Hadoop基础-配置历史服务器
Hadoop基础-配置历史服务器
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过Hadoop自带的命令(mr-jobhistory-daemon.sh)来启动Hadoop历史服务器。
一.yarn上运行mr程序
1>.启动集群
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
ResourceManager
NameNode
Jps
DFSZKFailoverController
命令执行成功
============= s102 jps ============
DataNode
JournalNode
NodeManager
Jps
QuorumPeerMain
命令执行成功
============= s103 jps ============
DataNode
JournalNode
NodeManager
QuorumPeerMain
Jps
命令执行成功
============= s104 jps ============
NodeManager
Jps
QuorumPeerMain
DataNode
JournalNode
命令执行成功
============= s105 jps ============
Jps
NameNode
DFSZKFailoverController
命令执行成功
[yinzhengjie@s101 ~]$
2>.在yarn上执行MapReduce程序
[yinzhengjie@s101 ~]$ hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /yinzhengjie/data/ /yinzhengjie/data/output
// :: INFO client.RMProxy: Connecting to ResourceManager at s101/172.30.1.101:
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1534851274873_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1534851274873_0001
// :: INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1534851274873_0001/
// :: INFO mapreduce.Job: Running job: job_1534851274873_0001
// :: INFO mapreduce.Job: Job job_1534851274873_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1534851274873_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[yinzhengjie@s101 ~]$
3>.通过webUI查看hdfs是否有数据产生
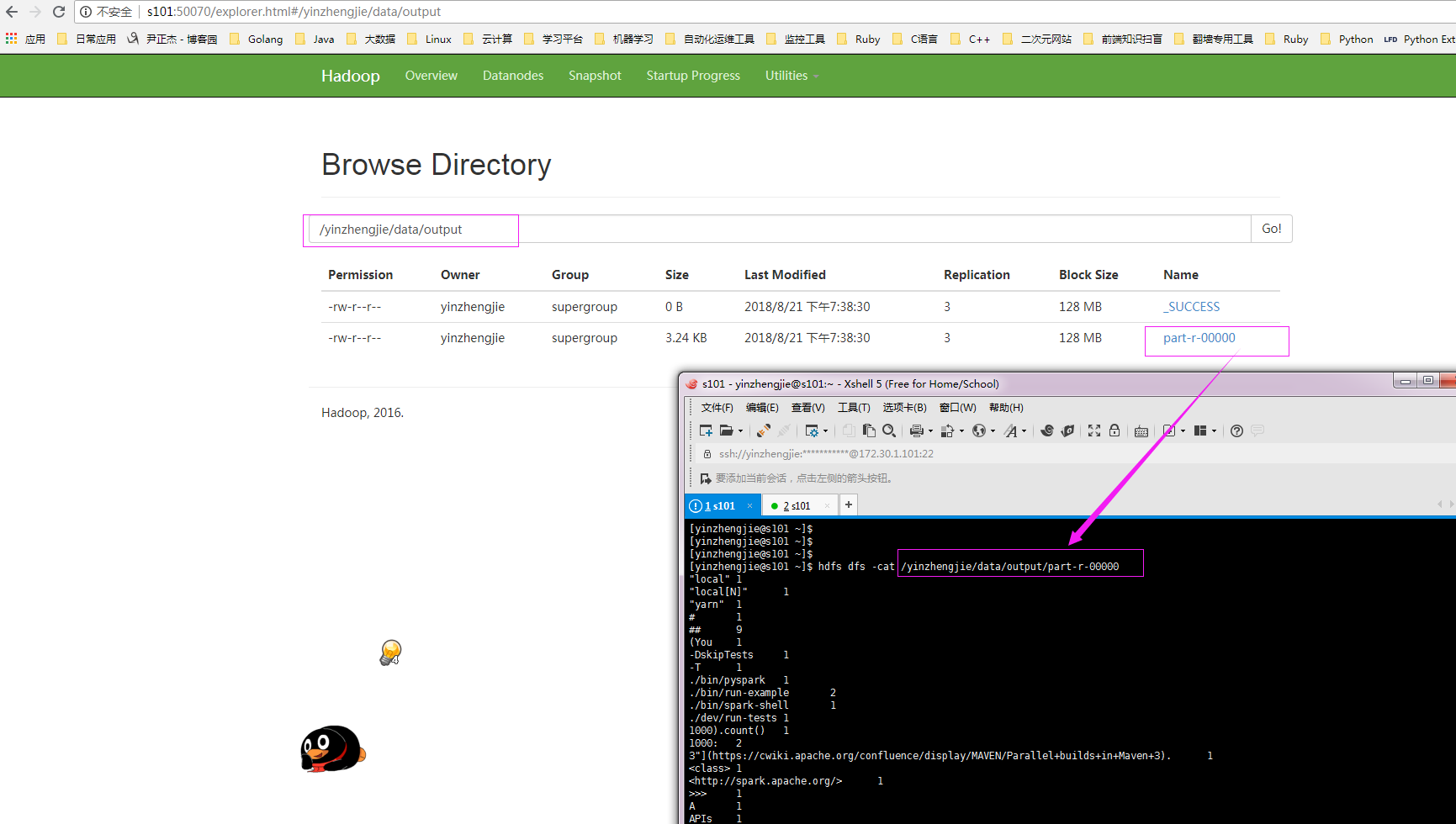
4>.查看yarn的记录信息
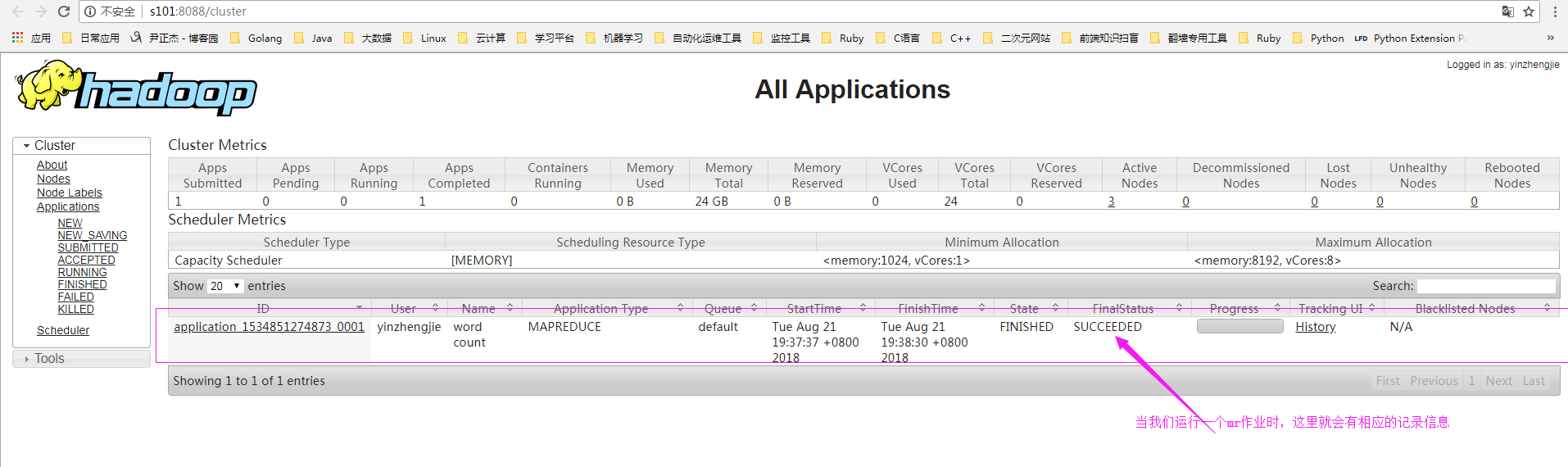
5>.查看历史日志,发现无法访问
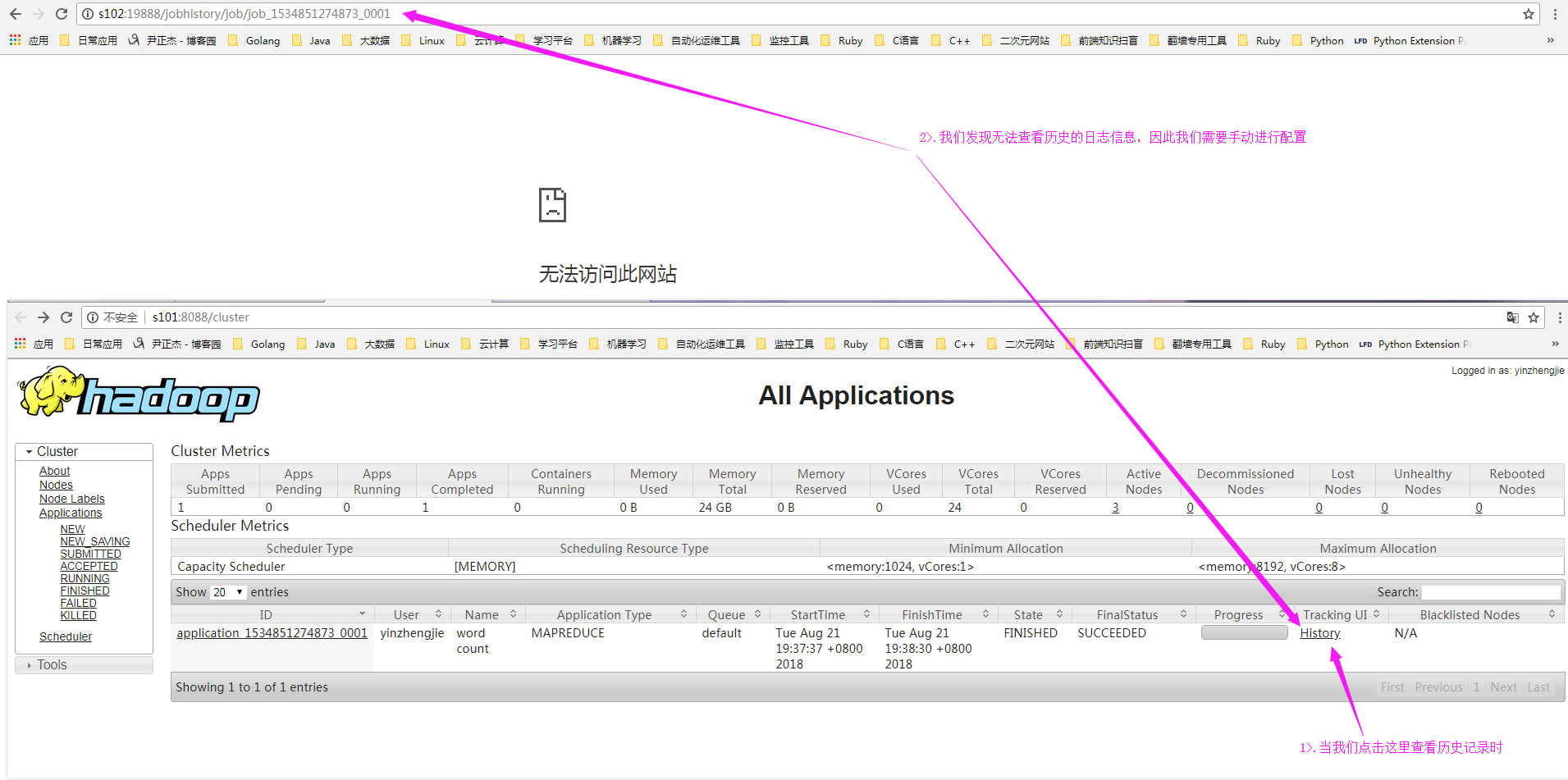
二.配置yarn历史服务器
1>.修改“mapred-site.xml”配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>s101:10020</value>
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>s101:19888</value>
</property> <property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/done</value>
</property> <property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/done_intermediate</value>
</property> <property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/yinzhengjie/logs/hdfs/history</value>
</property> </configuration> <!--
mapred-site.xml 配置文件的作用:
#HDFS的相关设定,如reduce任务的默认个数、任务所能够使用内存
的默认上下限等,此中的参数定义会覆盖mapred-default.xml文件中的
默认配置. mapreduce.framework.name 参数的作用:
