优化学习笔记
概述
之前写过关于hive的已经有两篇随笔了,但是作者依然还是一枚小白,现在把那些杂七杂八的总结一下,供以后查阅和总结。今天的文章介绍一下hive的优化。hive是好多公司都在使用的东西,也有好多大公司进行定制化二次优化,比如鹅厂的Thive等。所以学习hive至关重要,本文只针对大众版免费开源的hive。官网地址:http://hive.apache.org/。
HIVE的特征
Hive是一个构建在Hadoop之上的数据仓库软件,它可以使已经存储的数据结构化,它提供类似sql的查询语句HiveQL对数据进行分析处理。 Hive将HiveQL语句转换成一系列成MapReduce作业并执行(SQL转化为MapReduce的过程你知道吗?)。用户可以很方便的使用命令行和JDBC程序的方式来连接到hive。 目前,Hive除了支持MapReduce计算引擎,还支持Spark和Tez这两中分布式计算引擎(Tez之前介绍过详见:HIVE执行引擎TEZ学习以及实际使用)。他们常用于离线批处理。
1.可通过SQL轻松访问数据的工具,从而实现数据仓库任务,如提取/转换/加载(ETL),报告和数据分析。
2.它可以使已经存储的数据结构化。
3.可以直接访问存储在Apache HDFS或其他数据存储系统(如Apache HBase)中的文件
4. 数据的存储格式有多种,比如数据源是二进制格式, 普通文本格式等等。
而hive强大之处不要求数据转换成特定的格式,而是利用hadoop本身InputFormat API来从不同的数据源读取数据,同样地使用OutputFormat API将数据写成不同的格式。所以对于不同的数据源,或者写出不同的格式就需要不同的对应的InputFormat和Outputformat类的实现。
以stored as textfile为例,其在底层java API中表现是输入InputFormat格式:TextInputFormat以及输出OutputFormat格式:HiveIgnoreKeyTextOutputFormat.这里InputFormat中定义了如何对数据源文本进行读取划分,以及如何将切片分割成记录存入表中。而Outputformat定义了如何将这些切片写回到文件里或者直接在控制台输出。
不仅如此hive的sql还可以通过用户定义的函数(UDF),用户定义的聚合(UDAF)和用户定义的表函数(UDTF)进行扩展。(几个函数之间的区别)Hive中不仅可以使用逗号和制表符分割值(CSV/TSV)文版文件,还可以使用SequenceFile、RC、ORC、Parquet(知道这几种存储格式的区别),当然Hive还可以通过用户来自定义自己的存储格式,基本上前面说的到的几种格式完全够了。Hive意在最大先读的提高可伸缩性(通过向Hadoop集群动态添加更多机器扩展),性能,可扩展性,容错性以及其输入格式的松散耦合。
HIVE必须面对的问题
总的来说hive是拥有hadoop计算框架的特性的,根据以上的特性,他也会衍生如下的几个问题:
数据量大不是问题,数据倾斜是个问题。
jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,耗时很长。原因是map reduce作业初始化的时间是比较长的。
sum,count,max,min等UDAF,不怕数据倾斜问题,hadoop在map端的汇总合并优化,使数据倾斜不成问题。
count(distinct ),在数据量大的情况下,效率较低,如果是多count(distinct )效率更低,因为count(distinct)是按group by 字段分组,按distinct字段排序,一般这种分布方式是很倾斜的。举个例子:比如男uv,女uv,像淘宝一天30亿的pv,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
面对这些问题,我们能有哪些有效的优化手段呢?下面列出一些在工作有效可行的优化手段:
好的模型设计事半功倍。
解决数据倾斜问题。
减少job数。
设置合理的map reduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够)。
了解数据分布,自己动手解决数据倾斜问题是个不错的选择。set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化有时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜问题。
数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题。
对小文件进行合并,是行至有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的正向影响。
优化时把握整体,单个作业最优不如整体最优。
而接下来,我们心中应该会有一些疑问,影响性能的根源是什么?
