hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了。在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集、数据上传、数据分析、数据结果读取、数据可视化。
需要用到
Cygwin:一个在windows平台上运行的类UNIX模拟环境,直接网上搜索下载,并且安装;
Hadoop:配置Hadoop环境,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,用来将收集的数据直接上传保存到HDFS,然后用MapReduce分析;
Eclipse:编写代码,需要导入hadoop的jar包,以可以创建MapReduce项目;
Jsoup:html的解析jar包,结合正则表达式能更好的解析网页源码;
----->
目录:
1、配置Cygwin
2、配置Hadoop黄静
3、Eclipse开发环境搭建
4、网络数据爬取(jsoup)
-------->
1、安装配置Cygwin
从官方网站下载Cygwin 安装文件,地址:https://cygwin.com/install.html
下载运行后进入安装界面。
安装时直接从网络镜像中下载扩展包,至少需要选择ssh和ssl支持包
安装后进入cygwin控制台界面,
运行ssh-host-config命令,安装SSH
输入:no,yes,ntsec,no,no
注意:win7下需要改为yes,yes,ntsec,no,yes,输入密码并确认这个步骤
完成后会在windows操作系统中配置好一个Cygwin sshd服务,启动该服务即可。

然后要配置ssh免密码登陆
重新运行cygwin。
执行ssh localhost,会要求使用密码进行登陆。
使用ssh-keygen命令来生成一个ssh密钥,一直回车结束即可。
生成后进入.ssh目录,使用命令:cp id_rsa.pub authorized_keys 命令来配置密钥。
之后使用exit退出即可。
重新进入系统后,通过ssh localhost就可以直接进入系统,不需要再输入密码了。
2、配置Hadoop环境
修改hadoop-env.sh文件,加入JDK安装目录的JAVA_HOME位置设置。
|
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67 |
如图注意:Program Files缩写为PROGRA~1

修改hdfs-site.xml,设置存放副本为1(因为配置的是伪分布式方式)
|
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> |
注意:此图片多加了一个property,内容就是解决可能出现的权限问题!!!
HDFS:Hadoop 分布式文件系统
可以在HDFS中通过命令动态对文件或文件夹进行CRUD
注意有可能出现权限的问题,需要通过在hdfs-site.xml中配置以下内容来避免:
|
<property> <name>dfs.permissions</name> <value>false</value> </property> |

修改mapred-site.xml,设置JobTracker运行的服务器与端口号(由于当前就是运行在本机上,直接写localhost 即可,端口可以绑定任意空闲端口)
|
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration> |
配置core-site.xml,配置HDFS文件系统所对应的服务器与端口号(同样就在当前主机)
|
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> |
配置好以上内容后,在Cygwin中进入hadoop目录

在bin目录下,对HDFS文件系统进行格式化(第一次使用前必须格式化),然后输入启动命令:
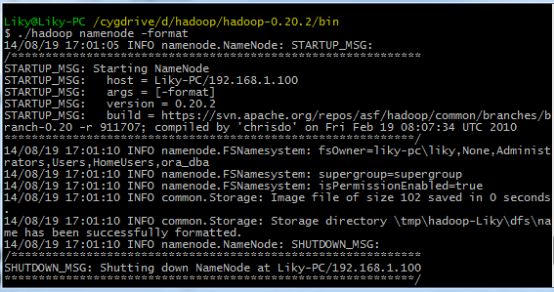
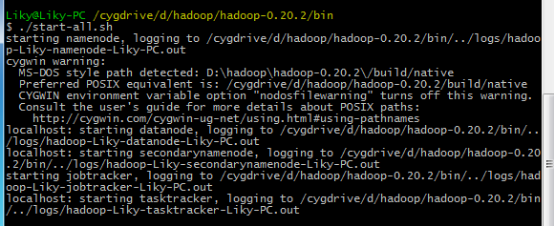
3、Eclipse开发环境搭建
这个在我写的博客 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置) http://www.cnblogs.com/1996swg/p/7286136.html 中给出大致配置方法。不过此时需要完善一下。
将hadoop中的hadoop-eclipse-plugin.jar支持包拷贝到eclipse的plugin目录下,为eclipse添加Hadoop支持。
启动Eclipse后,切换到MapReduce界面。
在windows工具选项选择showviews的others里面查找map/reduce locations。
在Map/Reduce Locations窗口中建立一个Hadoop Location,以便与Hadoop进行关联。


