Hive-1.2.1_02_简单操作与访问方式
1. Hive默认显示当前使用库
、需要用时,即时配置,在cli执行属性设置,这种配置方式,当重新打开cli时,就会生效:
hive> set hive.cli.print.current.db=true; 、一次配置,永久生效,在当前用户的HOME目录下,新建.hiverc文件,把属性设置命令放置到该文件中,每次打开cli时,都会先执行该文件。
[yun@mini01 ~]$ pwd
/app
[yun@mini01 ~]$ cat .hiverc
set hive.cli.print.current.db=true; 、在hive配置文件中添加配置【推荐】,上一篇文章hive配置中已经有了该配置项
<!-- 显示当前使用的数据库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
2. 创建库
# 没有显示当前使用库
[yun@mini01 ~]$ hive Logging initialized using configuration in jar:file:/app/hive-1.2./lib/hive-common-1.2..jar!/hive-log4j.properties
hive> show databases; # 默认库为default
OK
default
Time taken: 0.774 seconds, Fetched: row(s)
# 创建库
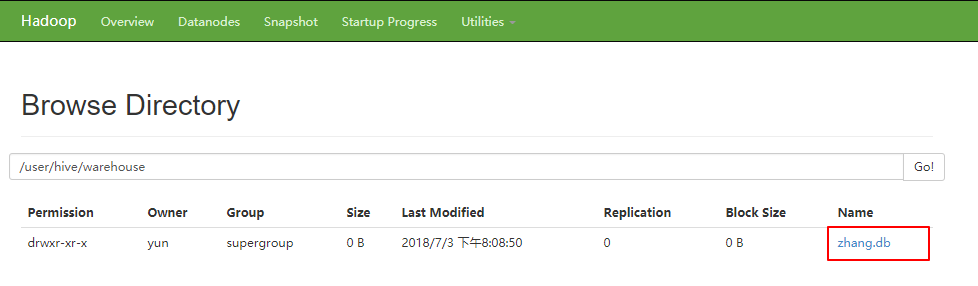
hive> create database zhang;
OK
Time taken: 0.168 seconds
hive> show databases;
OK
default
zhang
Time taken: 0.02 seconds, Fetched: row(s)
浏览器访问
3. 创建表
# 默认显示当前使用库
hive (default)> show databases;
OK
default
zhang
Time taken: 0.729 seconds, Fetched: row(s)
hive (default)> use zhang;
OK
Time taken: 0.036 seconds
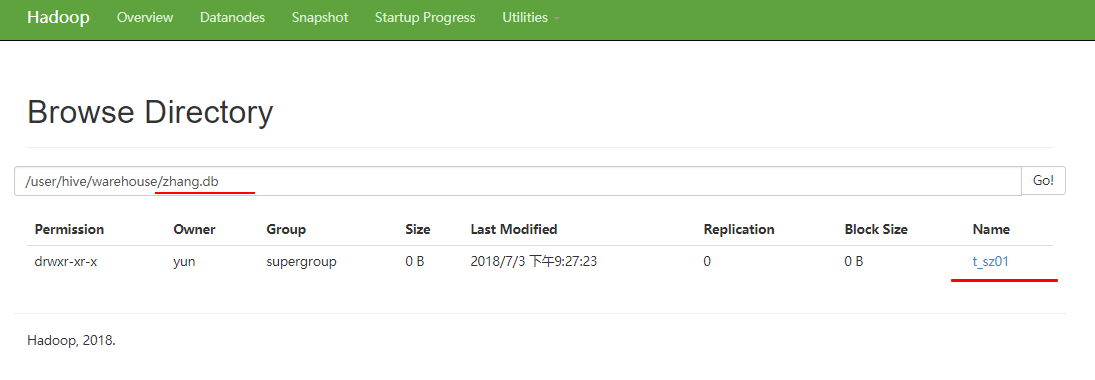
hive (zhang)> create table t_sz01(id int, name string)
> row format delimited
> fields terminated by ',';
OK
Time taken: 0.187 seconds
hive (zhang)> show tables;
OK
t_sz01
Time taken: 0.031 seconds, Fetched: row(s)
浏览器访问
4. 创建数据并上传
[yun@mini01 hive]$ cat sz.dat
,zhangsan
,李四
,wangwu
,赵六
,zhouqi
,孙八
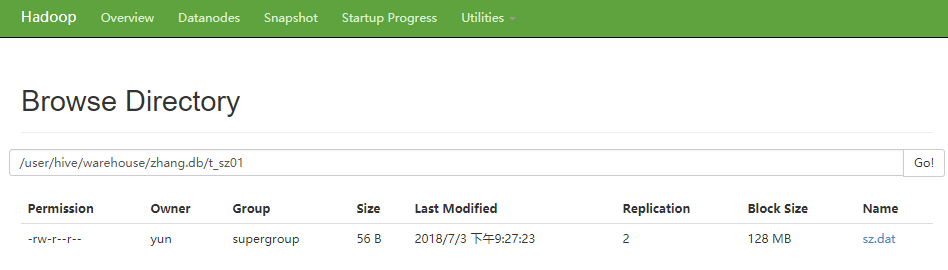
[yun@mini01 hive]$ hadoop fs -put sz.dat /user/hive/warehouse/zhang.db/t_sz01 # 上传
[yun@mini01 hive]$ hadoop fs -ls /user/hive/warehouse/zhang.db/t_sz01/
Found items
-rw-r--r-- yun supergroup -- : /user/hive/warehouse/zhang.db/t_sz01/sz.dat
[yun@mini01 hive]$ hadoop fs -cat /user/hive/warehouse/zhang.db/t_sz01/sz.dat
,zhangsan
,李四
,wangwu
,赵六
,zhouqi
,孙八
5. Hive查询数据
hive (zhang)> show tables;
OK
t_sz01
Time taken: 0.028 seconds, Fetched: row(s)
hive (zhang)> select * from t_sz01; # 全表查询
OK
zhangsan
李四
wangwu
赵六
zhouqi
孙八
Time taken: 0.264 seconds, Fetched: row(s)
hive (zhang)> select count() from t_sz01; # 表数据条数
Query ID = yun_20180703213443_ebca743c--405a--59359e1566c2
Total jobs =
Launching Job out of
Number of reduce tasks determined at compile time:
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
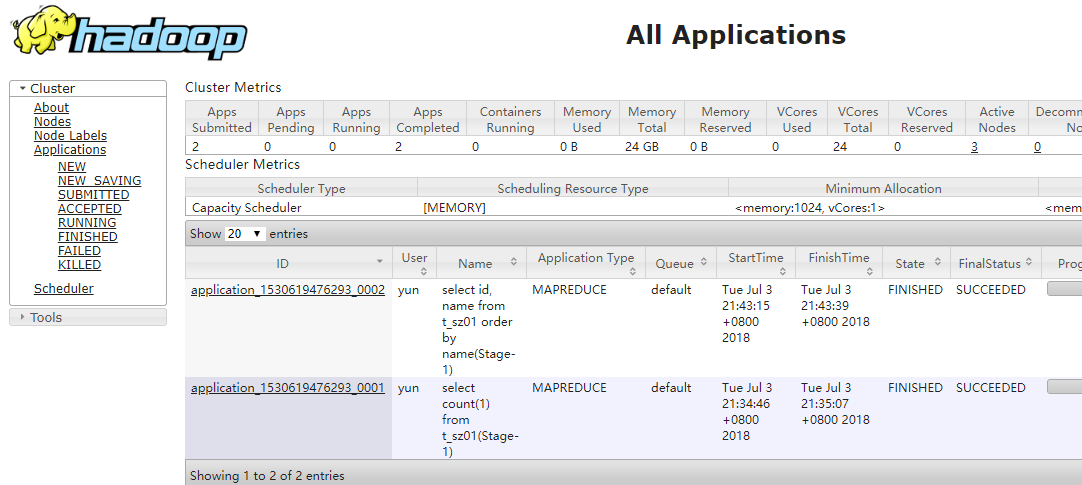
Starting Job = job_1530619476293_0001, Tracking URL = http://mini02:8088/proxy/application_1530619476293_0001/
Kill Command = /app/hadoop/bin/hadoop job -kill job_1530619476293_0001