hive性能优化时,把HiveQL当做M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
RAC(Real Application Cluster)真正应用集群就像一辆机动灵活的小货车,响应快;Hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好Hadoop的首要任务是增大每次任务所搭载的数据量。
Hadoop的核心能力是parition和sort,因而这也是优化的根本。
观察Hadoop处理数据的过程,有几个显著的特征:
数据的大规模并不是负载重点,造成运行压力过大是因为运行数据的倾斜。
数据倾斜是导致效率大幅降低的主要原因,可以采用多一次 Map/Reduce 的方法, 避免倾斜。
最后得出的结论是:避实就虚,用 job 数的增加,输入量的增加,占用更多存储空间,充分利用空闲 CPU 等各种方法,分解数据倾斜造成的负担。
配置角度优化
我们知道了性能低下的根源,同样,我们也可以从Hive的配置解读去优化。Hive系统内部已针对不同的查询预设定了优化方法,用户可以通过调整配置进行控制, 以下举例介绍部分优化的策略以及优化控制选项。
列裁剪
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。 例如,若有以下查询:
SELECT a,b FROM q WHERE e<10;
在实施此项查询中,Q 表有 5 列(a,b,c,d,e),Hive 只读取查询逻辑中真实需要 的 3 列 a、b、e,而忽略列 c,d;这样做节省了读取开销,中间表存储开销和数据整合开销。裁剪所对应的参数项为:hive.optimize.cp=true(默认值为真)。
分区裁剪
可以在查询的过程中减少不必要的分区。 例如,若有以下查询:
1 SELECT * FROM (SELECTT a1,COUNT(1) FROM T GROUP BY a1) subq WHERE subq.prtn=100; #(多余分区)
2 SELECT * FROM T1 JOIN (SELECT * FROM T2) subq ON (T1.a1=subq.a2) WHERE subq.prtn=100;
查询语句若将“subq.prtn=100”条件放入子查询中更为高效,可以减少读入的分区 数目。 Hive 自动执行这种裁剪优化。分区参数为:hive.optimize.pruner=true(默认值为真)。
JOIN操作
在编写带有 join 操作的代码语句时,应该将条目少的表/子查询放在 Join 操作符的左边。 因为在 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,载入条目较少的表 可以有效减少 OOM(out of memory)即内存溢出。所以对于同一个 key 来说,对应的 value 值小的放前,大的放后,这便是“小表放前”原则。 若一条语句中有多个 Join,依据 Join 的条件相同与否,有不同的处理方法。
JOIN原则
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询。
1 INSERT OVERWRITE TABLE pv_users
2 SELECT pv.pageid, u.age FROM page_view p
3 JOIN user u ON (pv.userid = u.userid)
4 JOIN newuser x ON (u.userid = x.userid);
如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce
一个 Map-Reduce 任务,而不是 ‘n’ 个
在做 OUTER JOIN 的时候也是一样
如果 Join 的条件不相同,比如:
1 INSERT OVERWRITE TABLE pv_users
2 SELECT pv.pageid, u.age FROM page_view p
3 JOIN user u ON (pv.userid = u.userid)
4 JOIN newuser x on (u.age = x.age);
Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的:
1 INSERT OVERWRITE TABLE tmptable
2 SELECT * FROM page_view p JOIN user u
3 ON (pv.userid = u.userid);
4 INSERT OVERWRITE TABLE pv_users
5 SELECT x.pageid, x.age FROM tmptable x
6 JOIN newuser y ON (x.age = y.age);
MAP JOIN操作
Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。比如查询:
