MapReduce框架中的Shuffle机制
Shuffle是map和reduce中间的数据调度过程,包括:缓存、分区、排序等。
Shuffle数据调度过程:
map task处理hdfs文件,调用map()方法,map task的collect thread将map()方法结果放入环形缓冲区(默认大小100M)- 当环形缓冲区达到
阈值(80%),将会触发溢出操作,split thread线程会调用HashPartitioner或者自定义的分区规则,对缓冲区内容进行分区,区内文件内容有序。 - 当环形缓冲区再次达到阈值,会再次触发溢出操作,重复步骤2
map()方法执行结束后,会生成一系列分区且区内有序的溢出小文件。该溢出小文件不会直接交给reduce()方法,会进行merge操作,将溢出的小文件按分区进行合并,生成一个完整的分区且区内有序的大文件。- 每个
reduce task会获取每个map task阶段最终结果文件的指定分区文件内容,进行归并排序操作,按照key排序,生成一个聚合组。 - 每个
聚合组调用一次reduce()方法,key为这一聚合组的相同key,values是这一聚合组的所有value的迭代器。 - 生成最终结果文件。
Shuffle数据调度过程(大图链接):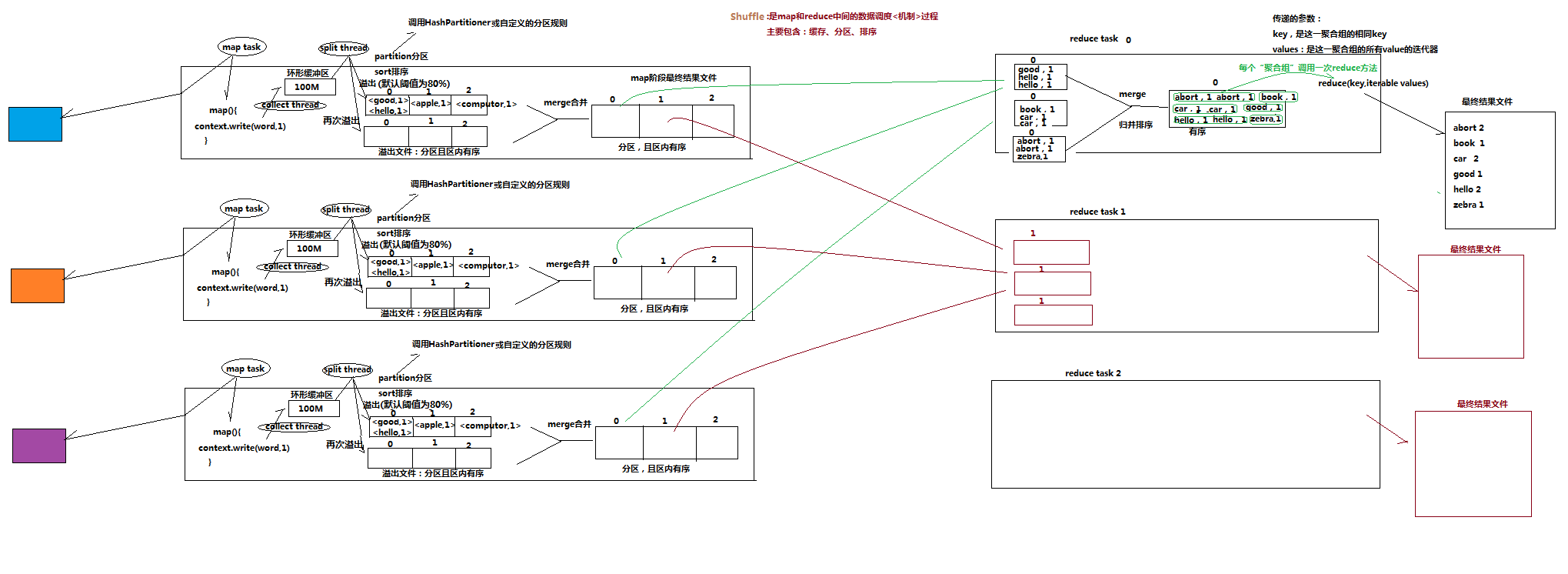
MapReduce框架中的Shuffle机制的更多相关文章
- 一文搞懂Java/Spring/Dubbo框架中的SPI机制
几天前和一位前辈聊起了Spring技术,大佬突然说了SPI,作为一个熟练使用Spring的民工,心中一紧,咱也不敢说不懂,而是在聊完之后赶紧打开了浏览器,开始的学习之路,所以也就有了这篇文章.废话不多 ...
- Android框架中的广播机制
一.广播通过Intent发送出去 // 定义广播的意图过滤器 private String action = "com.xxx.demo.Broadcast.STATUS_CHANGED&q ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述 1.MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle 2.Shuffle: 数 ...
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制: Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle 将mapta ...
- 下一代Apache Hadoop MapReduce框架的架构
背景 随着集群规模和负载增加,MapReduce JobTracker在内存消耗,线程模型和扩展性/可靠性/性能方面暴露出了缺点,为此需要对它进行大整修. 需求 当我们对Hadoop MapReduc ...
- 经典 MapReduce框架(MRv1)
在 MapReduce 框架中,作业执行受两种类型的进程控制: 一个称为 JobTracker 的主要进程,它协调在集群上运行的所有作业,分配要在 TaskTracker 上运行的 map 和 red ...
随机推荐
- HTTP服务器(2)
import socket import re import multiprocessing def service_client(new_socket): """为这个 ...
- linux 下载jdk
1.官方下载jdk的地方 jdk8下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-213315 ...
- Linux 常用命令之df du
1.du 命令:显示每个文件或目录的磁盘使用空间 1) du -h --max-depth [root@ip101 app]# pwd /opt/app [root@ip101 app]# du -h ...
- iframe 跨域传参
parent-index.html: (本地起服务,放在5000端口上) <div class="content"> <iframe src="http ...
- [go]unsafe.Sizeof浅析
sizeof 如果x为一个切片,sizeof返回的大小是切片的描述符,而不是切片所指向的内存的大小. 那么这里如果换成一个数组呢?而不是一个切片 arr := [...]int{1,2,3,4,5} ...
- 2017年内容营销如何提高ROI转化率
根据2017 CMI报告显示,有近41%的营销人员今年会实施一系列内容营销战略.作为与用户间长期关系的桥梁, 从品牌化输出到信任感的培育,内容营销的影响力迅猛发展. 本次Focussend从互动集成内 ...
- TCP/IP及内核参数优化调优(转)
Linux下TCP/IP及内核参数优化有多种方式,参数配置得当可以大大提高系统的性能,也可以根据特定场景进行专门的优化,如TIME_WAIT过高,DDOS攻击等等.如下配置是写在sysctl.conf ...
- SQL学习(七)试图
试图是基于SQL语句的结果集的可视化表. 1.创建试图 create view 试图名 as select 语句 如: create view ticketresult as select * fro ...
- Ubunut16.04 安装 Theano+GPU
1. 更新NVIDIA显卡驱动 安装好系统之后首先在系统更新管理器中更新显卡驱动,如下图 点击Apply Changes 2. 安装numpy,scipy,theano pip安装即可 sudo ...
- Python使用filetype精确判断文件类型
Python使用filetype精确判断文件类型 判断文件类型在开发中非常常见的需求,怎样才能准确的判断文件类型呢?首先大家想到的是文件的后缀,但是非常遗憾的是这种方法是非常不靠谱的,因为文件的后缀是 ...