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 2.5 sec
-- ::, Stage- map = %, reduce = %, Cumulative CPU 6.37 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1530619476293_0001
MapReduce Jobs Launched:
Stage-Stage-: Map: Reduce: Cumulative CPU: 6.37 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK Time taken: 25.312 seconds, Fetched: row(s)
hive (zhang)> select id,name from t_sz01 where id >; # 查询id>
OK
李四
zhouqi
孙八
Time taken: 0.126 seconds, Fetched: row(s)
hive (zhang)> select id,name from t_sz01 where id > limit ; # 不能使用 limit m,n
OK
李四
zhouqi
Time taken: 0.072 seconds, Fetched: row(s)
hive (zhang)> select id, name from t_sz01 order by name; # 使用order by 排序
Query ID = yun_20180703214314_db222afe--4c8e--73aa4fec62ef
Total jobs =
Launching Job out of
Number of reduce tasks determined at compile time:
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1530619476293_0002, Tracking URL = http://mini02:8088/proxy/application_1530619476293_0002/
Kill Command = /app/hadoop/bin/hadoop job -kill job_1530619476293_0002
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 2.64 sec
-- ::, Stage- map = %, reduce = %, Cumulative CPU 4.85 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1530619476293_0002
MapReduce Jobs Launched:
Stage-Stage-: Map: Reduce: Cumulative CPU: 4.85 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
wangwu
zhangsan
zhouqi
孙八
李四
赵六
Time taken: 26.768 seconds, Fetched: row(s)
MapReduce信息
http://mini02:8088
6. Hive的访问方式
6.1. Hive交互shell
# 之间已经添加环境变量
[yun@mini01 ~]$ hive
6.2. Hive thrift服务
启动方式,(例如是在mini01上):
# 之间已经添加环境变量
启动为前台: hiveserver2
启动为后台: nohup hiveserver2 >/app/hive/logs/hiveserver.log >/app/hive/logs/hiveserver.err &
# 没有 /app/hive/logs 目录就创建
启动成功后,可以在别的节点上用beeline去连接
方式1
# 由于没有在其他机器安装,所以还是在本机用beeline去连接
[yun@mini01 bin]$ beeline
Beeline version 1.2. by Apache Hive
beeline> !connect jdbc:hive2://mini01:10000 # jdbc连接 可以是mini01、127.0.0.0、10.0.0.11、172.16.1.11
Connecting to jdbc:hive2://mini01:10000
Enter username for jdbc:hive2://mini01:10000: yun
Enter password for jdbc:hive2://mini01:10000:
Connected to: Apache Hive (version 1.2.)
Driver: Hive JDBC (version 1.2.)
Transaction isolation: TRANSACTION_REPEATABLE_READ
: jdbc:hive2://mini01:10000>
方式2
# 或者启动就连接:
[yun@mini01 ~]$ beeline -u jdbc:hive2://mini01:10000 -n yun
接下来就可以做正常sql查询了
例如:
: jdbc:hive2://mini01:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| zhang |
+----------------+--+
rows selected (0.437 seconds)