在使用mapjoin中需要注意一下版本差异:
在Hive0.11前,必须使用MAPJOIN来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小
1 INSERT OVERWRITE TABLE pv_users
2 SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
3 FROM page_view pv
4 JOIN user u ON (pv.userid = u.userid);
在Hive0.11后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin,可以通过以下两个属性来设置该优化的触发时机
hive.auto.convert.join
默认值为true,自动开户MAPJOIN优化
hive.mapjoin.smalltable.filesize
默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中
注意:使用默认启动该优化的方式如果出现默名奇妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化
hive.auto.convert.join=false(关闭自动MAPJOIN转换操作)
hive.ignore.mapjoin.hint=false(不忽略MAPJOIN标记)
对于以下查询是不支持使用方法二(MAPJOIN标记)来启动该优化的
1 select/*+MAPJOIN(smallTableTwo)*/idOne, idTwo, valueFROM ( select/*+MAPJOIN(smallTableOne)*/idOne, idTwo, valueFROM bigTable JOINsmallTableOneon(bigTable.idOne= smallTableOne.idOne)
2 ) firstjoin
3 JOIN
4 smallTableTwo ON(firstjoin.idTwo=smallTableTwo.idTwo)
但是,如果使用的是方法一即没有MAPJOIN标记则以上查询语句将会被作为两个MJ执行,进一步的,如果预先知道表大小是能够被加载进内存的,则可以通过以下属性来将两个MJ合并成一个MJ
hive.auto.convert.join.noconditionaltask:Hive在基于输入文件大小的前提下将普通JOIN转换成MapJoin,并是否将多个MJ合并成一个
hive.auto.convert.join.noconditionaltask.size:多个MJ合并成一个MJ时,其表的总的大小须小于该值,同时hive.auto.convert.join.noconditionaltask必须为true。
可以在 Map 阶段完成 Join,如图所示:
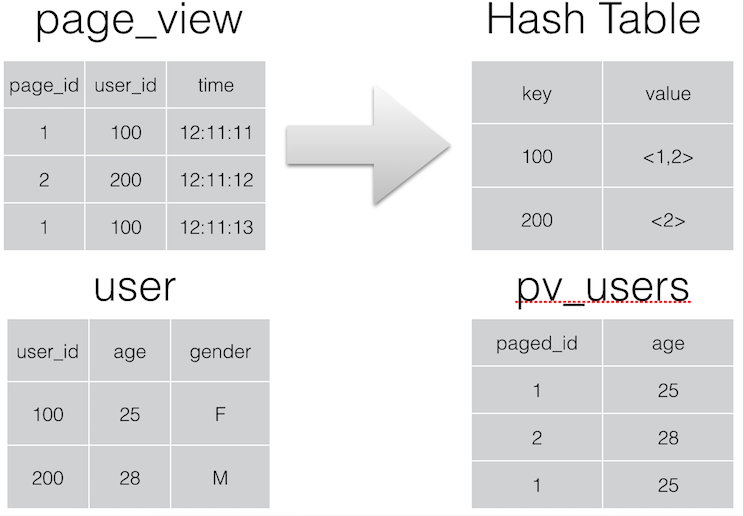
相关的参数为:
hive.join.emit.interval = 1000
hive.mapjoin.size.key = 10000
hive.mapjoin.cache.numrows = 10000
GROUP BY操作
进行GROUP BY操作时需要注意一下几点:
Map端部分聚合
事实上并不是所有的聚合操作都需要在reduce部分进行,很多聚合操作都可以先在Map端进行部分聚合,然后reduce端得出最终结果。
这里需要修改的参数为:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真) hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
有数据倾斜时进行负载均衡
此处需要设定 hive.groupby.skewindata,当选项设定为 true 是,生成的查询计划有两 个 MapReduce 任务。在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可 能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处 理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
用于设置合并属性的参数有:
是否合并Map输出文件:hive.merge.mapfiles=true(默认值为真)
是否合并Reduce 端输出文件:hive.merge.mapredfiles=false(默认值为假)
合并文件的大小:hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
程序角度优化
熟练使用SQL提高查询
熟练地使用 SQL,能写出高效率的查询语句。
