CS229 6.9 Neurons Networks softmax regression
SoftMax回归模型,是logistic回归在多分类问题的推广,即现在logistic回归数据中的标签y不止有0-1两个值,而是可以取k个值,softmax回归对诸如MNIST手写识别库等分类很有用,该问题有0-9 这10个数字,softmax是一种supervised learning方法。
在logistic中,训练集由 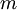 个已标记的样本构成:
个已标记的样本构成: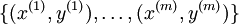 ,其中输入特征
,其中输入特征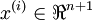 (特征向量
(特征向量  的维度为
的维度为 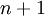 ,其中
,其中 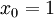 对应截距项 ), logistic 回归是针对二分类问题的,因此类标记
对应截距项 ), logistic 回归是针对二分类问题的,因此类标记 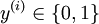 。假设函数(hypothesis function) 如下:
。假设函数(hypothesis function) 如下:
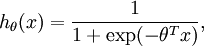
损失函数为负log损失函数:
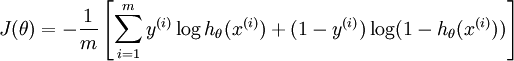
找到使得损失函数最小时的模型参数  ,带入假设函数即可求解模型。
,带入假设函数即可求解模型。
在softmax回归中,对于训练集 中的类标  可以取
可以取  个不同的值(而不是 2 个),即有
个不同的值(而不是 2 个),即有 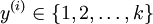 (注意不是由0开始), 在MNIST中有K=10个类别。
(注意不是由0开始), 在MNIST中有K=10个类别。
在softmax回归中,对于输入x,要计算x分别属于每个类别j的概率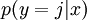 ,即求得x分别属于每一类的概率,因此假设函数要设定为输出一个k维向量,每个维度代表x被分为每个类别的概率,假设函数
,即求得x分别属于每一类的概率,因此假设函数要设定为输出一个k维向量,每个维度代表x被分为每个类别的概率,假设函数 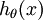 形式如下:
形式如下:
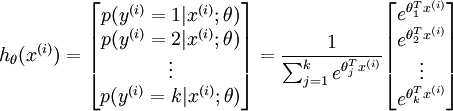
请注意 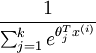 这一项对概率分布进行归一化,使得所有概率之和为 1 。当类别数
这一项对概率分布进行归一化,使得所有概率之和为 1 。当类别数 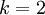 时,softmax 回归退化为 logistic 回归。这表明 softmax 回归是 logistic 回归的一般形式。具体地说,当 时,softmax 回归的假设函数为:
时,softmax 回归退化为 logistic 回归。这表明 softmax 回归是 logistic 回归的一般形式。具体地说,当 时,softmax 回归的假设函数为: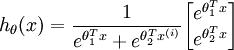 ,对该式进行化简得到:
,对该式进行化简得到:
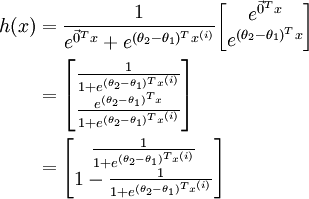
另 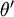 来表示
来表示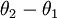 ,我们就会发现 softmax 回归器预测其中一个类别的概率为
,我们就会发现 softmax 回归器预测其中一个类别的概率为 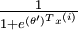 ,另一个类别概率的为
,另一个类别概率的为  ,这与 logistic回归是一致的。
,这与 logistic回归是一致的。
其中 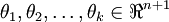 是模型的参数。把参数 表示为矩阵形式有, 是一个
是模型的参数。把参数 表示为矩阵形式有, 是一个 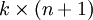 的矩阵,该矩阵是将
的矩阵,该矩阵是将 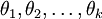 按行罗列起来得到的:
按行罗列起来得到的:
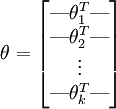
有个假设函数(Hypothesis Function),下面来看代价函数,根据代价函数求解出最优参数值带入假设函数即可求得最终的模型,先引入函数 ,对于该函数有:
,对于该函数有:
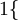 值为真的表达式
值为真的表达式 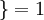 值为假的表达式
值为假的表达式 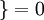 。
。
举例来说,表达式 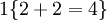 的值为1 ,
的值为1 ,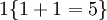 的值为 0 。
的值为 0 。
则softmax的损失函数为:
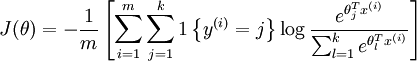
当k=2时,即有logistic的形式,下边是推倒:

另上式中的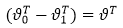 便得到了logistic回归的损失函数。
便得到了logistic回归的损失函数。
可以看到,softmax与logistic的损失函数只是k的取值不同而已,且在softmax中将类别x归为类别j的概率为:
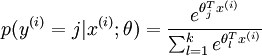 .
