【论文阅读】自动驾驶光流任务 DeFlow: Decoder of Scene Flow Network in Autonomous Driving
再一次轮到讲自己的paper!耶,宣传一下自己的工作,顺便完成中文博客的解读 方便大家讨论。
Title Picture

Reference and pictures
paper: https://arxiv.org/abs/2401.16122
1. Introduction
这个启发主要是和上一篇 动态障碍物去除 的有一定的联系,去除完了当然会开始考虑是不是可以有实时识别之类的, 比起只是单纯标记1/0 的动和非动分割以外会是什么?然后就发现了 任务:scene flow,其实在2D可能更为人所熟知一些:光流检测,optical flow,也就是输入两帧连续的图片,输出其中一张的每个pixel的运动趋势,NxNx2,其中N为图片大小,2为x,y两个方向上的速度

对应的 3D情况下 则是切换为 输入是两帧连续的点云帧,输出一个点云帧内每个点的运动,Nx3,N为点云帧内点的个数,3为x, y, z三个轴上的速度

Motivation
首先关于在自动驾驶的光流任务,我们希望的是能满足以下两个点:
- Real Time Running 10Hz
- 能负担的起大量点云的输入 32或64线 至少都是6万个点/帧 起步了 随便选kitti 一帧 点数是:125883~=12万;而之前大部分光流论文还停留在max point=8192,然后我当时(2023年8月附近)随手选了最新cvpr的sota:SCOOP一文,一运行就cuda out of memory;问作者才知道 领域内默认max=8192 number of point
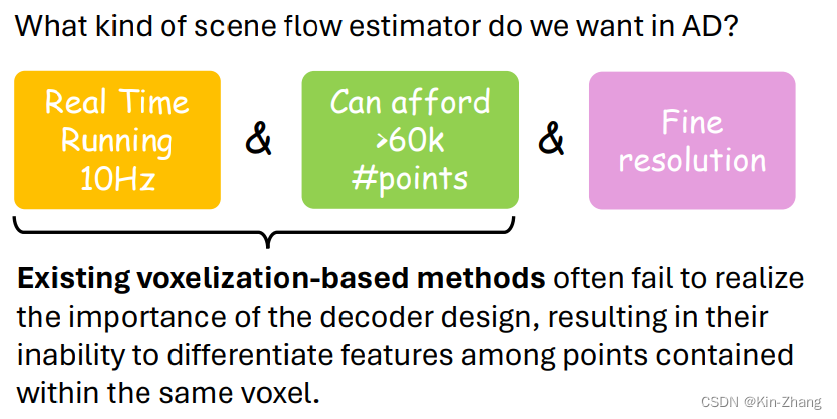
那么Voxelization-based method就是其中大头 or 唯一选择了;
接着故事就来到了 启发DeFlow的点:在查看最近工作(于2023年8月附近查看),阅读相关资料时发现,很多自监督的paper都声称自己超过了 某篇监督的模型效果,也就是Waymo在RA-L发的一篇dataset顺带提出了FastFlow3D(官方闭源,民间有复现);但是实际上 FastFlow3D本身就是参考3D detection那边网络框架进行设计的,仅将最后的decoder 连一个 MLPs 用以输出point flow
在我们的实验中发现,特别是在resolution用的20cm的时候,效果确实不好,主要原因集中在于下图2,统计发现如果一个点在动(速度≥0.5m/s),那么绝大多数都是在0.2以下的距离内运动;那么动一动脑筋,我们就想到了 调参,直接把resolution调到10cm不就行了?没错!DeFlow 实验表格 Table III 第三行证明确实直接double kill
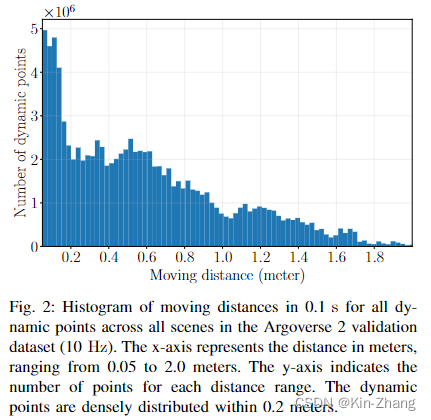
