词向量可视化--[tensorflow , python]
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
----------------------------------
Version : ??
File Name : visual_vec.py
Description :
Author : xijun1
Email :
Date : 2018/12/25
-----------------------------------
Change Activiy : 2018/12/25
-----------------------------------
"""
__author__ = 'xijun1'
from tqdm import tqdm
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
import os
import codecs
words, embeddings = [], []
log_path = 'model'
with codecs.open('/Users/xxx/github/python_demo/vec.txt', 'r') as f:
header = f.readline()
vocab_size, vector_size = map(int, header.split())
for line in tqdm(range(vocab_size)):
word_list = f.readline().split(' ')
word = word_list[0]
vector = word_list[1:-1]
if word == "":
continue
words.append(word)
embeddings.append(np.array(vector))
assert len(words) == len(embeddings)
print(len(words))
with tf.Session() as sess:
X = tf.Variable([0.0], name='embedding')
place = tf.placeholder(tf.float32, shape=[len(words), vector_size])
set_x = tf.assign(X, place, validate_shape=False)
sess.run(tf.global_variables_initializer())
sess.run(set_x, feed_dict={place: embeddings})
with codecs.open(log_path + '/metadata.tsv', 'w') as f:
for word in tqdm(words):
f.write(word + '\n')
# with summary
summary_writer = tf.summary.FileWriter(log_path, sess.graph)
config = projector.ProjectorConfig()
embedding_conf = config.embeddings.add()
embedding_conf.tensor_name = 'embedding:0'
embedding_conf.metadata_path = os.path.join('metadata.tsv')
projector.visualize_embeddings(summary_writer, config)
# save
saver = tf.train.Saver()
saver.save(sess, os.path.join(log_path, "model.ckpt"))
结果:
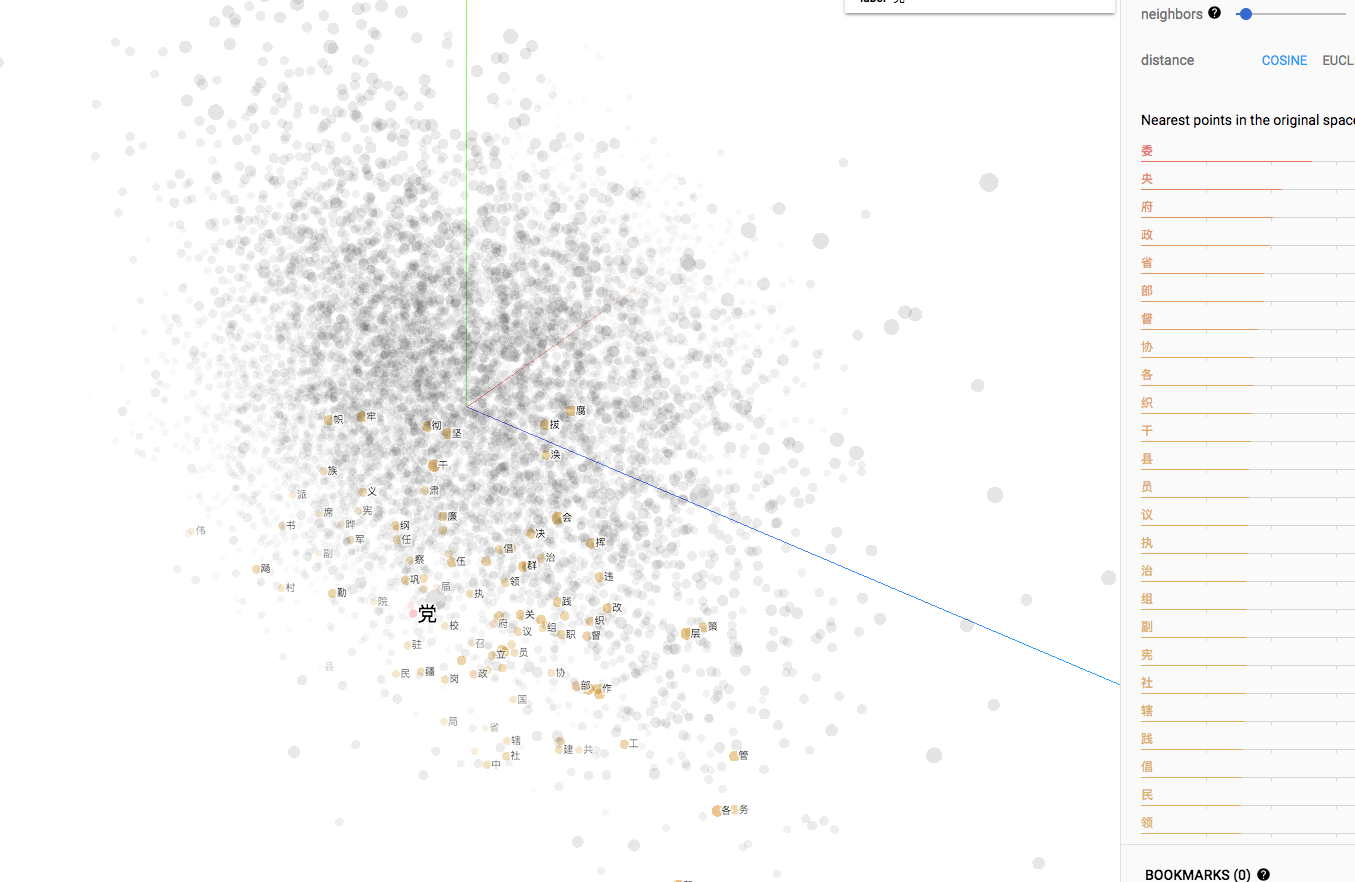
词向量可视化--[tensorflow , python]的更多相关文章
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 词向量模型word2vector详解
目录 前言 1.背景知识 1.1.词向量 1.2.one-hot模型 1.3.word2vec模型 1.3.1.单个单词到单个单词的例子 1.3.2.单个单词到单个单词的推导 2.CBOW模型 3.s ...
- NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)
R语言由于效率问题,实现自然语言处理的分析会受到一定的影响,如何提高效率以及提升词向量的精度是在当前软件环境下,比较需要解决的问题. 笔者认为还存在的问题有: 1.如何在R语言环境下,大规模语料提高运 ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- tensorflow如何正确加载预训练词向量
使用预训练词向量和随机初始化词向量的差异还是挺大的,现在说一说我使用预训练词向量的流程. 一.构建本语料的词汇表,作为我的基础词汇 二.遍历该词汇表,从预训练词向量中提取出该词对应的词向量 三.初始化 ...
- gensim的word2vec如何得出词向量(python)
首先需要具备gensim包,然后需要一个语料库用来训练,这里用到的是skip-gram或CBOW方法,具体细节可以去查查相关资料,这两种方法大致上就是把意思相近的词映射到词空间中相近的位置. 语料库t ...
- 用Python做词云可视化带你分析海贼王、火影和死神三大经典动漫
对于动漫爱好者来说,海贼王.火影.死神三大动漫神作你肯定肯定不陌生了.小编身边很多的同事仍然深爱着这些经典神作,可见"中毒"至深.今天小编利用Python大法带大家分析一下这些神作 ...
- 机器学习之路: python 实践 word2vec 词向量技术
git: https://github.com/linyi0604/MachineLearning 词向量技术 Word2Vec 每个连续词汇片段都会对后面有一定制约 称为上下文context 找到句 ...
随机推荐
- c#一步一步实现ORM
本篇适合新手了解学习orm.欢迎指正,交流学习. 现有的优秀的orm有很多. EF:特点是高度自动化,缺点是有点重. Nhibnate:缺点是要写很多的配置. drapper:最快的orm.但是自动化 ...
- CISCO ACL配置(目前)
什么是ACL? 访问控制列表简称为ACL,访问控制列表使用包过滤技术,在路由器上读取第三层及第四层包头中的信息如源地址,目的地址,源端口,目的端口等,根据预先定义好的规则对包进行过滤,从而达到访问控制 ...
- Mybatis之注解实现动态sql
通过注解实现动态sql一共需要三部:1.创建表,2.创建entity类,3.创建mapper类, 4.创建动态sql的Provider类.1.和2.可以参见该系列其他文章,这里主要对3和4进行演示,并 ...
- 项目部署相关命令(pm2)
普通方式启动后台服务: nohup npm start & 关闭服务,需要找到进程号: lsof -i :3000 kill -9 进程号 通过pm2启动项目,可实现关闭自启动: 安装pm2: ...
- SpringBoot使用Jsp
本文是简单总结一下SpringBoot使用Jsp的Demo. 前言 在早期做项目的时候,JSP是我们经常使用的java服务器页面,其实就是一个简化servlet的设计,在本文开始之前,回顾一下jsp的 ...
- UVA 220 Othello
题意:输入n,代表次数,每次输入8*8的棋盘,处理3种命令:①L:打印所有合法操作,②M:放棋子,③Q:打印棋盘然后退出. 思路:①用字符数组存棋盘,整型数组存合法位置. ②查找的方法:当前玩家为cu ...
- Emgucv - 下载、安装、配置
工欲善其事,必先利其器. 一.下载 Emgucv学习之前,我们先要搭建好开发环-Emgucv库.VS开发平台. (1)VS开发平台,个人觉得VS2015挺好用的,比如:自定义窗口布局.更优的代码编辑器 ...
- Hass.io: add-on Samba
{ "workgroup": "WORKGROUP", "name": "hassio", "guest&qu ...
- BZOJ1897 : tank 坦克游戏
设$f[i][j][k]$表示坦克位于$(i,j)$,目前打了不超过$k$个位置的最大得分. 初始值$f[1][1][k]$为在$(1,1)$射程内最大$k$个位置的分数总和. 对于每次移动,会新增一 ...
- [UVA227][ACM/ICPC WF 1993]Puzzle (恶心模拟)
各位大佬都好厉害…… 这个ACM/ICPC1993总决赛算黄题%%% 我个人认为至少要绿题. 虽然算法上面不是要求很大 但是操作模拟是真的恶心…… 主要是输入输出的难. 对于ABLR只需要模拟即可 遇 ...