群辉6.1.7安装scrapy框架执行爬虫
只针对会linux命令,会python的伙伴,
使用环境为:
群辉ds3615xs 6.1.7
python3.5
最近使用scrapy开发了一个小爬虫,因为很穷没有服务器可已部署。
所以打起了我那台千辛万苦攒出来的群辉的主意。以前折腾的时候发现群辉6.1.7基于linux64位系统实现的。
既然是linux系统就应该可以装python。开始我的折腾之路。
刚开始直接ssh远程上去后想apt-get install 方法安装python的,结果发现根本就没有apt-get命令。
后来又试过官网下载pthon3.6源码进行安装,发现没有编译环境。
不过群辉的好处就是第三方套件很多。
以下命令的路径都是基于本人真实路径,请根据实际情况修改
1.添加第三方套件源 http://packages.synocommunity.com/
安装第三方的python3(官方也提供了一个python3,但是我没用,也不知道是为什么,为什么呢,为什么呢,问了自己八百遍。建议不太懂的参考我的)
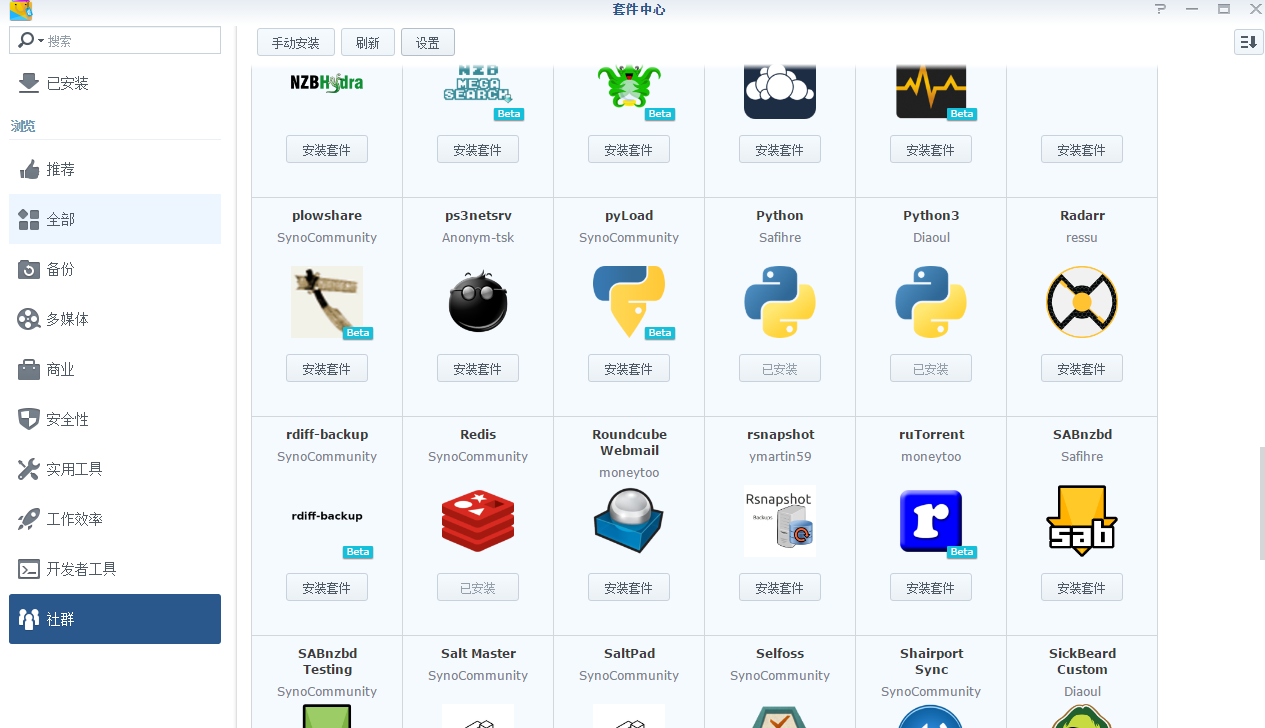
安装如下python3就好

安装完成后,进入设置开启ssh,putty远程连接上群辉。
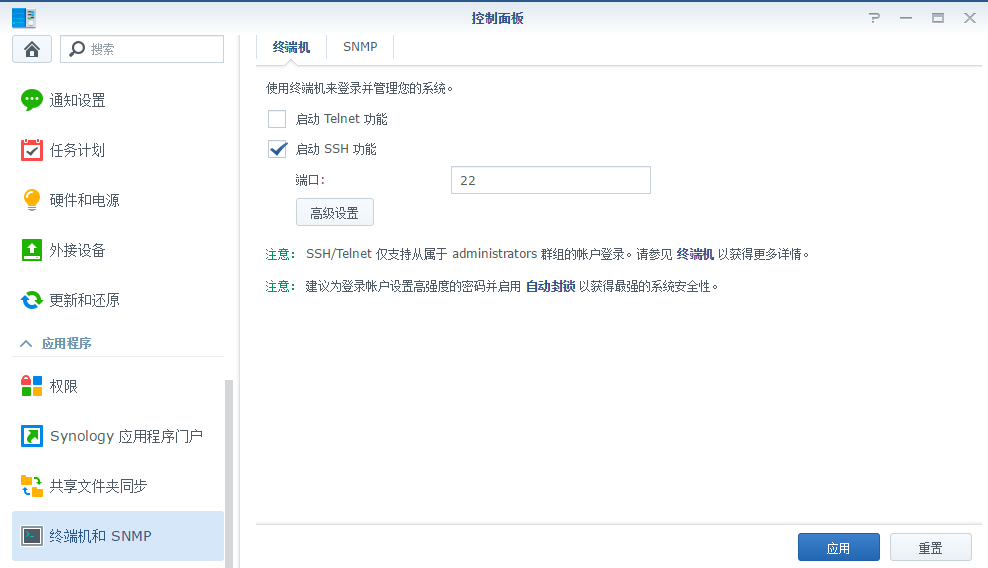
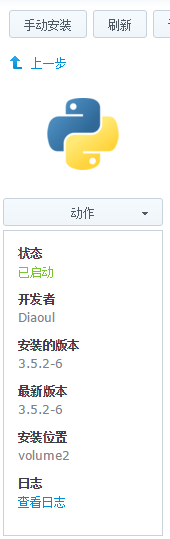
记得查看一下python3安装在哪个位置,在下图中可以得到位置,我的是在volume2下
2.群辉官方安装的python3默认是没有pip的,我废了老大劲装上了,然后pip3 install scrapy装不上。
当然如果装上了这个教程就到此结束了,结果废了半天劲最后没用上pip。
pip安装scrapy 期间处理各种错误,奈何本人技术有限无法成功,只能另辟蹊径用非正常方法了。
本人开发环境是虚拟机下的deepin系统(底层也是linux),已经装好了scrapy框架,同样是python3.5。
进入deppin虚拟机的套件安装目录,本人的路径是/home/libing/.local/lib/python3.5/site-packages,别的系统自行查找
