词向量可视化--[tensorflow , python]
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
----------------------------------
Version : ??
File Name : visual_vec.py
Description :
Author : xijun1
Email :
Date : 2018/12/25
-----------------------------------
Change Activiy : 2018/12/25
-----------------------------------
"""
__author__ = 'xijun1'
from tqdm import tqdm
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
import os
import codecs
words, embeddings = [], []
log_path = 'model'
with codecs.open('/Users/xxx/github/python_demo/vec.txt', 'r') as f:
header = f.readline()
vocab_size, vector_size = map(int, header.split())
for line in tqdm(range(vocab_size)):
word_list = f.readline().split(' ')
word = word_list[0]
vector = word_list[1:-1]
if word == "":
continue
words.append(word)
embeddings.append(np.array(vector))
assert len(words) == len(embeddings)
print(len(words))
with tf.Session() as sess:
X = tf.Variable([0.0], name='embedding')
place = tf.placeholder(tf.float32, shape=[len(words), vector_size])
set_x = tf.assign(X, place, validate_shape=False)
sess.run(tf.global_variables_initializer())
sess.run(set_x, feed_dict={place: embeddings})
with codecs.open(log_path + '/metadata.tsv', 'w') as f:
for word in tqdm(words):
f.write(word + '\n')
# with summary
summary_writer = tf.summary.FileWriter(log_path, sess.graph)
config = projector.ProjectorConfig()
embedding_conf = config.embeddings.add()
embedding_conf.tensor_name = 'embedding:0'
embedding_conf.metadata_path = os.path.join('metadata.tsv')
projector.visualize_embeddings(summary_writer, config)
# save
saver = tf.train.Saver()
saver.save(sess, os.path.join(log_path, "model.ckpt"))
结果:
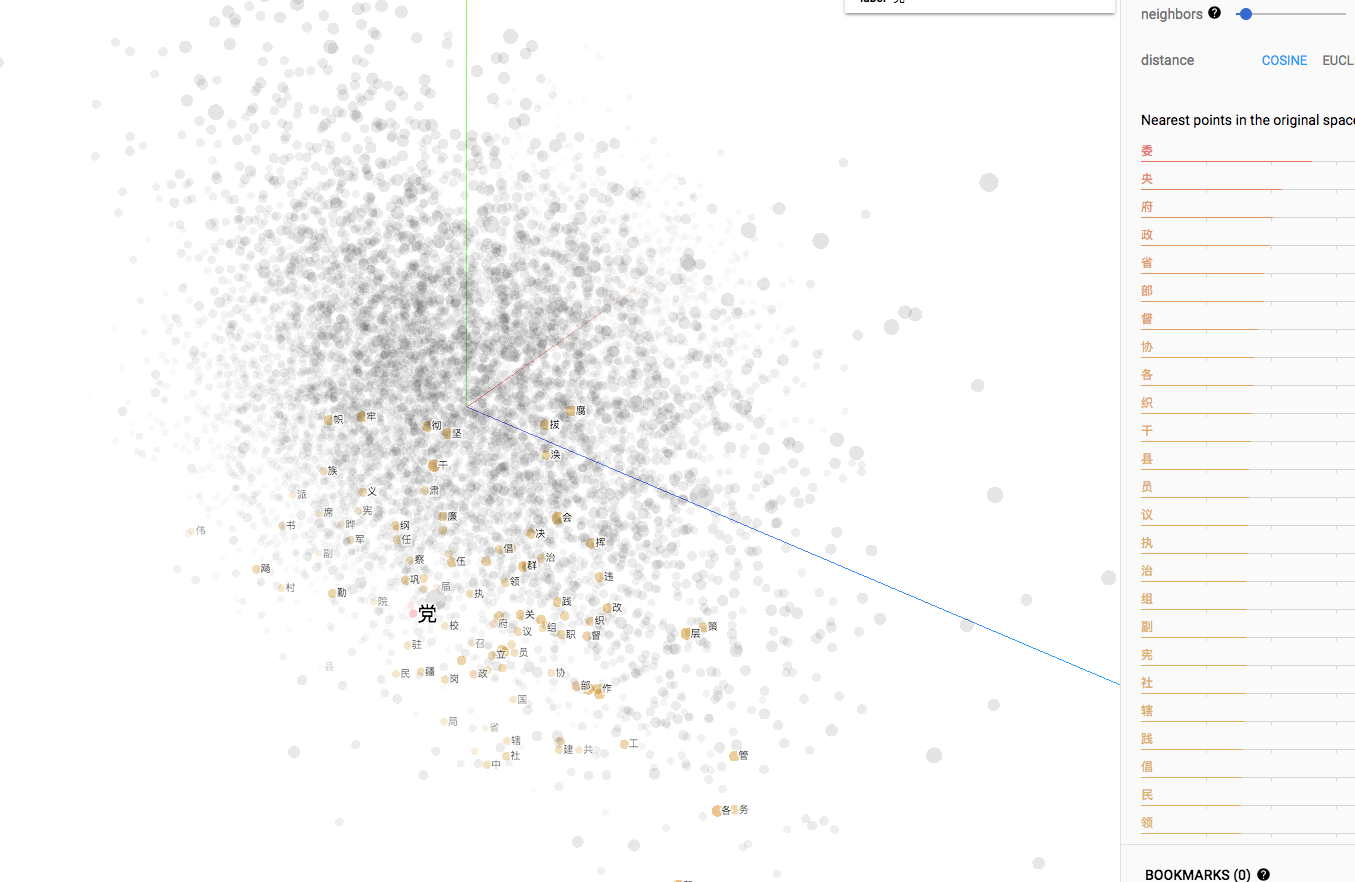
词向量可视化--[tensorflow , python]的更多相关文章
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 词向量模型word2vector详解
目录 前言 1.背景知识 1.1.词向量 1.2.one-hot模型 1.3.word2vec模型 1.3.1.单个单词到单个单词的例子 1.3.2.单个单词到单个单词的推导 2.CBOW模型 3.s ...
- NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)
R语言由于效率问题,实现自然语言处理的分析会受到一定的影响,如何提高效率以及提升词向量的精度是在当前软件环境下,比较需要解决的问题. 笔者认为还存在的问题有: 1.如何在R语言环境下,大规模语料提高运 ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- tensorflow如何正确加载预训练词向量
使用预训练词向量和随机初始化词向量的差异还是挺大的,现在说一说我使用预训练词向量的流程. 一.构建本语料的词汇表,作为我的基础词汇 二.遍历该词汇表,从预训练词向量中提取出该词对应的词向量 三.初始化 ...
- gensim的word2vec如何得出词向量(python)
首先需要具备gensim包,然后需要一个语料库用来训练,这里用到的是skip-gram或CBOW方法,具体细节可以去查查相关资料,这两种方法大致上就是把意思相近的词映射到词空间中相近的位置. 语料库t ...
- 用Python做词云可视化带你分析海贼王、火影和死神三大经典动漫
对于动漫爱好者来说,海贼王.火影.死神三大动漫神作你肯定肯定不陌生了.小编身边很多的同事仍然深爱着这些经典神作,可见"中毒"至深.今天小编利用Python大法带大家分析一下这些神作 ...
- 机器学习之路: python 实践 word2vec 词向量技术
git: https://github.com/linyi0604/MachineLearning 词向量技术 Word2Vec 每个连续词汇片段都会对后面有一定制约 称为上下文context 找到句 ...
随机推荐
- springmvc接受前端的参数封装成对象
前端如果传过来的是json格式的字符串,后台参数需要加@RequestBody注解. 前端如果传过来的是json对象,后台不参数需要加@RequestBody注解. $.POST({ url: url ...
- lvs负载均衡概述
- html 知识点
web服务本质 import socket def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind ...
- 使用Nginx部署静态网站
这篇文章将介绍如何利用Nginx部署静态网站. 之前写过2篇有关Nginx的文章,一篇是<利用nginx,腾讯云免费证书制作https>,另外一篇是<linux安装nginx> ...
- 学习DRF之前
在学习DRF之前~我们要先复习一些知识点~~ FBV和CBV的区别 学习Django的时候~我们已经了解过CBV以及FBV 什么是FBV和CBV呢~~ FBV 基于函数的视图 CBV 基于类的视图 也 ...
- 利用"SQL"语句自动生成序号的两种方式
1.首先,我们来介绍第一种方式: ◆查询的SQL语句如下: select row_number() over (order by name) as rowid, sysobjects.[id] fro ...
- 20172310 实验四 Android程序设计
20172310 2017-2018-2 <程序设计与数据结构>实验四报告 课程:<程序设计与数据结构> 班级: 1723 姓名: 仇夏 学号:20172310 实验教师:王志 ...
- Celery框架
在学习Celery之前,我先简单的去了解了一下什么是生产者消费者模式. 生产者消费者模式 在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是 ...
- CSS元素定位
使用 CSS 选择器定位元素 CSS可以通过元素的id.class.标签(input)这三个常规属性直接定位到,而这三种编写方式,在HTML中编写style的时候,可以进行标识如: #su ...
- cookies和session
基于cookies做用户验证时,敏感信息不适合放在cookies中 cookies保存在客户浏览器端的键值对 session保存在服务器端的键值对(依赖于cookies),把用户浏览器中的cook ...