.
需要注意的一个问题是softmax回归中的模型参数化问题,即softmax的参数集是“冗余的”。
假设从参数向量 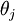 中减去了向量
中减去了向量 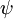 ,这时,每一个 都变成了
,这时,每一个 都变成了 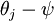 (
(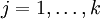 )。此时假设函数变成了以下的式子:
)。此时假设函数变成了以下的式子:
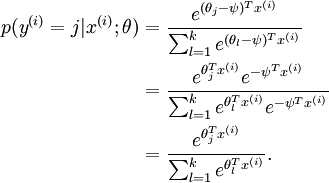
也就是说,从 中减去 完全不影响假设函数的预测结果,这就说明 Softmax 模型被过度参数化了。对于任意一个用于拟合数据的假设函数,可以求出多组参数值,这些参数得到的是完全相同的假设函数 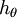 ,也就是说如果参数集合
,也就是说如果参数集合 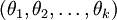 是代价函数
是代价函数  的极小值点,那么
的极小值点,那么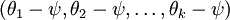 同样也是它的极小值点,其中 可以是任意向量,到底是什么造成的呢?从宏观上可以这么理解,因为此时的损失函数不是严格非凸的,也就是说在局部最小值点附近是一个”平坦”的,所以在这个参数附近的值都是一样的了。平坦假设函数空间的Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题。因此使 最小化的解不是唯一的。但此时 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。
同样也是它的极小值点,其中 可以是任意向量,到底是什么造成的呢?从宏观上可以这么理解,因为此时的损失函数不是严格非凸的,也就是说在局部最小值点附近是一个”平坦”的,所以在这个参数附近的值都是一样的了。平坦假设函数空间的Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题。因此使 最小化的解不是唯一的。但此时 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。
还有一个值得注意的地方是:当 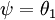 时,我们总是可以将
时,我们总是可以将 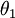 替换为
替换为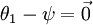 (即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的 个参数 (其中
(即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的 个参数 (其中 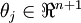 ),我们可以令
),我们可以令 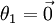 ,只优化剩余的
,只优化剩余的 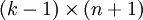 个参数,这样算法依然能够正常工作。比如logistic就是这样的。
个参数,这样算法依然能够正常工作。比如logistic就是这样的。
在实际应用中,为了使算法看起来更直观更清楚,往往保留所有参数 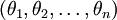 ,而不任意地将某一参数设置为 0。但此时需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
,而不任意地将某一参数设置为 0。但此时需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
目前对损失函数 的最小化还没有封闭解(closed-form),因此使用迭代的方法求解,如(Gradient Descent或者L-BFGS),经过求导,得到的梯度公式:
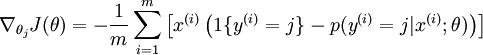
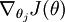 本身是一个向量,它的第
本身是一个向量,它的第  个元素
个元素 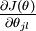 是 对 的第 个分量的偏导数。在梯度下降法的标准实现中,每一次迭代需要进行如下更新:
是 对 的第 个分量的偏导数。在梯度下降法的标准实现中,每一次迭代需要进行如下更新:  ()。( 为方向,a代表在这个方向的步长)
()。( 为方向,a代表在这个方向的步长)
由于参数数量的庞大,所以可能需要权重衰减项来防止过拟合,一般的算法中都会有该项。添加一个权重衰减项 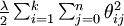 来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
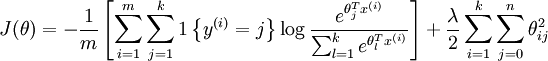
有了这个权重衰减项以后 (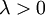 ),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
为了使用优化算法,我们需要求得这个新函数 的导数,如下:
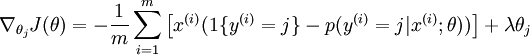
通过最小化 ,我们就能实现一个可用的 softmax 回归模型。
最后一个问题在logistic的文章里提到过,关于分类器选择的问题,是使用logistic建立k个分类器呢,还是直接使用softmax回归,这取决于数据之间是否是互斥的,k-logistic算法可以解决互斥问题,而softmax不可以解决,比如将图像分到三个不同类别中。(i) 假设这三个类别分别是:室内场景、户外城区场景、户外荒野场景。 (ii) 现在假设这三个类别分别是室内场景、黑白图片、包含人物的图片
考虑到处理的问题的不同,在第一个例子中,三个类别是互斥的,因此更适于选择softmax回归分类器 。而在第二个例子中,建立三个独立的 logistic回归分类器更加合适。最后补一张k-logistic的图片:

CS229 6.9 Neurons Networks softmax regression的更多相关文章
- (六)6.9 Neurons Networks softmax regression
SoftMax回归模型,是logistic回归在多分类问题的推广,即现在logistic回归数据中的标签y不止有0-1两个值,而是可以取k个值,softmax回归对诸如MNIST手写识别库等分类很有用 ...