#指定MapReduce的计算框架,有三种可选,第一种:local(本地),第
二种是classic(hadoop一代执行框架),第三种是yarn(二代执行框架),我
们这里配置用目前版本最新的计算框架yarn即可。 mapreduce.jobhistory.address 参数的作用:
#指定job的历史服务器 mapreduce.jobhistory.webapp.address 参数的作用:
#指定日志服务器的web访问端口 mapreduce.jobhistory.done-dir 参数的作用:
#指定存放已经运行完的Hadoop作业记录 mapreduce.jobhistory.intermediate-done-dir 参数的作用:
#指定正在运行的Hadoop作业记录 yarn.app.mapreduce.am.staging-dir 参数的作用:
#指定applicationID以及需要的jar包文件等 -->
[yinzhengjie@s101 ~]$
2>.启动历史服务器服务
[yinzhengjie@s101 ~]$ hdfs dfs -mkdir /yinzhengjie/logs/hdfs/history #创建存放历史日志的路径
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ mr-jobhistory-daemon.sh start historyserver #启动历史服务
starting historyserver, logging to /soft/hadoop-2.7./logs/mapred-yinzhengjie-historyserver-s101.out
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ jps
ResourceManager
JobHistoryServer #注意,这个进程就是历史服务进程
NameNode
Jps
DFSZKFailoverController
[yinzhengjie@s101 ~]$
3>.在yarn上执行MapReduce程序
[yinzhengjie@s101 ~]$ hdfs dfs -rm -R /yinzhengjie/data/output #删除之前的输出路径
// :: INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = minutes, Emptier interval = minutes.
