pandas中DataFrame和Series的数据去重
在SQL语言中去重是一件相当简单的事情,面对一个表(也可以称之为DataFrame)我们对数据进行去重只需要GROUP BY 就好。
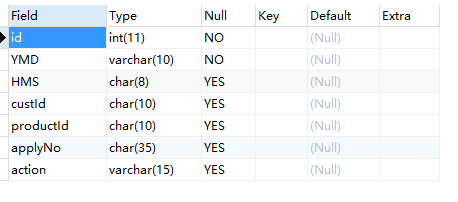
select custId,applyNo from tmp.online_service_startloan group by custId,applyNo
1.DataFrame去重
但是对于pandas的DataFrame格式就比较麻烦,我看了其他博客优化了如下三种方案。
我们先引入数据集:
import pandas as pd
data=pd.read_csv(r'D:/home/nohup.out.20191028.startloan.csv',encoding='utf-8')
print(data.info())

共有14936条数据,那我们还是按 custId和applyNo去重。
1.使用list后手写去重
定义去重函数:我这里使用了遍历行,添加列表的的方式去重。
# 定义去重函数
def dropRep(df):
list2=[]
for _,i in df.iterrows():
i=list(i)
if i not in list2:
list2.append(i)
return list2
keydata=data[['custId','applyNo']]
len1=keydata.count()
print('去重之前custId +applyNo:',len1) list2=dropRep(keydata)
print('去重之后custId +applyNo:',len(list2))
2.使用list后set去重
用set去重其实遇到了很多问题,set里面的数据必须是不可变数据类型,可hash等等。。所以只能把key1+key2拼成字符串作为一个元素。
# 定义去重函数
def dropRepBySet(df):
set1=set()
for _,i in df.iterrows():
set1.add("_".join(list(map(lambda x:str(x),list(i)))))
return list(set1)
而且明显感觉这个方法比上面手写list遍历去重快一些
keydata=data[['custId','applyNo']]
len1=keydata.count()
print('去重之前custId +applyNo:',len1) list2=dropRepBySet(keydata) print('去重之后custId +applyNo:',len(list2))

3.使用pd.DataFrame自带drop_duplicates()函数去重
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
- subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
- keep : {‘first’, ‘last’, False}, default ‘first’
first删除重复项并保留第一次出现的项,last删除重复保留最后一条,False就是删除重复、只要不重复的数据
- inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
keydata.drop_duplicates().count()
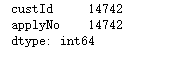
keydata.drop_duplicates(keep=False).count()
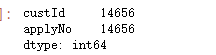
补充提取重复数据
# 剔除重复的数据
data1=keydata.drop_duplicates(keep=False)
data1.count()
#至少保留一条
data2=keydata.drop_duplicates(keep="first")
data2.count()
#这样正常的数据就重复了,重复的数据就只有一条
data1.append(data2).drop_duplicates(keep=False).count()
2.Series去重
我也是最近才遇到series去重这个场景,比较了一下两种去重的性能比较。
场景如下
sql==>pd.dataframe【数据量为8000rows】==>取出这个df的cust_id字段【series】==>转为list===>下一个sql:'''···where cust_id not in (%s)'''%".".join(list)
方法1:
方法2:seiries.drop_duplicates()

pandas中DataFrame和Series的数据去重的更多相关文章
- Spark与Pandas中DataFrame对比
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Pandas中DataFrame修改列名
Pandas中DataFrame修改列名:使用 rename df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01- ...
- pandas中DataFrame的ix,loc,iloc索引方式的异同
pandas中DataFrame的ix,loc,iloc索引方式的异同 1.loc: 按照标签索引,范围包括start和end 2.iloc: 在位置上进行索引,不包括end 3.ix: 先在inde ...
- pandas中DataFrame重置设置索引
在pandas中,经常对数据进行处理 而导致数据索引顺序混乱,从而影响数据读取.插入等. 小笔总结了以下几种重置索引的方法: import pandas as pd import numpy as n ...
- pandas中DataFrame对象to_csv()方法中的encoding参数
当使用pd.read_csv()方法读取csv格式文件的时候,常常会因为csv文件中带有中文字符而产生字符编码错误,造成读取文件错误,在这个时候,我们可以尝试将pd.read_csv()函数的enco ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之merge
二.merge:通过键拼接列 类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来. 该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面 ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之join
pandas.DataFrame.join 自己弄了很久,一看官网.感觉自己宛如智障.不要脸了,直接抄 DataFrame.join(other, on=None, how='left', lsuff ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之concat
一.concat:沿着一条轴,将多个对象堆叠到一起 concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, key ...
随机推荐
- Android Studio彻底删除Module
在"Project"视图中选择需要删除的module名,此处删除"app",点击右键,选择"Open Module Setting",然后选 ...
- Ubuntu 18.04修改默认源为国内源
安装Ubuntu 18.04后,使用国外源太慢了,修改为国内源会快很多. 修改阿里源为Ubuntu 18.04默认的源 备份/etc/apt/sources.list 备份 cp /etc/apt/s ...
- PHP学习之PHP的语法糖
PHP的语法糖 计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用. 常见的PHP的语法糖 echo(),print(),die(),isset(),unset(),i ...
- Go-常识补充-切片-map(类似字典)-字符串-指针-结构体
目录 Go 常识补充 Go 命名 打印变量类型科普 _ 关键字 命名规范相关 包目录规范 切片 多维切片 切片初始化的方法 多维切片初始化 切片删除元素(会略微影响效率 ,少用) copy 函数 打散 ...
- 【leetcode】【二分 | 牛顿迭代法】69_Sqrt(x)
题目链接:传送门 题目描述: 求Sqrt(x),返回整数值即可. [代码]: #include<bits/stdc++.h> using namespace std; ; /* int m ...
- Payload 实现分离免杀
众所周知,目前的杀毒软件的杀毒原理主要有三种方式,一种基于特征,一种基于行为,一种基于云查杀,其中云查杀的一些特点基本上也可以概括为特征码查杀,不管是哪一种杀毒软件,都会检查PE文件头,尤其是当后门程 ...
- Scala学习十四——模式匹配和样例类
一.本章要点 match表达式是更好的switch,不会有意外调入下一个分支 如果没有模式能够匹配,会抛出MatchError,可以用case _模式避免 模式可以包含一个随意定义的条件,称做守卫 你 ...
- Linux下mysql创建用户并设置权限,设置远程连接
为了安全考虑,OneinStack仅允许云主机本机(localhost)连接数据库,如果需要远程连接数据库,需要如下操作:打开iptables 3306端口 # iptables -I INPUT 4 ...
- BMP RGB888转RGB565 +上下翻转+缩放
典型的BMP图像文件由四部分组成: (1) 位图头文件数据结构,它包含BMP图像文件的类型.文件大小和位图起始位置等信息: typedef struct tagBITMAPFILEHEADER { ...
- WinSockAPI多线程服务器
运行效果: 程序: // TcpServer.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream&g ...