那么我们就知道了20cm 的栅格化分辨率下,点都在一个栅格里运动,所以前期pillar encoder 根本无法学出同一个voxel内不同点的feature,而FastFlow3D本身的decoder又是非常简单的MLP提取,无法实现voxel-to-point feature extraction
Contribution
所以我们的贡献就以以上为基础来讲述的啦,总结就是:1、提出了一个基于GRU voxel-to-point refinement的decoder;2、同时分析了以下loss function的影响并快速提了一个新的;3、最后实验到 AV2 官方在线榜单的SOTA
note:所有代码,各种对比消融实验 和 刷榜所用的model weight全部都开源供大家下载查阅,欢迎star和follow up:https://github.com/KTH-RPL/DeFlow

2. Method
非常简单易懂的方法部分,特别配合代码使用
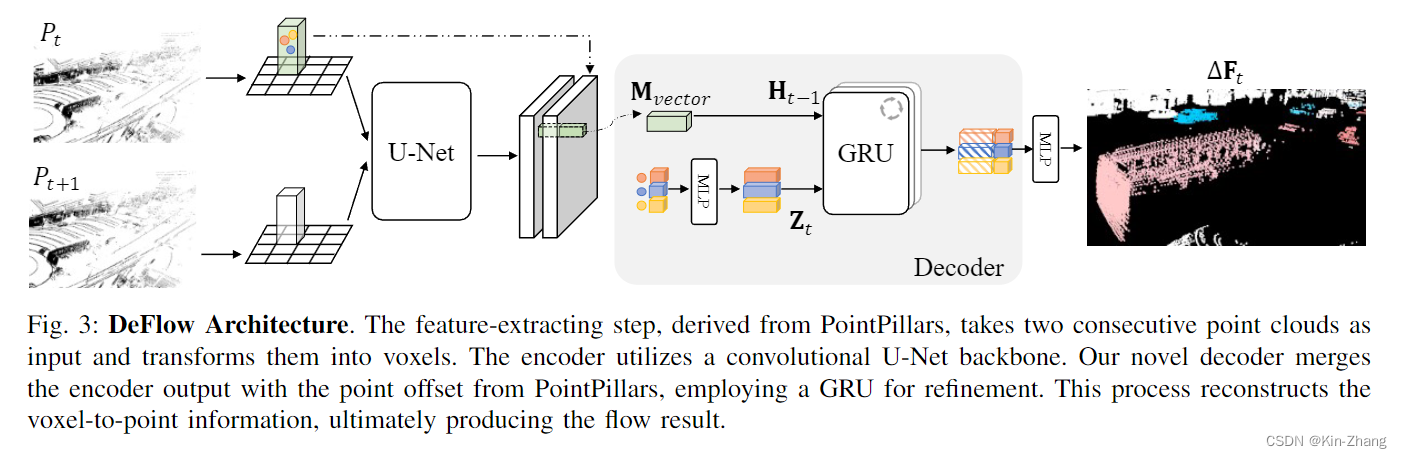
2.1 Input & Output
输入是两帧点云,具体一点 和FastFlow3D还有一系列的3D detection 一样;我们会先做地面去除,所以实际输入已经去掉了地面的 \(P_t, P_{t+1}\)
然后我们要估计的是 P_t 的 flow F,其中根据ego pose信息,我们也专注于预测除pose flow外的,也就是环境内的属于动态物体带速度的点
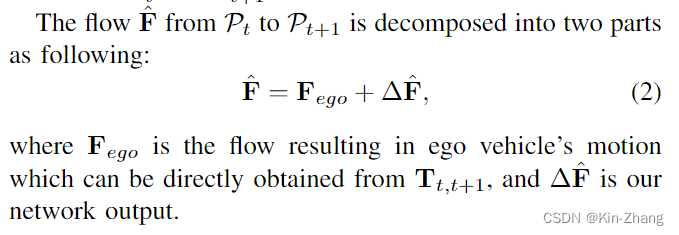
2.2 Decoder
看代码可能更快一点,论文和图主要是给了一个insight :
- 从pillar point feature提过来走MLP extend feature channel 作为 更新门 Z_t
- 然后由经过U-Net后的voxel feature 作为initial H_0,之后由再根据迭代次数每次得到更新的 H_
此处为对照代码,方便大家直接对照查看,具体在以下两个文件:
- decoder:https://github.com/KTH-RPL/DeFlow/blob/main/scripts/network/models/basic/decoder.py
- deflow mode: https://github.com/KTH-RPL/DeFlow/blob/main/scripts/network/models/deflow.py
def forward_single(self, before_pseudoimage: torch.Tensor,
after_pseudoimage: torch.Tensor,
point_offsets: torch.Tensor,
voxel_coords: torch.Tensor) -> torch.Tensor:
voxel_coords = voxel_coords.long()
after_voxel_vectors = after_pseudoimage[:, voxel_coords[:, 1],
voxel_coords[:, 2]].T