场景:有一张 user 表,为卖家每天收到表,user_id,ds(日期)为 key,属性有主营类目,指标有交易金额,交易笔数。每天要取前10天的总收入,总笔数,和最近一天的主营类目。
解决方法 1。如下所示:常用方法
1 INSERT OVERWRITE TABLE t1
2 SELECT user_id,substr(MAX(CONCAT(ds,cat),9) AS main_cat) FROM users
3 WHERE ds=20120329 // 20120329 为日期列的值,实际代码中可以用函数表示出当天日期 GROUP BY user_id;
4
5 INSERT OVERWRITE TABLE t2
6 SELECT user_id,sum(qty) AS qty,SUM(amt) AS amt FROM users
7 WHERE ds BETWEEN 20120301 AND 20120329
8 GROUP BY user_id
9
10 SELECT t1.user_id,t1.main_cat,t2.qty,t2.amt FROM t1
11 JOIN t2 ON t1.user_id=t2.user_id
下面给出方法1的思路,实现步骤如下:
第一步:利用分析函数,取每个 user_id 最近一天的主营类目,存入临时表 t1。
第二步:汇总 10 天的总交易金额,交易笔数,存入临时表 t2。
第三步:关联 t1,t2,得到最终的结果。
解决方法2:
如下所示:优化方法
1 SELECT user_id,substr(MAX(CONCAT(ds,cat)),9) AS main_cat,SUM(qty),SUM(amt) FROM users
2 WHERE ds BETWEEN 20120301 AND 20120329
3 GROUP BY user_id
在工作中我们总结出:方案 2 的开销等于方案 1 的第二步的开销,性能提升,由原有的 25 分钟完成,缩短为 10 分钟以内完成。节省了两个临时表的读写是一个关键原因,这种方式也适用于 Oracle 中的数据查找工作。SQL 具有普适性,很多 SQL 通用的优化方案在 Hadoop 分布式计算方式中也可以达到效果。
无效ID在关联时的数据倾斜问题
问题:日志中常会出现信息丢失,比如每日约为 20 亿的全网日志,其中的 user_id 为主 键,在日志收集过程中会丢失,出现主键为 null 的情况,如果取其中的 user_id 和 bmw_users 关联,就会碰到数据倾斜的问题。原因是 Hive 中,主键为 null 值的项会被当做相同的 Key 而分配进同一个计算 Map。
解决方法 1:user_id 为空的不参与关联,子查询过滤 null
1 SELECT * FROM log a
2 JOIN bmw_users b ON a.user_id IS NOT NULL AND a.user_id=b.user_id
3 UNION All SELECT * FROM log a WHERE a.user_id IS NULL
解决方法 2 如下所示:函数过滤 null
1 SELECT * FROM log a LEFT OUTER
2 JOIN bmw_users b ON
3 CASE WHEN a.user_id IS NULL THEN CONCAT(‘dp_hive’,RAND()) ELSE a.user_id END =b.user_id;
调优结果:原先由于数据倾斜导致运行时长超过 1 小时,解决方法 1 运行每日平均时长 25 分钟,解决方法 2 运行的每日平均时长在 20 分钟左右。优化效果很明显。
我们在工作中总结出:解决方法2比解决方法1效果更好,不但IO少了,而且作业数也少了。解决方法1中log读取两次,job 数为2。解决方法2中 job 数是1。这个优化适合无效 id(比如-99、 ‘’,null 等)产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的 数据分到不同的Reduce上,从而解决数据倾斜问题。因为空值不参与关联,即使分到不同 的 Reduce 上,也不会影响最终的结果。附上 Hadoop 通用关联的实现方法是:关联通过二次排序实现的,关联的列为 partion key,关联的列和表的 tag 组成排序的 group key,根据 pariton key分配Reduce。同一Reduce内根据group key排序。
不同数据类型关联产生的倾斜问题
问题:不同数据类型 id 的关联会产生数据倾斜问题。
一张表 s8 的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。 s8 的日志中有 32 为字符串商品 id,也有数值商品 id,日志中类型是 string 的,但商品中的 数值 id 是 bigint 的。猜想问题的原因是把 s8 的商品 id 转成数值 id 做 hash 来分配 Reduce, 所以字符串 id 的 s8 日志,都到一个 Reduce 上了,解决的方法验证了这个猜测。