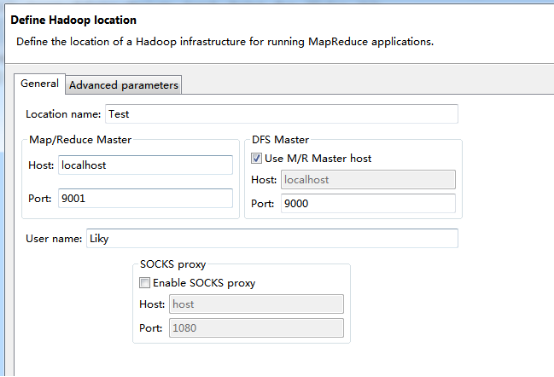
注意:此处的两个端口应为你配置hadoop的时候设置的端口!!!
完成后会建立好一个Hadoop Location
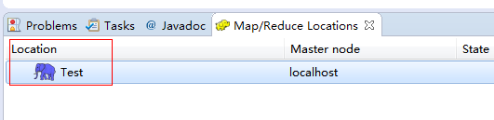
在左侧的DFS Location中,还可以看到HDFS中的各个目录
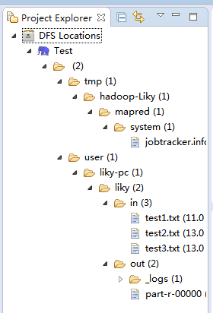
并且你可以在其目录下自由创建文件夹来存取数据。
下面你就可以创建mapreduce项目了,方法同正常创建一样。
4、网络数据爬取
现在我们通过编写一段程序,来将爬取的新闻内容的有效信息保存到HDFS中。
此时就有了两种网络爬虫的方法:其一就是利用heritrix工具获取的数据;
其一就是java代码结合jsoup编写的网络爬虫。
方法一的信息保存到HDFS:
直接读取生成的本地文件,用jsoup解析html,此时需要将jsoup的jar包导入到项目中。
package org.liky.sina.save; //这里用到了JSoup开发包,该包可以很简单的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; public class SinaNewsData { private static Configuration conf = new Configuration(); private static FileSystem fs; private static Path path; private static int count = 0; public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
} public static void parseAllFile(File file) {
// 判断类型
if (file.isDirectory()) {
// 文件夹
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
} public static void parseContent(String filePath) {
try {
//用jsoup的方法读取文件路径
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//读取标题
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first(); // 读取内容
String content = descE.attr("content"); if (title != null && content != null) {
//通过Path来保存数据到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt"); fs = path.getFileSystem(conf); // 建立输出流对象
FSDataOutputStream os = fs.create(path);
// 使用os完成输出
os.writeChars(title + "\r\n" + content); os.close(); count++; System.out.println("已经完成" + count + " 个!");
} } catch (Exception e) {
e.printStackTrace();
}
}
}
hadoop中实现java网络爬虫的更多相关文章
- 基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎 网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并 ...
- Java 网络爬虫获取网页源代码原理及实现
Java 网络爬虫获取网页源代码原理及实现 1.网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL ...
- java网络爬虫基础学习(三)
尝试直接请求URL获取资源 豆瓣电影 https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort= ...
- java网络爬虫基础学习(一)
刚开始接触java爬虫,在这里是搜索网上做一些理论知识的总结 主要参考文章:gitchat 的java 网络爬虫基础入门,好像要付费,也不贵,感觉内容对新手很友好. 一.爬虫介绍 网络爬虫是一个自动提 ...
- 学 Java 网络爬虫,需要哪些基础知识?
说起网络爬虫,大家想起的估计都是 Python ,诚然爬虫已经是 Python 的代名词之一,相比 Java 来说就要逊色不少.有不少人都不知道 Java 可以做网络爬虫,其实 Java 也能做网络爬 ...
- Java 网络爬虫,就是这么的简单
这是 Java 网络爬虫系列文章的第一篇,如果你还不知道 Java 网络爬虫系列文章,请参看 学 Java 网络爬虫,需要哪些基础知识.第一篇是关于 Java 网络爬虫入门内容,在该篇中我们以采集虎扑 ...
- Java网络爬虫笔记
Java网络爬虫笔记 HttpClient来代替浏览器发起请求. select找到的是元素,也就是elements,你想要获取具体某一个属性的值,还是要用attr("")方法.标签 ...
- 简单的Java网络爬虫(获取一个网页中的邮箱)
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; impo ...
- 开源的49款Java 网络爬虫软件
参考地址 搜索引擎 Nutch Nutch 是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. Nutch的创始人是Doug Cutting, ...
随机推荐
- (转)percona的安装、启动、停止
原文:https://blog.csdn.net/tanliqing2010/article/details/78758878 socket=/percona/3307/data/mysql.sock ...
- pigz 压缩
压缩工具--pigz 压缩: tar cvf - 目录名 | pigz -9 -p 24 > file.tgz pigz:用法-9是压缩比率比较大,-p是指定cpu的核数. 解压: pigz - ...
- 【从0到1学Web前端】javascript中的ajax对象(一) 分类: JavaScript 2015-06-24 10:18 754人阅读 评论(1) 收藏
现在最流行的获取后端的(浏览器从服务器)数据的方式就是通过Ajax了吧.今天就来详细的来学习下这个知识吧.如果使用ajax来访问后段的数据,浏览器和浏览器端的js做了那些工作呢?我做了一个图,请大家看 ...
- 25-hadoop-hive-函数
内置函数: 函数分类: 内置函数查看: show funcitons; 查看函数描述: DESC FUNCTION concat; 具体见: https://cwiki.apache.org/conf ...
- 管理git生成的多个ssh key
http://www.bootcss.com/p/git-guide/ 问题阐述 当有多个git账号的时候,比如一个github,用于自己进行一些开发活动,再来一个gitlab,一般是公司内部的git ...
- 自制 Chrome Custom.css 设置网页字体为微软雅黑扩展
自己做的將網頁自動替換為微軟雅黑的擴展.很好用. 將Customcss.rcx拖到擴展裏就可. 下載:Customcss.zip
- Silverlight 在ie8 下 报2152 错误
前几天改别人的一个silverlight程序,在项目属性上 选中了 “通过使用应用程序库缓存减小XAP 大小”,编译无错,发布无错误. 放服务器上测试: 站点绑定域名,使用ie9.ie10 都没有问题 ...
- 手把手教你实现自己的abp代码生成器
代码生成器的原理无非就是得到字段相关信息(字段名,字段类型,字段注释等),然后根据模板,其实就是字符串的拼接与替换生成相应代码. 所以第一步我们需要解决如何得到字段的相关信息,有两种方式 通过反射获得 ...
- XML反序列化出错,XML 文档(2, 2)中有错误
XML转换为实体类的错误处理方案 一.错误描述: XML反序列化出错,XML 文档(2, 2)中有错误 二.解决方案: 在实体类的字段要加上XmlElement属性 三.具体实现: 1.XML文档 & ...
- maven国内aliyun镜像
打开maven安装目录下conf文件夹的settings.xml文件 配置本地仓库 <localRepository>D:/maven/repository</localReposi ...