: jdbc:hive2://mini01:10000> use zhang;
No rows affected (0.058 seconds)
: jdbc:hive2://mini01:10000> show tables;
+-----------+--+
| tab_name |
+-----------+--+
| t_sz01 |
+-----------+--+
row selected (0.054 seconds)
: jdbc:hive2://mini01:10000> select * from t_sz01;
+------------+--------------+--+
| t_sz01.id | t_sz01.name |
+------------+--------------+--+
| | zhangsan |
| | 李四 |
| | wangwu |
| | 赵六 |
| | zhouqi |
| | 孙八 |
+------------+--------------+--+
rows selected (0.641 seconds)
: jdbc:hive2://10.0.0.11:10000> select count(1) from t_sz01; # 条数查询
INFO : Number of reduce tasks determined at compile time:
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:
INFO : Submitting tokens for job: job_1530619476293_0003
INFO : The url to track the job: http://mini02:8088/proxy/application_1530619476293_0003/
INFO : Starting Job = job_1530619476293_0003, Tracking URL = http://mini02:8088/proxy/application_1530619476293_0003/
INFO : Kill Command = /app/hadoop/bin/hadoop job -kill job_1530619476293_0003
INFO : Hadoop job information for Stage-: number of mappers: ; number of reducers:
INFO : -- ::, Stage- map = %, reduce = %
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 2.56 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 5.28 sec
INFO : MapReduce Total cumulative CPU time: seconds msec
INFO : Ended Job = job_1530619476293_0003
+------+--+
| _c0 |
+------+--+
| |
+------+--+
row selected (25.433 seconds)
6.3. hive -e "HiveQL"
适用于写脚本
[yun@mini01 ~]$ hive -e "use exercise; select * from student;" Logging initialized using configuration in jar:file:/app/hive-1.2./lib/hive-common-1.2..jar!/hive-log4j.properties
OK
Time taken: 1.109 seconds
OK
李勇 男 CS
刘晨 女 IS
王敏 女 MA
张立 男 IS
刘刚 男 MA
孙庆 男 CS
易思玲 女 MA
李娜 女 CS
梦圆圆 女 MA
孔小涛 男 CS
Time taken: 0.786 seconds, Fetched: row(s)
6.4. hive -f 'test.sql'
适用于hive直接调用一个脚本,该脚本中全是hive的类SQL语句。
# aztest.sql 脚本名称
CREATE DATABASE IF NOT EXISTS azkaban;
use azkaban;
DROP TABLE IF EXISTS aztest;
DROP TABLE IF EXISTS azres;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput/azkb.dat' into table aztest;
create table azres row format delimited fields terminated by '#' as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
7. 文章参考
1、Hive创建表格报【Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
Hive-1.2.1_02_简单操作与访问方式的更多相关文章
- 简单操作:10分钟实现在kubernetes(k8s)里面部署服务器集群并访问项目(docker三)
前言 经过docker安装.k8s开启并登录,我们终于到 "部署k8s服务器集群并访问项目" 这一步了,实现的过程中有太多坑,好在都填平了,普天同庆. 在进行当前课题之前,我们需要 ...