解决方法:把数据类型转换成字符串类型
1 SELECT * FROM s8_log a LEFT OUTER
2 JOIN r_auction_auctions b ON a.auction_id=CAST(b.auction_id AS STRING)
调优结果显示:数据表处理由 1 小时 30 分钟经代码调整后可以在 20 分钟内完成。
利用Hive对UNION ALL优化的特性
多表 union all 会优化成一个 job。
问题:比如推广效果表要和商品表关联,效果表中的 auction_id 列既有 32 为字符串商 品 id,也有数字 id,和商品表关联得到商品的信息。
解决方法:Hive SQL 性能会比较好
1 SELECT * FROM effect a
2 JOIN
3 (SELECT auction_id AS auction_id FROM auctions
4 UNION All
5 SELECT auction_string_id AS auction_id FROM auctions) b
6 ON a.auction_id=b.auction_id
比分别过滤数字 id,字符串 id 然后分别和商品表关联性能要好。
这样写的好处:1 个 MapReduce 作业,商品表只读一次,推广效果表只读取一次。把 这个 SQL 换成 Map/Reduce 代码的话,Map 的时候,把 a 表的记录打上标签 a,商品表记录 每读取一条,打上标签 b,变成两个<key,value>对,<(b,数字 id),value>,<(b,字符串 id),value>。
所以商品表的 HDFS 读取只会是一次。
解决Hive对UNION ALL优化的短板
Hive 对 union all 的优化的特性:对 union all 优化只局限于非嵌套查询。
消灭子查询内的 group by
示例 1:子查询内有 group by
1 SELECT * FROM
2 (SELECT * FROM t1 GROUP BY c1,c2,c3 UNION ALL SELECT * FROM t2 GROUP BY c1,c2,c3)t3
3 GROUP BY c1,c2,c3
从业务逻辑上说,子查询内的 GROUP BY 怎么都看显得多余(功能上的多余,除非有 COUNT(DISTINCT)),如果不是因为 Hive Bug 或者性能上的考量(曾经出现如果不执行子查询 GROUP BY,数据得不到正确的结果的 Hive Bug)。所以这个 Hive 按经验转换成如下所示:
1 SELECT * FROM (SELECT * FROM t1 UNION ALL SELECT * FROM t2)t3 GROUP BY c1,c2,c3
调优结果:经过测试,并未出现 union all 的 Hive Bug,数据是一致的。MapReduce 的 作业数由 3 减少到 1。
t1 相当于一个目录,t2 相当于一个目录,对 Map/Reduce 程序来说,t1,t2 可以作为 Map/Reduce 作业的 mutli inputs。这可以通过一个 Map/Reduce 来解决这个问题。Hadoop 的 计算框架,不怕数据多,就怕作业数多。
但如果换成是其他计算平台如 Oracle,那就不一定了,因为把大的输入拆成两个输入, 分别排序汇总后 merge(假如两个子排序是并行的话),是有可能性能更优的(比如希尔排 序比冒泡排序的性能更优)。
消灭子查询内的 COUNT(DISTINCT),MAX,MIN。
1 SELECT * FROM
2 (SELECT * FROM t1
3 UNION ALL SELECT c1,c2,c3 COUNT(DISTINCT c4) FROM t2 GROUP BY c1,c2,c3) t3
4 GROUP BY c1,c2,c3;
由于子查询里头有 COUNT(DISTINCT)操作,直接去 GROUP BY 将达不到业务目标。这时采用 临时表消灭 COUNT(DISTINCT)作业不但能解决倾斜问题,还能有效减少 jobs。
1 INSERT t4 SELECT c1,c2,c3,c4 FROM t2 GROUP BY c1,c2,c3;
2 SELECT c1,c2,c3,SUM(income),SUM(uv) FROM
3 (SELECT c1,c2,c3,income,0 AS uv FROM t1
4 UNION ALL
5 SELECT c1,c2,c3,0 AS income,1 AS uv FROM t2) t3
6 GROUP BY c1,c2,c3;
job 数是 2,减少一半,而且两次 Map/Reduce 比 COUNT(DISTINCT)效率更高。
调优结果:千万级别的类目表,member 表,与 10 亿级得商品表关联。原先 1963s 的任务经过调整,1152s 即完成。
消灭子查询内的 JOIN
