Scrapy-Splash的介绍、安装以及实例
scrapy-splash的介绍
在前面的博客中,我们已经见识到了Scrapy的强大之处。但是,Scrapy也有其不足之处,即Scrapy没有JS engine, 因此它无法爬取JavaScript生成的动态网页,只能爬取静态网页,而在现代的网络世界中,大部分网页都会采用JavaScript来丰富网页的功能。所以,这无疑Scrapy的遗憾之处。
那么,我们还能愉快地使用Scrapy来爬取动态网页吗?有没有什么补充的办法呢?答案依然是yes!答案就是,使用scrapy-splash模块!
scrapy-splash模块主要使用了Splash. 所谓的Splash, 就是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT。Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。Splash的特点如下:
- 并行处理多个网页
- 得到HTML结果以及(或者)渲染成图片
- 关掉加载图片或使用 Adblock Plus规则使得渲染速度更快
- 使用JavaScript处理网页内容
- 使用Lua脚本
- 能在Splash-Jupyter Notebooks中开发Splash Lua scripts
- 能够获得具体的HAR格式的渲染信息
scrapy-splash的安装
由于Splash的上述特点,使得Splash和Scrapy两者的兼容性较好,抓取效率较高。
听了上面的介绍,有没有对scrapy-splash很心动呢?下面就介绍如何安装scrapy-splash,步骤如下:
1. 安装scrapy-splash模块
pip3 install scrapy-splash
2. scrapy-splash使用的是Splash HTTP API, 所以需要一个splash instance,一般采用docker运行splash,所以需要安装docker。不同系统的安装命令会不同,如笔者的CentOS7系统的安装方式为:
sudo yum install docker
安装完docker后,可以输入命令‘docker -v’来验证docker是否安装成功。
3. 开启docker服务,拉取splash镜像(pull the image):
sudo service docker start
sudo dock pull scrapinghub/splash
运行结果如下:
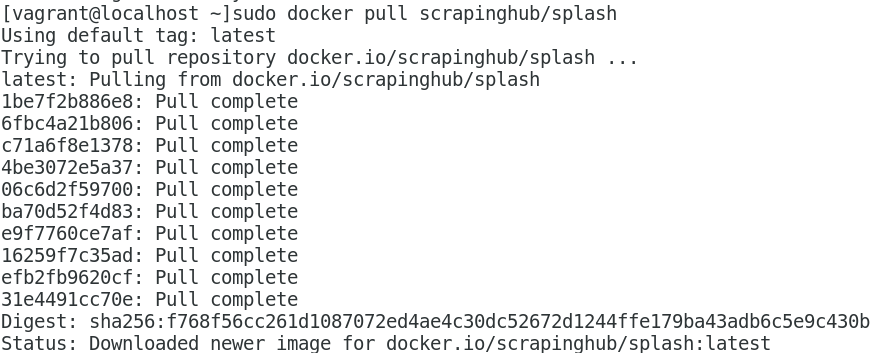
4. 开启容器(start the container):
sudo docker run -p 8050:8050 scrapinghub/splash
此时Splash以运行在本地服务器的端口8050(http).在浏览器中输入'localhost:8050', 页面如下:

在这个网页中我们能够运行Lua scripts,这对我们在scrapy-splash中使用Lua scripts是非常有帮助的。以上就是我们安装scrapy-splash的全部。
scrapy-splash的实例
在安装完scrapy-splash之后,不趁机介绍一个实例,实在是说不过去的,我们将在此介绍一个简单的实例,那就是利用百度查询手机号码信息。比如,我们在百度输入框中输入手机号码‘159********’,然后查询,得到如下信息:
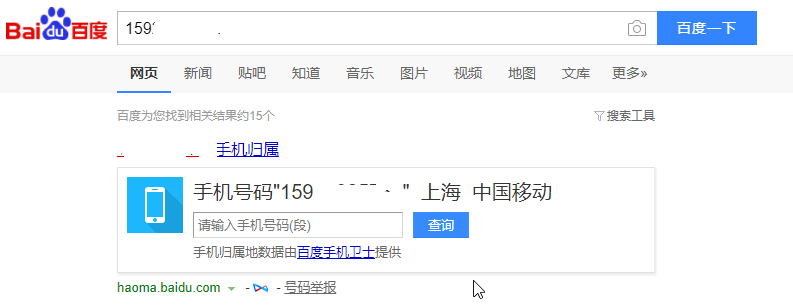
我们将利用scrapy-splash模拟以上操作并获取手机号码信息。
1. 创建scrapy项目phone
2. 配置settings.py文件,配置的内容如下:
ROBOTSTXT_OBEY = False
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810
}
SPLASH_URL = 'http://localhost:8050'
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
具体的配置说明可以参考: https://pypi.python.org/pypi/scrapy-splash .