- Hive的基本知识与操作
Hive的基本知识与操作 目录 Hive的基本知识与操作 Hive的基本概念 为什么使用Hive? Hive的特点: Hive的优缺点: Hive应用场景 Hive架构 Client Metastor ...
- python(pymysql)之mysql简单操作
一.mysql简单介绍 说到数据库,我们大多想到的是关系型数据库,比如mysql.oracle.sqlserver等等,这些数据库软件在windows上安装都非常的方便,在Linux上如果要安装数据库 ...
- C# Asp.net中简单操作MongoDB数据库(一)
需要引用MongoDB.Driver.dll.MongoDB.Driver.core.dll.MongoDB.Bson.dll三个dll. 1.数据库连接: public class MongoDb ...
- 二叉树的简单操作(Binary Tree)
树形结构应该是贯穿整个数据结构的一个比较重要的一种结构,它的重要性不言而喻! 讲到树!一般都是讨论二叉树,而关于二叉树的定义以及概念这里不做陈诉,可自行搜索. 在C语言里面需要实现一个二叉树,我们需要 ...
- MongoDB数据库简单操作
之前学过的有mysql数据库,现在我们学习一种非关系型数据库 一.简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数 ...
- 【ZooKeeper】ZooKeeper安装及简单操作
ZooKeeper介绍 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一 ...
- MySQL基本概念以及简单操作
一.MySQL MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MyS ...
- HDFS介绍及简单操作
目录 1.HDFS是什么? 2.HDFS设计基础与目标 3.HDFS体系结构 3.1 NameNode(NN)3.2 DataNode(DN)3.3 SecondaryNameNode(SNN)3.4 ...
随机推荐
- CentOS 6.5静态IP的设置(NAT和桥接联网方式都适用)
不多说,直接上干货! 为了方便,用Xshell来.并将IP设置为静态的.因为,在CentOS里,若不对其IP进行静态设置的话,则每次开机,其IP都是动态变化的,这样会给后续工作带来麻烦.为此,我们需将 ...
- C#效率优化(1)-- 使用泛型时避免装箱
本想接着上一篇详解泛型接着写一篇使用泛型时需要注意的一个性能问题,但是后来想着不如将之前的详解XX系列更正为现在的效率优化XX系列,记录在工作时遇到的一些性能优化的经验和技巧,如果有什么不足,还请大家 ...
- Extjs gridPanel可复制配置(转)
ExtJS默认是禁用了文本复制的功能,实际需求中可能需要能够复制,那么如何解决了,我在网上看到了许多解决办法,绝大部分都是从重写CSS样式或者重写gridView代码入手,我遇到这个问题的时候,我想作 ...
- (转)关于CNN中平移不变性的理解
https://www.quora.com/Why-and-how-are-convolutional-neural-networks-translation-invariant https://st ...
- 嵌套函数变量修改nonlocal & 全局变量修改global
前几天在做一个简单的界面,单击Radiobutton保存字符串,在一个嵌套函数里面修改外部函数.一直不知道怎么修改,上网查了一下,搜关键字“嵌套函数修改变量”,找了好久,才得以解决. 对于python ...
- snmp自定义OID与文件下载----服务器端配置
客户端使用命令工具:snmpwalk 服务端开启服务 snmp service.下载安装 net-snmp. 最近做了一些工作,记性较差感觉还是记下来比较好,毕竟网上能查到的有用的资料太少了. 自定义 ...
- 细说Redis(二)之 Redis的持久化
前言 在上一篇文章[细说Redis(一)之 Redis的数据结构与应用场景]中,主要介绍了Reids的数据结构. 对于redis的执行命令,这里不做介绍,因为网上搜索一堆,无必要再做介绍. AOF&a ...
- Centos7下开启80端口
firewall-cmd --zone=/tcp --permanent 命令含义: --zone #作用域 --add-port=80/tcp #添加端口,格式为:端口/通讯协议 -- ...
- idea/ecipse中使用maven集成springmvc相关jar包时候,出错:java.lang.ClassNotFoundException: org.springframework.web.servlet.DispatcherServlet
参考stackoverflow:https://stackoverflow.com/questions/11227395/java-lang-classnotfoundexception-org-sp ...
- JavaScript中的window对象的属性和方法;JavaScript中如何选取文档元素
一.window对象的属性和方法 ①setTimeout()方法用来实现一个函数在指定毫秒之后运行,该方法返回一个值,这个值可以传递给clearTimeout()用于取消这个函数的执行. ②setIn ...