1 SELECT * FROM
2 (SELECT * FROM t1 UNION ALL SELECT * FROM t4 UNION ALL SELECT * FROM t2 JOIN t3 ON t2.id=t3.id) x
3 GROUP BY c1,c2;
上面代码运行会有 5 个 jobs。加入先 JOIN 生存临时表的话 t5,然后 UNION ALL,会变成 2 个 jobs。
1 INSERT OVERWRITE TABLE t5
2 SELECT * FROM t2 JOIN t3 ON t2.id=t3.id;
3 SELECT * FROM (t1 UNION ALL t4 UNION ALL t5);
调优结果显示:针对千万级别的广告位表,由原先 5 个 Job 共 15 分钟,分解为 2 个 job 一个 8-10 分钟,一个3分钟。
GROUP BY替代COUNT(DISTINCT)达到优化效果
计算 uv 的时候,经常会用到 COUNT(DISTINCT),但在数据比较倾斜的时候 COUNT(DISTINCT) 会比较慢。这时可以尝试用 GROUP BY 改写代码计算 uv。
原有代码
1 INSERT OVERWRITE TABLE s_dw_tanx_adzone_uv PARTITION (ds=20120329)
2 SELECT 20120329 AS thedate,adzoneid,COUNT(DISTINCT acookie) AS uv FROM s_ods_log_tanx_pv t WHERE t.ds=20120329 GROUP BY adzoneid
关于COUNT(DISTINCT)的数据倾斜问题不能一概而论,要依情况而定,下面是我测试的一组数据:
测试数据:169857条
1 #统计每日IP
2 CREATE TABLE ip_2014_12_29 AS SELECT COUNT(DISTINCT ip) AS IP FROM logdfs WHERE logdate='2014_12_29';
3 耗时:24.805 seconds
4 #统计每日IP(改造)
5 CREATE TABLE ip_2014_12_29 AS SELECT COUNT(1) AS IP FROM (SELECT DISTINCT ip from logdfs WHERE logdate='2014_12_29') tmp;
6 耗时:46.833 seconds
测试结果表名:明显改造后的语句比之前耗时,这是因为改造后的语句有2个SELECT,多了一个job,这样在数据量小的时候,数据不会存在倾斜问题。
优化常用手段
主要由三个属性来决定:
hive.exec.reducers.bytes.per.reducer #这个参数控制一个job会有多少个reducer来处理,依据的是输入文件的总大小。默认1GB。
hive.exec.reducers.max #这个参数控制最大的reducer的数量, 如果 input / bytes per reduce > max 则会启动这个参数所指定的reduce个数。 这个并不会影响mapre.reduce.tasks参数的设置。默认的max是999。
mapred.reduce.tasks #这个参数如果指定了,hive就不会用它的estimation函数来自动计算reduce的个数,而是用这个参数来启动reducer。默认是-1。
如果reduce太少:如果数据量很大,会导致这个reduce异常的慢,从而导致这个任务不能结束,也有可能会OOM 2、如果reduce太多: 产生的小文件太多,合并起来代价太高,namenode的内存占用也会增大。如果我们不指定mapred.reduce.tasks, hive会自动计算需要多少个reducer。
总结
感谢网络大神的文章:
https://www.cnblogs.com/smartloli/p/4356660.html
https://zhuanlan.zhihu.com/p/62983727
https://zhuanlan.zhihu.com/p/102475087
https://zhuanlan.zhihu.com/p/82859179
https://mp.weixin.qq.com/s/FMVluR-Ux9NQ9lF34tcjWg
https://www.cnblogs.com/smartloli/p/4288493.html
https://www.cnblogs.com/huanghanyu/p/12973836.html
https://www.jianshu.com/p/2370d53054d3
HIVE优化学习笔记的更多相关文章
- KVM性能优化学习笔记
本学习笔记系列都是采用CentOS6.x操作系统,KVM虚拟机的管理也是采用virsh方式,网上的很多的文章都基于ubuntu高版本内核下,KVM的一些新的特性支持更好,本文只是记录了CentOS6. ...
