GBDT用于分类问题
一、简介
GBDT在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个
一:效果确实挺不错。
二:既可以用于分类也可以用于回归。
三:可以筛选特征。
这三点实在是太吸引人了,导致在面试的时候大家也非常喜欢问这个算法。
GBDT是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
GBDT通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度。
二、GBDT如何用于分类的
第一步:训练的时候,是针对样本 X 每个可能的类都训练一个分类回归树。如目前的训练集共有三类,即K = 3,样本x属于第二类,那么针对样本x的分类结果,我们可以用一个三维向量\([0, 1, 0]\)来表示,0表示不属于该类,1表示属于该类,由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。
针对样本有三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入是\((x,0)\),第二颗树针对样本x的第二类,输入是\((x,1)\),第三颗树针对样本x的第三类,输入是\((x,0)\)。
在对样本x训练后产生三颗树,对x 类别的预测值分别是\(f_1(x),f_2(x),f_3(x)\),那么在此类训练中,样本x属于第一类,第二类,第三类的概率分别是:
\(P_1(x) = exp(f_1(x))/\sum_{k=1}^{3}exp(f_k(x))\)
\(P_2(x) = exp(f_2(x))/\sum_{k=1}^{3}exp(f_k(x))\)
\(P_3(x) = exp(f_3(x))/\sum_{k=1}^{3}exp(f_k(x))\)
然后可以求出针对第一类,第二类,第三类的残差分别是:
\(y_{11} = 0 - P_1(x)\)
\(y_{22} = 1 - P_2(x)\)
\(y_{33} = 0 - P_3(x)\)
然后开始第二轮训练,针对第一类输入为\((x,y_{11}(x))\),针对第二类输入为\((x,y_{22}(x))\),针对第三类输入为\((x,y_{33}(x))\),继续训练出三颗树。一直迭代M轮,每轮构建三棵树
当训练完毕以后,新来一个样本\(x_1\),我们需要预测该样本的类别的时候,便产生三个值\(f_1(x),f_2(x),f_3(x)\),则样本属于某个类别c的概率为:
\(P_c(x) = exp(f_c(x))/\sum_{k=1}^{3}exp(f_k(x))\)
三、GBDT 多分类举例说明
下面以Iris数据集的六个数据为例来展示GBDT多分类的过程

具体应用到gbdt多分类算法。我们用一个三维向量来标志样本的label,\([1, 0, 0]\)表示样本属于山鸢尾,\([0, 1, 0]\)表示样本属于杂色鸢尾,\([0, 0, 1]\)表示属于维吉尼亚鸢尾。
gbdt 的多分类是针对每个类都独立训练一个 CART Tree。所以这里,我们将针对山鸢尾类别训练一个 CART Tree 1。杂色鸢尾训练一个 CART Tree 2 。维吉尼亚鸢尾训练一个CART Tree 3,这三个树相互独立。
我们以样本1为例:
针对CART Tree1 的训练样本是\([5.1, 3.5, 1.4, 0.2]\),label是1,模型输入为\([5.1, 3.5, 1.4, 0.2, 1]\)
针对CART Tree2 的训练样本是\([5.1, 3.5, 1.4, 0.2]\),label是0,模型输入为\([5.1, 3.5, 1.4, 0.2, 0]\)
针对CART Tree3 的训练样本是\([5.1, 3.5, 1.4, 0.2]\),label是0,模型输入为\([5.1, 3.5, 1.4, 0.2, 0]\)
下面我们来看 CART Tree1 是如何生成的,其他树 CART Tree2 , CART Tree 3的生成方式是一样的。CART Tree的生成过程是从这四个特征中找一个特征做为CART Tree1 的节点。
比如花萼长度做为节点。6个样本当中花萼长度大于等于5.1 cm的就是 A类,小于 5.1 cm 的是B类。生成的过程其实非常简单,问题 1.是哪个特征最合适? 2.是这个特征的什么特征值作为切分点?