before_voxel_vectors = before_pseudoimage[:, voxel_coords[:, 1],
voxel_coords[:, 2]].T
# [N, 64] [N, 64] -> [N, 128]
concatenated_vectors = torch.cat([before_voxel_vectors, after_voxel_vectors], dim=1)
# [N, 3] -> [N, 64]
point_offsets_feature = self.offset_encoder(point_offsets)
# [N, 128] -> [N, 128, 1]
concatenated_vectors = concatenated_vectors.unsqueeze(2)
for itr in range(self.num_iters):
concatenated_vectors = self.gru(concatenated_vectors, point_offsets_feature.unsqueeze(2))
flow = self.decoder(torch.cat([concatenated_vectors.squeeze(2), point_offsets_feature], dim=1))
return flow
然后self.gru则是由这个常规ConvGRU module生成,forward和如下公式 直接对应
\]
# from https://github.com/weiyithu/PV-RAFT/blob/main/model/update.py
class ConvGRU(nn.Module):
def __init__(self, input_dim=64, hidden_dim=128):
super(ConvGRU, self).__init__()
self.convz = nn.Conv1d(input_dim+hidden_dim, hidden_dim, 1)
self.convr = nn.Conv1d(input_dim+hidden_dim, hidden_dim, 1)
self.convq = nn.Conv1d(input_dim+hidden_dim, hidden_dim, 1)
def forward(self, h, x):
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz(hx))
r = torch.sigmoid(self.convr(hx))
rh_x = torch.cat([r*h, x], dim=1)
q = torch.tanh(self.convq(rh_x))
h = (1 - z) * h + z * q
return h
所以和其他对GRU的用法不同,主要是我们将其用于voxel和point 之间细化特征提取了,当然代码里也有我第一次的MM TransformerDecoder 和 直接的 LinearDecoder尝试 hahah;前者太慢了,主要是点太多 我分了batch;后者效果不行,带代码就当附带都留下来了