Deleted /yinzhengjie/data/output
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /yinzhengjie/data/input /yinzhengjie/data/output
// :: INFO client.RMProxy: Connecting to ResourceManager at s101/172.30.1.101:
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1534851274873_0002
// :: INFO impl.YarnClientImpl: Submitted application application_1534851274873_0002
// :: INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1534851274873_0002/
// :: INFO mapreduce.Job: Running job: job_1534851274873_0002
// :: INFO mapreduce.Job: Job job_1534851274873_0002 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1534851274873_0002 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[yinzhengjie@s101 ~]$
4>.通过webUI查看hdfs是否有数据产生
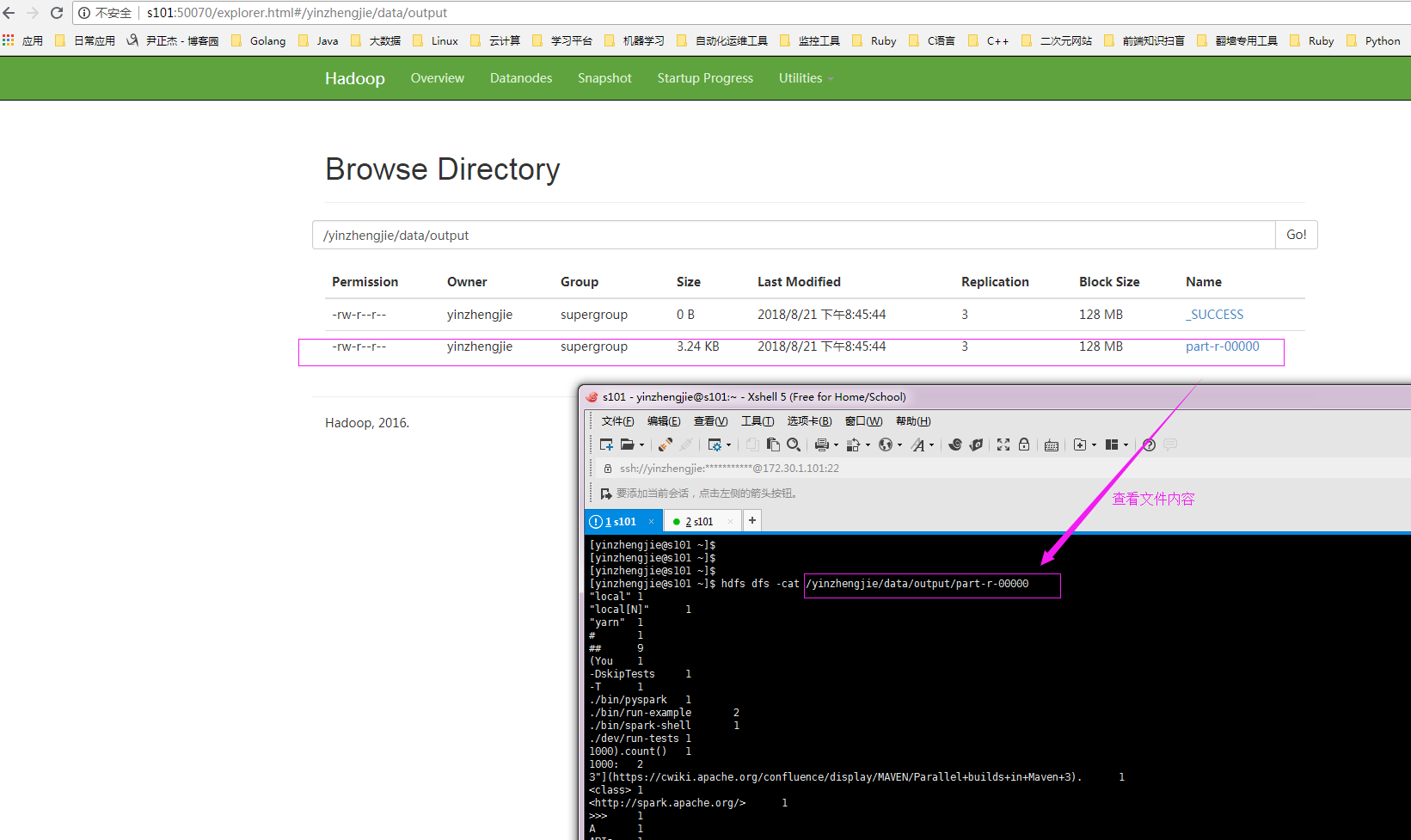
5>.查看yarn的webUI的历史任务

6>.查看历史记录
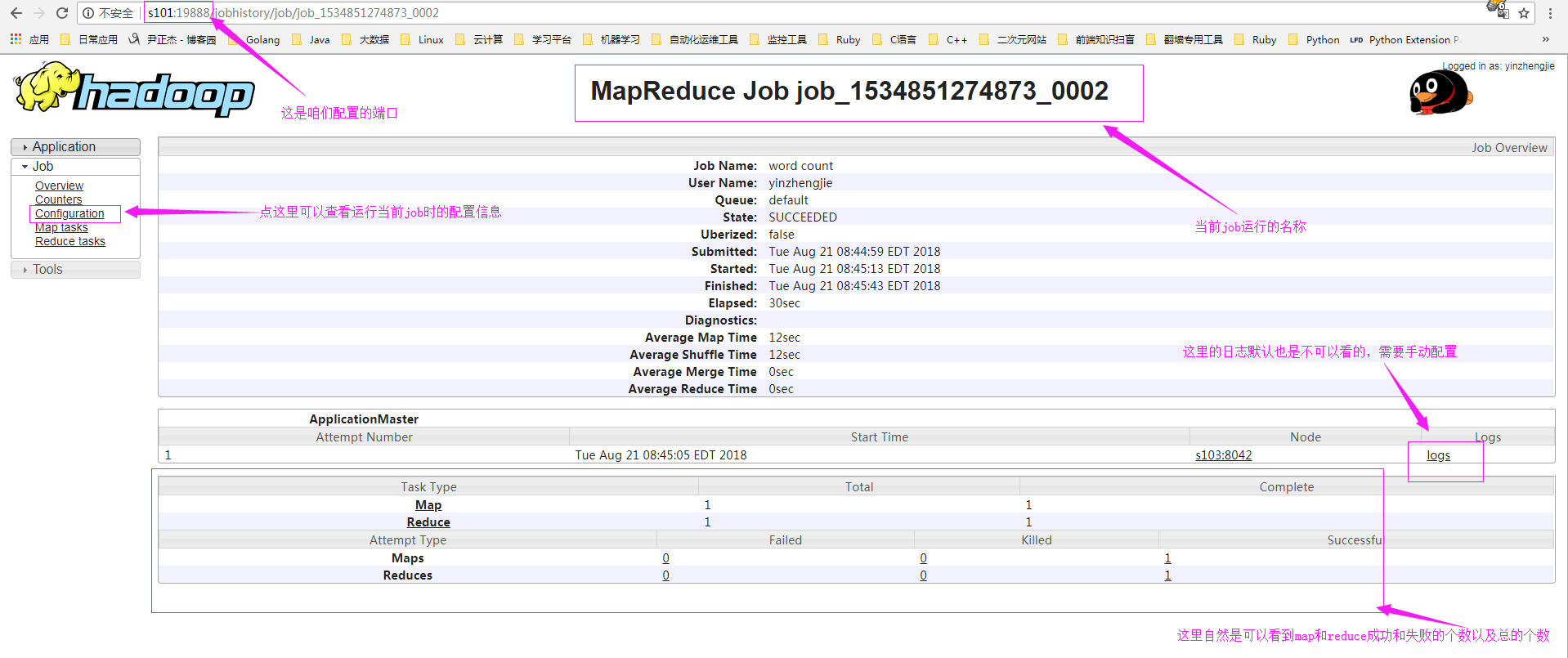
7>.配置日志聚集功能
详情请参考:https://www.cnblogs.com/yinzhengjie/p/9471921.html
Hadoop基础-配置历史服务器的更多相关文章
- hadoop配置历史服务器&&配置日志聚集
配置历史服务器 1.在mapred-site.xml中写入一下配置 <property> <name>mapreduce.jobhistory.address</name ...