复制出来以下文件夹待用 pydispatch,pyOpenSSL-18.0.0.dist-info,scrapy,twisted,Twisted-18.7.0.dist-info,
复制出来scrapy文件,命令行下 type scrapy 可以查看路径。
上传复制出来的文件到群辉。我上传到了 /volume2/docker 目录下
文件夹名称可能版本不同有所差异,可能有漏的,因为我安装了pip复制完成后又执行了pip install scrapy 进行了安装会把某些漏网之鱼装上。
3.putty连接上群辉 执行sudo su - 命令输入当前用户的密码进入超级管理员(注意su和-有一个空格)
cd 到 /volume2/@appstore/python3/lib/python3 目录
volume2就是刚才群辉安装套件的位置
python3.5根据安装版本不同可能不同。
执行cp命令复制刚才上传的文件到当前目录
cp -r /volume2/docker/python3/刚才上传的文件夹名/ ./
所有的都有全部复制过去
然后把scrapy文件复制到/usr/local/bin/就好
cp /volume2/docker/python3/scrapy /usr/local/bin/scrapy /usr/local/bin/
还要为python3创建一个软连接,不然会提示没有python3命令根据我的路径是如下命令
ln -s /volume2/docker/python3/scrapy /usr/local/bin/python3 /bin/
也可以这样给pip3添加软连接。
建议再进行pip3 install scrapy安装一次,防止有漏的文件夹和文件。
完成后如果执行scrapy命令不报错,那么恭喜你成功了。
群辉6.1.7安装scrapy框架执行爬虫的更多相关文章
- 怎么安装Scrapy框架以及安装时出现的一系列错误(win7 64位 python3 pycharm)
因为要学习爬虫,就打算安装Scrapy框架,以下是我安装该模块的步骤,适合于刚入门的小白: 一.打开pycharm,依次点击File---->setting---->Project---- ...