3. 创建爬虫文件phoneSpider.py, 代码如下:
# -*- coding: utf-8 -*-
from scrapy import Spider, Request
from scrapy_splash import SplashRequest
# splash lua script
script = """
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(args.wait))
js = string.format("document.querySelector('#kw').value=%s;document.querySelector('#su').click()", args.phone)
splash:evaljs(js)
assert(splash:wait(args.wait))
return splash:html()
end
"""
class phoneSpider(Spider):
name = 'phone'
allowed_domains = ['www.baidu.com']
url = 'https://www.baidu.com'
# start request
def start_requests(self):
yield SplashRequest(self.url, callback=self.parse, endpoint='execute', args={'lua_source': script, 'phone':'159*******', 'wait': 5})
# parse the html content
def parse(self, response):
info = response.css('div.op_mobilephone_r.c-gap-bottom-small').xpath('span/text()').extract()
print('='*40)
print(''.join(info))
print('='*40)
4. 运行爬虫,scrapy crawl phone, 结果如下:

实例展示到此结束,欢迎大家访问这个项目的Github地址: https://github.com/percent4/phoneSpider .当然,有什么问题,也可以载下面留言评论哦~~
Scrapy-Splash的介绍、安装以及实例的更多相关文章
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- scrapy splash 之一二
scrapy splash 用来爬取动态网页,其效果和scrapy selenium phantomjs一样,都是通过渲染js得到动态网页然后实现网页解析, selenium + phantomjs ...
- 一个完整的Installshield安装程序实例—艾泽拉斯之海洋女神出品(四) --高级设置二
原文:一个完整的Installshield安装程序实例-艾泽拉斯之海洋女神出品(四) --高级设置二 上一篇:一个完整的安装程序实例—艾泽拉斯之海洋女神出品(三) --高级设置一4. 根据用户选择的组 ...
- 爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍: 框架的简介和基础使用 持久化存储 代理和cookie 日志等级和请求传参 CrawlSpider 基于redis的分布式爬虫 一scrapy框架的简介和基础使用 a) ...
- 一个完整的Installshield安装程序实例-转
一个完整的Installshield安装程序实例—艾泽拉斯之海洋女神出品(一)---基本设置一 前言 Installshield可以说是最好的做安装程序的商业软件之一,不过因为功能的太过于强大,以至于 ...
- [转]一个完整的Installshield安装程序实例
@import url("http://files.cnblogs.com/files/go-jzg/vs.css"); --> Installshield安装程序实例—基本 ...
- scrapy+splash 爬取京东动态商品
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159 splash是容器安装的,从docker官网上下载windows下的 ...
- Scrapy学习1:安装
Install Scrapy 熟悉PyPI的话,直接一句 pip install Scrapy 但是有时候需要处理安装依赖,不能直接一句命令就安装结束,这个和系统有关. 我用的Ubuntu,这里仅介绍 ...
随机推荐
- Chapter3_操作符_直接常量和指数计数法
(1)直接常量 在程序中使用直接常量,相当于指导编译器,告诉它要生成什么样的类型,这样就不会产生模棱两可的情况.比如flaot a = 1f等,后缀表示告诉编译器想生成的类型.常用的后缀有l/L(lo ...
- Python从入门到精通之First!
Python的种类 Cpython Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上. Jy ...
- HNOI 2018 简要题解
寻宝游戏 毒瘤题. 估计考试只会前30pts30pts30pts暴力然后果断走人. 正解是考虑到一个数&1\&1&1和∣0|0∣0都没有变化,&0\&0& ...
- Oracle DBLINk的使用
Oracle中自带了DBLink功能,它的作用是将多个oracle数据库逻辑上看成一个数据库,也就是说在一个数据库中可以操作另一个数据库中的对象,例如我们新建了一个数据database1,我们需要操作 ...
- Hibernate 和 Mybatis 两者相比的优缺点
1.开发上手难度 hibernate的真正掌握(封装的功能和特性非常多)要比Mybatis来得难. 在真正产品级应用上要用Hibernate,不仅对开发人员的要求高,hibernate往往还不适合(多 ...
- 2017-2018-1 20155326信息安全系统设计基础》嵌入式C语言课上考试补交
2017-2018-1 20155326信息安全系统设计基础>嵌入式C语言课上考试补交 PPT上的例子 已知位运算规则为: &0 --> 清零 &1 --> 不变 | ...
- xampp/apache启动失败解决方法
我的问题是: 9:15:53 AM [Apache] Error: Apache shutdown unexpectedly.9:15:53 AM [Apache] This may be due ...
- Java学习笔记45(多线程二:安全问题以及解决原理)
线程安全问题以及解决原理: 多个线程用一个共享数据时候出现安全问题 一个经典案例: 电影院卖票,共有100座位,最多卖100张票,买票方式有多种,网上购买.自主售票机.排队购买 三种方式操作同一个共享 ...
- C#6.0语言规范(一) 介绍
C#(发音为“See Sharp”)是一种简单,现代,面向对象,类型安全的编程语言.C#源于C语言系列,对C,C ++和Java程序员来说很熟悉.EC#International将EC#标准化为ECM ...
- Docker - 配置DaoCloud的Docker加速器
由于众所周知的原因,从Docker Hub难以高效地下载镜像. 除了使用VPN或代理之外,最为有效的方式就是使用Docker国内镜像. DaoCloud是首个提供国内免费Docker Hub镜像的团体 ...