即使我们已经确定了花萼长度做为节点。花萼长度本身也有很多值。在这里我们的方式是遍历所有的可能性,找到一个最好的特征和它对应的最优特征值可以让当前式子的值最小:

我们以第一个特征的第一个特征值为例。R1为所有样本中花萼长度小于5.1cm的样本集合,R2为所有样本中花萼长度大于等于5.1cm的样本集合,所以\(R_1 = [2],R_2 = [1, 3, 4, 5, 6]\)
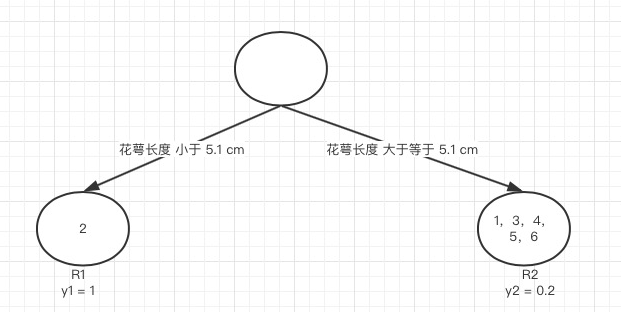
\(y_1\)为R1所有样本label的均值:\(1/1=1\),\(y_2\)为R2所有样本label的均值:
\((1+0+0+0+0)/5 = 0.2\)
下面计算损失函数的值,采用平方误差,分别计算R1和R2的误差平方和,样本2属于R1的误差:\((1-1)^2 = 0\),样本1,3,4,5,6属于R2的误差和:
\((1-0.2)^2 + (0-0.2)^2 + (0-0.2)^2 + (0-0.2)^2 + (0-0.2)^2 = 0.8\)
接着我们计算第一个特征的第二个特征值,即R1为所有样本中花萼长度小于 4.9 cm 的样本集合,R2 为所有样本当中花萼长度大于等于4.9 cm 的样本集合,\(R1 = [], R2 = [1,2,3,4,5,6]\),\(y_1\)为R1所有样本label的均值:0,\(y_2\)为R2所有样本label的均值:\((1+1+0+0+0+0)/6 = 0.3333\):
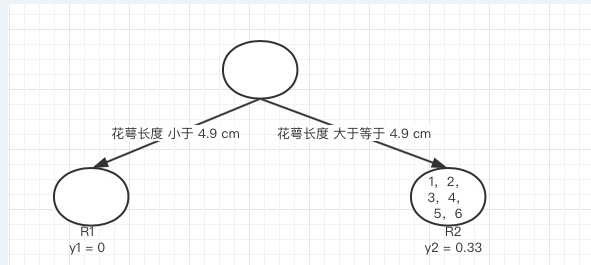
计算所有样本的损失值,样本1和2属于R2,损失值为:\((1-0.3333)^2 + (1-0.3333)^2\),样本3,4,5,6也属于R2,损失值为:\((0-0.3333)^2 + (0-0.3333)^2 + (0-0.3333)^2 + (0-0.3333)^2\),两组损失值和为2.222,大于特征一的第一个特征值的损失值,所以我们不取这个特征的特征值
继续,这里有四个特征,每个特征有六个特征值,所有需要6*4 = 24个损失值的计算,我们选取值最小的分量的分界点作为最佳划分点,这里我们就不一一计算了,直接给出最小的特征花萼长度,特征值为5.1 cm。这个时候损失函数最小为 0.8。 于是我们的预测函数此时也可以得到:
\(f(x) = \sum_{x\epsilon R_1}y_1*I(x\epsilon R_1) + \sum_{x\epsilon R_2}y_2*I(x\epsilon R_2)\)
此例子中\(R1=[2],R2=[1,3,4,5,6],y_1=1,y_2=0.2\),训练完以后的最终式子为:
\(f(x) = \sum_{x\epsilon R_1}1*I(x\epsilon R_1) + \sum_{x\epsilon R_2}0.2*I(x\epsilon R_2)\)
由这个式子,我们得到对样本属于类别1的预测值:\(f_1(x) = 1*1 + 0.2*5 = 2\),同理我们可以得到对样本属于类别2,3的预测值\(f_2(x),f_3(x)\),样本属于类别1的概率为:
\(P_1(x) = exp(f_1(x))/\sum_{k=1}^{3}exp(f_k(x))\)
四、参考
博客:https://www.cnblogs.com/ModifyRong/p/7744987.html
GBDT用于分类问题的更多相关文章
- 用于分类的决策树(Decision Tree)-ID3 C4.5
决策树(Decision Tree)是一种基本的分类与回归方法(ID3.C4.5和基于 Gini 的 CART 可用于分类,CART还可用于回归).决策树在分类过程中,表示的是基于特征对实例进行划分, ...