- hadoop配置历史服务器
此文档不建议当教程,仅供参考 配置历史服务器 我是在hadoop1机器上配置的 配置mapred-site.xml <property> <name>mapreduce.job ...
- hadoop 3.x 配置历史服务器
修改$HADOOP_HOME/etc/hadoop/mapred-site.xml,加入以下配置(修改主机名为你自己的主机或IP,尽量不要使用中文注释) <!--history address- ...
- 零基础配置Linux服务器环境
详细步骤请走官方通道 over!over!over!
- Hadoop jobhistory历史服务器
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map.用了多少个Reduce.作业提交时间.作业启动时间.作业完成时间等信息.默认情况下 ...
- 【转载】Hadoop历史服务器详解
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:过往记忆(http://www.iteblog.com/) 原文地址: ...
- linux系统ansible一键完成三大服务器基础配置(剧本)
ansible自动化管理剧本方式一键完成三大服务器基础配置 环境准备:五台服务器:管理机m01:172.16.1.61,两台web服务器172.16.1.7,172.16.1.8,nfs存储服务器17 ...
- hadoop中的Jobhistory历史服务器
1. 启动脚本 mr-jobhistory-daemon.sh start historyserver 2. 配置说明 jobhistory用于查询每个job运行完以后的历史日志信息,是作为一台单独 ...
- 大数据专栏 - 基础1 Hadoop安装配置
Hadoop安装配置 环境 1, JDK8 --> 位置: /opt/jdk8 2, Hadoop2.10: --> 位置: /opt/bigdata/hadoop210 3, CentO ...
随机推荐
- 《Linux内核分析》 期中总结
Linux内核分析 期中总结 20135307 张嘉琪 一.Linux内核分析课程总结 学习笔记汇总 第一节 计算机是如何工作的 第二节 操作系统是如何工作的 第三节 构造一个简单的Linux系统Me ...
- 小学生四则运算App实验成果
组名:会飞的小鸟 组员:徐侃 陈志棚 罗伟业 刘芮熔 成员分工: ①刘芮熔:设置安卓包.界面的代码,界面的排序. ②陈志棚:加减乘除的判断异常处理,例如除数不能为零的异常处理等问题. ③徐侃 ...
- 第三个Sprint冲刺第3天
成员:罗凯旋.罗林杰.吴伟锋.黎文衷 组内各成员加紧完成自己的工作.
- Particle filter for visual tracking
Kalman Filter Cons: Kalman filtering is inadequate because it is based on the unimodal Gaussian dist ...
- 正则表达式(java)
概念: 正则表达式,又称规则表达式.(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念. 正则表通常被用来检索.替换那些符合某个模式( ...
- pcntl php多进程
<?php $i=0;while($i!=5){ $pid = pcntl_fork(); if ($pid == 0) { echo $pid."---------hahah&quo ...
- [转载] Oracle在windows下面的自动备份以及删除今天的脚本..
@echo off echo ================================================ echo Windows环境下Oracle数据库的自动备份脚本 echo ...
- pandas聚合aggregate
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/5/24 15:03 # @Author : zhang chao # @Fi ...
- MySQL中char、varchar和nvarchar的区别
一.char和varchar的区别char是固定长度的,而varchar会根据具体的长度来使用存储空间,另外varchar需要用额外的1-2个字节存储字符串长度.1). 当字符串长度小于255时,用额 ...
- HDU - 4725 (The Shortest Path in Nya Graph)层次网络
题意:有n个点,每个点都在一个层内,层与层之间的距离为c,一个层内的点可以到达与它相邻的前后两个层的点,还有m条小路 ..时间真的是卡的很恶心啊... 借一下别人的思路思路: 这题主要难在建图上,要将 ...