- CS229 6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- CS229 6.13 Neurons Networks Implements of stack autoencoder
对于加深网络层数带来的问题,(gradient diffuse 局部最优等)可以使用逐层预训练(pre-training)的方法来避免 Stack-Autoencoder是一种逐层贪婪(Greedy ...
- CS229 6.11 Neurons Networks implements of self-taught learning
在machine learning领域,更多的数据往往强于更优秀的算法,然而现实中的情况是一般人无法获取大量的已标注数据,这时候可以通过无监督方法获取大量的未标注数据,自学习( self-taught ...
- CS229 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
- CS229 6.17 Neurons Networks convolutional neural network(cnn)
之前所讲的图像处理都是小 patchs ,比如28*28或者36*36之类,考虑如下情形,对于一副1000*1000的图像,即106,当隐层也有106节点时,那么W(1)的数量将达到1012级别,为了 ...
- CS229 6.15 Neurons Networks Deep Belief Networks
Hintion老爷子在06年的science上的论文里阐述了 RBMs 可以堆叠起来并且通过逐层贪婪的方式来训练,这种网络被称作Deep Belife Networks(DBN),DBN是一种可以学习 ...
- CS229 6.12 Neurons Networks from self-taught learning to deep network
self-taught learning 在特征提取方面完全是用的无监督的方法,对于有标记的数据,可以结合有监督学习来对上述方法得到的参数进行微调,从而得到一个更加准确的参数a. 在self-taug ...
- CS229 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法.大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层 ...
随机推荐
- python之路---12 生成器 推导式
三十.函数进阶 1.生成器 函数中有yield 的就是生成器函数(替代了return) 本质就是迭代器 一个一个的创建对象 节省内存 ①创建生成器 最后以yield结束 ...
- [转]总结@Autowired 和@Resource
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按byName自动注入罢了. @Resource有两个属性是比较重要的,分 ...
- Day 02 编程语言介绍及运行python
一.编程语言介绍 1.1.机器语言:直接用计算机能理解的二进制指令编写程序,直接控制硬件. 1.2.汇编语言:用英文标签取代二进制指令编写程序,本质也是在直接控制硬件. 1.3.高级语言:用人能理解的 ...
- JMeter ----与WebDriver安装与测试
JMeter ----与WebDriver安装与测试 主要内容 JMeter安装 WebDriver安装 一个简单的JMeter+WebDriver示例 环境与参考 jvm版本: 1.8.0_65 j ...
- 本地开发spark代码上传spark集群服务并运行
打包 :右击.export.Java .jar File 把TestSpark.jar包上传到spark集群服务器的 spark_home下的myApp下: 提交spark任务: cd /usr/lo ...
- java (图片转PDF)
1.导入jar包 itextpdf-5.5.12.jar 2.写代码 package com.util; import java.io.File; import java.io.FileNotFoun ...
- 协程与多路io复用epool关系
linux上其实底层都基于libevent.so模块实现的,所以本质一样 gevent更关注于io和其它 epool只是遇到io就切换,而gevent其它等待也切换
- Cygwin使用3-修改Cygwin的默认启动路径
原先启动Cygwin后,pwd显示: C:\Documents and Settings\Administrator@IBM-EBDC0EAC4B7 ~$ pwdC:\Documents and Se ...
- 使用R语言-计算均值,方差等
R语言对于数值计算很方便,最近用到了计算方差,标准差的功能,特记录. 数据准备 height <- c(6.00, 5.92, 5.58, 5.92) 1 计算均值 mean(height) [ ...
- Python实现简单的网页抓取
现在开源的网页抓取程序有很多,各种语言应有尽有. 这里分享一下Python从零开始的网页抓取过程 第一步:安装Python 点击下载适合的版本https://www.python.org/ 我这里选择 ...