- 深挖计算机基础:Linux性能优化学习笔记
参考极客时间专栏<Linux性能优化实战>学习笔记 一.CPU性能:13讲 Linux性能优化实战学习笔记:第二讲 Linux性能优化实战学习笔记:第三讲 Linux性能优化实战学习笔记: ...
- Pandas 性能优化 学习笔记
摘要 本文介绍了使用 Pandas 进行数据挖掘时常用的加速技巧. 实验环境 import numpy as np import pandas as pd print(np.__version__) ...
- mysql性能优化学习笔记(2)如何发现有问题的sql
一.使用mysql慢查询日志对有效率问题的sql进行监控 1)开启慢查询 show variables like ‘slow_query_log’;//查看是否开启慢查询日志 ...
- hive kettle 学习笔记
学习网址 http://wiki.pentaho.com/display/BAD/Transforming+Data+within+Hive
- 燕十八MySQL优化学习笔记
观察 show status; 里面的这三个参数;Queries Threads_connected Threads_running判断周期性变化 -------------------------- ...
- mysql性能优化学习笔记-参数介绍及优化建议
MySQL服务器参数介绍 mysql参数介绍(客户端中执行),尽量只修改session级别的参数. 全局参数(新连接的session才会生效,原有已经连接的session不生效) set global ...
- mysql性能优化学习笔记
mysql性能优化 硬件对数据库的影响 CPU资源和可用内存大小 服务器硬件对mysql性能的影响 我们的应用是CPU密集型? 我们的应用的并发量如何? 数量比频率更好 64位使用32位的服务器版本 ...
- mysql优化学习笔记
优化sql的一般步骤 通过show status了解各种sql的执行频率 定位执行效率低的sql语句 通过explain分析效率低的sql 通过show profile分析sql 通过trace分析优 ...
随机推荐
- 时间同步——TSN协议802.1AS介绍
前言之前的主题TSN的发展历史和协议族现状介绍了TSN技术的缘起,最近一期的主题TSN协议导读从定时与同步.延时.可靠性.资源管理四个方面,帮助大家了解TSN协议族包含哪些子协议,以及这些子协议的作用 ...
- get_started_3dsctf_2016 1
拿到题目,依旧还是老样子,查看程序开启的保护和位数 可以看到程序开启了nx保护是32位程序,于是我们把程序放入ida32编译一下 一打开就能看到非常明显的get_flag这个程序,f5观察伪代码 当a ...
- BUU | pwnable_orw
题解网上其他师傅已经写过了而且写的很详细,菜鸡只好写一下自己做题中的笔记 Payload : #coding:utf-8 from pwn import * context(log_level = ' ...
- 深入理解java虚拟机(一)
java历史 1996.01.23发布Jdk1.0 1998.12.04发布jdk1.2(里程碑的版本)注意:集合容器Collection和Map都是从1.2开始 1999.04.27HotSpot虚 ...
- Google Earth Engine 批量点击RUN任务,批量取消正在上传的任务
本文内容参考自: https://blog.csdn.net/qq_21567935/article/details/89061114 https://blog.csdn.net/qq_2156793 ...
- 联盛德 HLK-W806 (十二): Makefile组织结构和编译流程说明
目录 联盛德 HLK-W806 (一): Ubuntu20.04下的开发环境配置, 编译和烧录说明 联盛德 HLK-W806 (二): Win10下的开发环境配置, 编译和烧录说明 联盛德 HLK-W ...
- shell脚本报错:.sh: /bin/bash^M: 坏的解释器: 没有那个文件或目录
.sh: /bin/bash^M: 坏的解释器: 没有那个文件或目录 这是因为shell脚本是Windows下编辑的 格式不一样 执行 sed -i 's/\r$//' 脚本名称.sh
- Kafka安装Kafka-Eagle可视化界面
要先安装jdk 可以参考:https://www.cnblogs.com/pxblog/p/10512886.html 下载 http://download.kafka-eagle.org/ 上传到服 ...
- codeforc 603-A. Alternative Thinking(规律)
A. Alternative Thinking time limit per test 2 seconds memory limit per test 256 megabytes Kevin ha ...
- 1108 - Instant View of Big Bang
1108 - Instant View of Big Bang PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limi ...