大数据专栏 - 基础1 Hadoop安装配置
Hadoop安装配置
环境
1, JDK8 --> 位置: /opt/jdk8
2, Hadoop2.10: --> 位置: /opt/bigdata/hadoop210
3, CentOS 7虚拟机试验集群规划
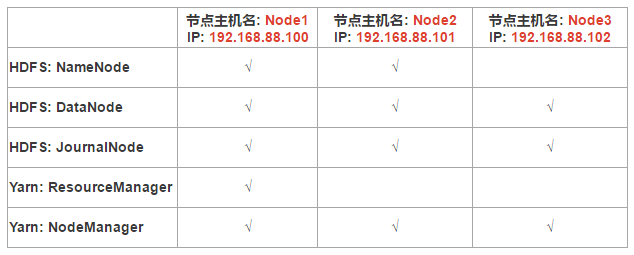
一,安装步骤
1, 解压缩
cd /opt/bigdata
tar -zxvf hadoop-2.10.1.tar.gz
mv ./hadoop-2.10.1 hadoop210
2, 配置
cd /opt/bigdata/hadoop210/etc/hadoop/
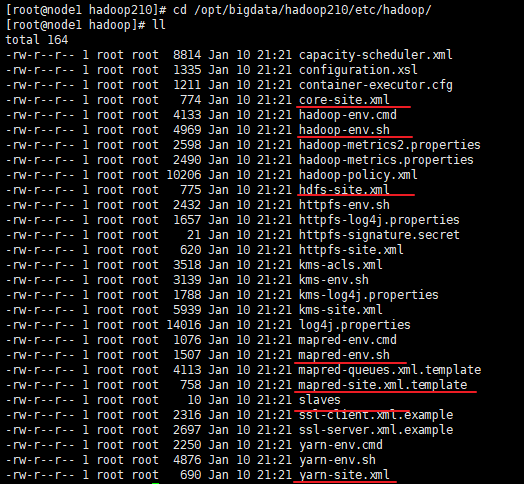
2.1 修改hadoop-env.sh
[root@node1 hadoop27]# echo $JAVA_HOME
/opt/jdk8
vim hadoop-env.sh
export JAVA_HOME=/opt/jdk8
2.2 修改core-site.xml
[root@node1 hadoop210]# pwd
/opt/bigdata/hadoop210
[root@node1 hadoop210]# mkdir hadoopDatas
[root@node1 hadoop210]# cd /opt/bigdata/hadoop210/etc/hadoop/
[root@node1 hadoop210]# vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop210/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
2.3 修改hdfs-site.xml
[root@node1 hadoop]# cd /opt/bigdata/hadoop210/etc/hadoop/
[root@node1 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
2.4 修改yarn-site.xml
[root@node1 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
2.5 修改mapred-env.sh
[root@node1 hadoop]# vi mapred-env.sh
export JAVA_HOME=/opt/jdk8
2.6 修改mapred-site.xml
[root@node1 hadoop]# mv mapred-site.xml.template ./mapred-site.xml
[root@node1 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
2.7 修改slaves
[root@node1 hadoop]# vi slaves
node1
node2
node3
2.8 配置Hadoop环境变量
[root@node1 hadoop]# vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop210
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$FINDBUGS_HOME/bin:$MAVEN_HOME/bin:$JAVA_HOME/bin:$PATH
[root@node1 hadoop]# source /etc/profile
2.9 分发安装包
[root@node1 hadoop210]# cd /opt/bigdata/hadoop210/
[root@node1 hadoop210]# scp -r hadoop210 node2:$PWD
[root@node1 hadoop210]# scp -r hadoop210 node3:$PWD
[root@node1 hadoop210]# scp /etc/profile node2:/etc/
[root@node1 hadoop210]# scp /etc/profile node3:/etc/
分别在node2,node3节点机器执行以下命令: 刷新加载/etc/profile
source /etc/profile
3, 启动集群
前提: 3台机器上安装好了zookeeper, 并启动
zkServer.sh start
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。 注意: 首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和 准备工作,因为此时的 HDFS 在物理上还是不存在的。
在node1节点机器执行以下命令
[root@node1 bigdata]# hdfs namenode -format
[root@node1 bigdata]# start-dfs.sh

[root@node1 bigdata]# start-yarn.sh

[root@node1 bigdata]# mr-jobhistory-daemon.sh start historyserver

启动完成之后, 可以通过jsp查看
大数据专栏 - 基础1 Hadoop安装配置的更多相关文章
- 大数据笔记13:Hadoop安装之Hadoop的配置安装
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据入门基础系列之Hadoop1.X、Hadoop2.X和Hadoop3.X的多维度区别详解(博主推荐)
不多说,直接上干货! 在前面的博文里,我已经介绍了 大数据入门基础系列之Linux操作系统简介与选择 大数据入门基础系列之虚拟机的下载.安装详解 大数据入门基础系列之Linux的安装详解 大数据入门基 ...
随机推荐
- 十. Axios网络请求封装
1. 网络模块的选择 Vue中发送网络请求有非常多的方式,那么在开发中如何选择呢? 选择一:传统的Ajax是基于XMLHttpRequest(XHR) 为什么不用它呢?非常好解释配置和调用方式等非常混 ...
- 利用IDEA把Java项目打成jar包
第一步:按如下步骤或Ctrl+Shift+Alt+S打开 Project Structure第二步:第三步:选择要执行的文件, 依次选择项目, main方法所在的文件, 保存如果出现以下错误:则根据 ...
- react-admin-plus 正式开源, 欢迎star
简介 基于react.ant-ui.typescript的前端微服务框架.欢迎star. 在线地址 在线demo 项目介绍 沉淀了几个月的时间,这款框架终于正式的和大家见面了! 先说一下我做这 ...
- 写了两年的一本.NET书现在终于在北京最大的新华书店上架了,然而我却很难找到工作了。
两年前,有几个出版社的编辑在QQ上跟我联系写书的事情,好奇为什么出版社会找到我这样一个很普通的.NET技术人员,其中一个编辑说他们分析了很多博客园博主的文章阅读量和写作质量,觉得我的博客还是不错的.尽 ...
- Angular学习知识点记录
问:版本直接跳转到Angular4? 答:为了遵循严格的版本策略.在angular2.x的时候,angular route的版本已经是版本3了.因此为了版本统一,angular直接从2跳到了4,.参考 ...
- 精尽Spring MVC源码分析 - 寻找遗失的 web.xml
该系列文档是本人在学习 Spring MVC 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释 Spring MVC 源码分析 GitHub 地址 进行阅读 Spring 版本:5.2. ...
- uniapp中使用picker中的注意事项
APP端中picker点击后不弹出: 1.请确保picker标签里面嵌套了一个view,并且view里面有值 2.请确保picker中的默认值的格式跟该picker类型的值对应 例如下面: <v ...
- jmeter__问题记录,中文乱码问题(json参数化)
这种情况在jmeter3.0的版本中才会产生,注意:这不是乱码,而是由于3.0中优化body data后,使用默认的字体(Consolas)不支持汉字的显示.这样的情况可以这样调整:进入jmeter. ...
- MySQL锁(三)行锁:幻读是什么?如何解决幻读?
概述 前面两篇文章介绍了MySQL的全局锁和表级锁,今天就介绍一下MySQL的行锁. MySQL的行锁是各个引擎内部实现的,不是所有的引擎支持行锁,例如MyISAM就不支持行锁. 不支持行锁就意味着在 ...
- 图解Janusgraph系列-图数据底层序列化源码分析(Data Serialize)
图解Janusgraph系列-图数据底层序列化源码分析(Data Serialize) 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步 ...