- GBDT多分类示例
相当于每次都是用2分类,然后不停的训练,最后把所有的弱分类器来进行汇总 样本编号 花萼长度(cm) 花萼宽度(cm) 花瓣长度(cm) 花瓣宽度 花的种类 1 5.1 3.5 1.4 0.2 山鸢尾 ...
- UFLDL深度学习笔记 (四)用于分类的深度网络
UFLDL深度学习笔记 (四)用于分类的深度网络 1. 主要思路 本文要讨论的"UFLDL 建立分类用深度网络"基本原理基于前2节的softmax回归和 无监督特征学习,区别在于使 ...
- 机器学习 | 详解GBDT在分类场景中的应用原理与公式推导
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第31篇文章,我们一起继续来聊聊GBDT模型. 在上一篇文章当中,我们学习了GBDT这个模型在回归问题当中的原理.GBD ...
- 机器学习&数据挖掘笔记_25(PGM练习九:HMM用于分类)
前言: 本次实验是用EM来学习HMM中的参数,并用学好了的HMM对一些kinect数据进行动作分类.实验内容请参考coursera课程:Probabilistic Graphical Models 中 ...
- Boosting(提升方法)之GBDT
一.GBDT的通俗理解 提升方法采用的是加法模型和前向分步算法来解决分类和回归问题,而以决策树作为基函数的提升方法称为提升树(boosting tree).GBDT(Gradient Boosting ...
- XGBoost,GBDT原理详解,与lightgbm比较
xgb原理: https://www.jianshu.com/p/7467e616f227 https://blog.csdn.net/a819825294/article/details/51206 ...
- GBDT学习笔记
GBDT(Gradient Boosting Decision Tree,Friedman,1999)算法自提出以来,在各个领域广泛使用.从名字里可以看到,该算法主要涉及了三类知识,Gradient梯 ...
- CART分类与回归树与GBDT(Gradient Boost Decision Tree)
一.CART分类与回归树 资料转载: http://dataunion.org/5771.html Classification And Regression Tree(CART)是决策 ...
随机推荐
- Python学习笔记 -- 第一章
本笔记参考廖雪峰的Python教程 简介 Python是一种计算机高级程序设计语言. 用Python可以做什么? 可以做日常任务,比如自动备份你的MP3:可以做网站,很多著名的网站包括YouTube就 ...
- QT QProgressBar QProgressDialog 模态,位置设置,无边框,进度条样式
一 关于模态设置 QProgressDialog可以设置模态(需要在new的时候传入parent),QProgressBar设置不好: 只有dialog可以设置模态,widget不能设置模态(QPr ...
- Machine Learning Based Proactive Flow Entry Deletion for OpenFlow
来源:IEEE 2018 作者:Hemin Yang and George F.Riley 摘要: 流表容量有限,因此高效管理流表至关重要.本文重点讨论了OpenFlow中定义的一种流表管理机制,即能 ...
- WIN10基于Hyper-V下运行kubernetes入门问题
http://www.cnblogs.com/shanyou/p/8503839.html 安装配置好之后启动,查看ip的方法: minikube status minikube ip 查看仪表盘da ...
- HTML 5 Canvas vs. SVG
pick up from http://www.w3school.com.cn/html5/html_5_canvas_vs_svg.asp Canvas 与 SVG 的比较 下表列出了 canvas ...
- zabbix 使用问题两个--中文乱码,以及监控ESXi下的虚拟机
1. 中文乱码 最开始中文显现 长方形不显示文字.解决办法: c:\windows\fonts 下面复制 楷体的字体(字体随意看自己喜欢) 文件名一般为: simkai.ttf 2.将simkai.t ...
- Android提供的layout文件存放位置
在编程的过程中,会用到android.R.layout下的一些常量.与这些常量对应的,Android提供了对应点的layout布局文件. android.jar中有对应的xml文件,但是打开的时候通常 ...
- VMware安装win7提示 operating system not found
在虚拟机上安装win7时,进度条读完,重启后提示operating system not found,可能原因是在使用分区工具格式化时没有把C盘设置为主分区并激活. 解决办法: 进入PE或者使用分区工 ...
- maven 引用另一个jar包 需要先打包在仓库里面 并在pom里面配置 才可以引用
maven 引用另一个jar包 需要先打包在仓库里面 并在pom里面配置 才可以引用
- python中lambda表达式中自由变量的坑,因为for循环结束了 变量还保存着,详见关于for循环的随笔
http://blog.csdn.net/u010949971/article/details/70045537