- Python3安装scrapy框架步骤
Python3安装scrapy框架步骤 1. 安装wheel a) Pip install wheel 2. 安装lxml Pip install lxml 3. ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
- 基于scrapy框架的爬虫基本步骤
本文以爬取网站 代码的边城 为例 1.安装scrapy框架 详细教程可以查看本站文章 点击跳转 2.新建scrapy项目 生成一个爬虫文件.在指定的目录打开cmd.exe文件,输入代码 scrapy ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 安装scrapy框架
前提安装好python.setuptools. 1.安装Python 安装完了记得配置环境,将python目录和python目录下的Scripts目录添加到系统环境变量的Path里.在cmd中输入py ...
- python网络爬虫(1)——安装scrapy框架的常见问题及其解决方法
Scrapy是为了爬取网站数据而编写的一款应用框架,出名,强大.所谓的框架其实就是一个集成了相应的功能且具有很强通用性的项目模板. 其实在Linux和 Mac安装,就简单的pip命令即可: pip i ...
- python安装Scrapy框架
看到自己写的惨不忍睹的爬虫,觉得还是学一下Scrapy框架,停止一直造轮子的行为 我这里是windows10平台,python2和python3共存,这里就写python2.7安装配置Scrapy框架 ...
- windows下安装Scrapy框架
一 首先我们通过pycharm安装: 发现不行,会报错. 二 通过命令行再次进行安装: 发现还是会报错: 更新下pip,继续安装,发现还是不行,那怎么办呢? 继续安装Scrapy发下还是不行: 那么我 ...
随机推荐
- 2018.10.25 bzoj4517: [Sdoi2016]排列计数(组合数学)
传送门 组合数学简单题. Ans=(nm)∗1Ans=\binom {n} {m}*1Ans=(mn)∗1~(n−m)(n-m)(n−m)的错排数. 前面的直接线性筛逆元求. 后面的错排数递推式本蒟 ...
- pat 甲级 1086(树的遍历||建树)
思路1:可以用建树来做 由于是先序遍历,所以直接先序建树就行了. #include<iostream> #include<cstdio> #include<cstring ...
- Java数组的初始化
1.动态初始化 数据类型 [] 变量名 = new 数据类型 [数组大小]; //数组的动态初始化 int [] arr = new int [3]; 2.静态初始化 数据类型 [] 变量名 = {元 ...
- LPCSTR与CString转换
1.LPCSTR是Win32和VC++所使用的一种字符串数据类型,L表示long,P表示指针,C表示常量,STR表示字符串. 2.LPCSTR转化为CString: LPCSTR lpStr=&qu ...
- hadoop 组件 hdfs架构及读写流程
一 . Namenode Namenode 是整个系统的管理节点 就像一本书的目录,储存文件信息,地址,接受用户请求,等 二 . Datanode 提供真实的文件数据,存储服务 文件块(block)是 ...
- Camtasia studio8.0破解方法
Camtasia Studio 8.0 注册说明: 1.安装时使用以下信息注册: 用户名: Honorary User密钥: GCABC-CPCCE-BPMMB-XAJXP-S8F6R 或者是 Nam ...
- Spring MVC 指导文档解读(二)
Special Bean Types In the WebApplicationContext 解读 1.WebApplicationContext 特有的几种 Bean Types 2. 也表明 与 ...
- Android自定义视图一:扩展现有的视图,添加新的XML属性
这个系列是老外写的,干货!翻译出来一起学习.如有不妥,不吝赐教! Android自定义视图一:扩展现有的视图,添加新的XML属性 Android自定义视图二:如何绘制内容 Android自定义视图三: ...
- MapGis如何实现WebGIS分布式大数据存储的
作为解决方案厂商,MapGis是如何实现分布式大数据存储的呢? MapGIS在传统关系型空间数据库引擎MapGIS SDE的基础之上,针对地理大数据的特点,构建了MapGIS DataStore分布式 ...
- form表单提交时action路劲问题
项目总出现window上部署可以访问,linux下部署不能访问的问题 linux下访问action必须是全路径,可以加上“${pageContext.request.contextPath}” 便可 ...