然后论文里讲了以下loss function的设计,过程简化以下就是:之前的工作一般,在和gt的norm基础上 都自己给设计不同的权重,比如这里的 \(\sigma\)
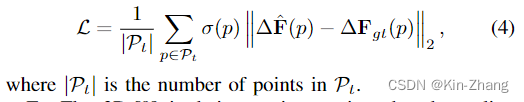
结论就是我们这样设计的,根据ZeroFlow的三种速度划分,我们不用权重而是直接unified average;实验部分会说明各个module的进步

OK 方法到这里就结束了,自认为非常直觉性的讲故事下来的 hahaha,然后很多实验在各种角度模块进行证明我们的statement
3. Experiments
这个是直接抽的leaderboard的表格,具体每个方法的文件 见 https://github.com/KTH-RPL/DeFlow/discussions/2

前三者都是自监督 每篇都说超过了监督方法 FastFlow3D,但实际上只是baseline weak了,或者说他们比不过 FastFlow3D 10cm (0.1m)的分辨率,ZeroFlow XL就是把分辨率降到了0.1 然后加大了网络;OK leaderboard (test set 只能上传到在线平台评估) 的分析就这样了,知道SOTA就行
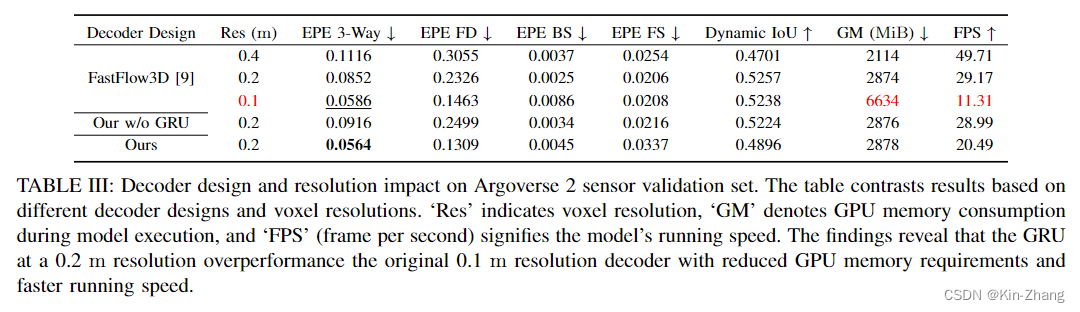
接下来的所有评估都是本地的,因为在线平台有提交次数限制 hahaha;首先贴出 Table III:注意这之中仅改变了decoder,其他loss func, learning rate, 训练条件均保持一致
这张表格也就是我们说的 我们的decoder提出 不需要细化10cm分辨率;因为这样GPU的Memory 大大上升了,总得留点给其他模块用嘛,见FastFlow3D 0.1 第三行
而我们保持了20cm的分辨率 速度和GPU内存使用均无太多上涨的情况下,我们的EPE 3-Way的分数甚至比FastFlow3D 细化10cm的还要好,误差比原来的 低了33%
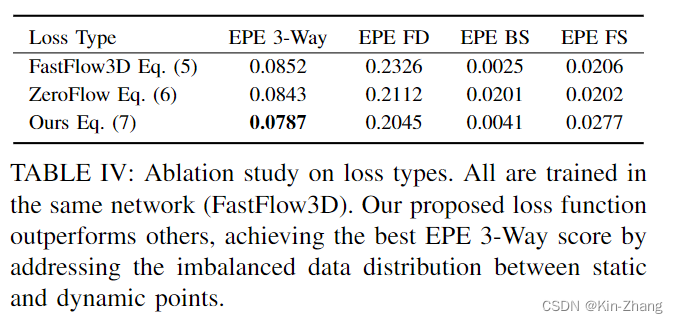
Ablation Study
Loss Function:注意此处我们全部使用FastFlow3D的network,仅loss function不同而已
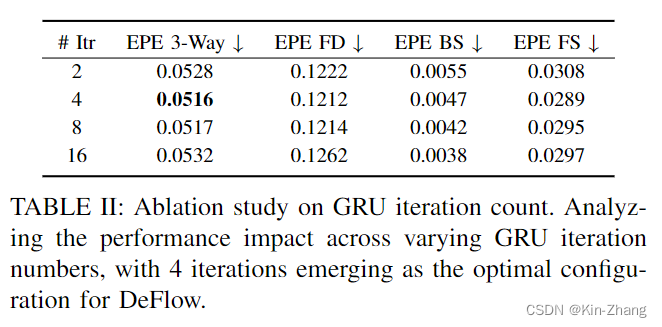
decoder iter number:其实我不太想做这个实验,但耐不住可能审稿人要问,所以我当时initial是选2/4跑的,毕竟多了降速 hahaha;此处全部使用deflow,仅iteration number不同,所以第二行可以认为是deflow: our decoder+our loss的效果(因为Table III为了对decoder的消融,所以其实我们使用的是fastflow3d提出的loss function;途中有韩国老哥没看论文,只要结果,所以他跑提供的weight的结果比我好,其实是他看错了表 lol)
结果可视化
主要就是快速看看就行,code那边还有10秒 demo视频可看
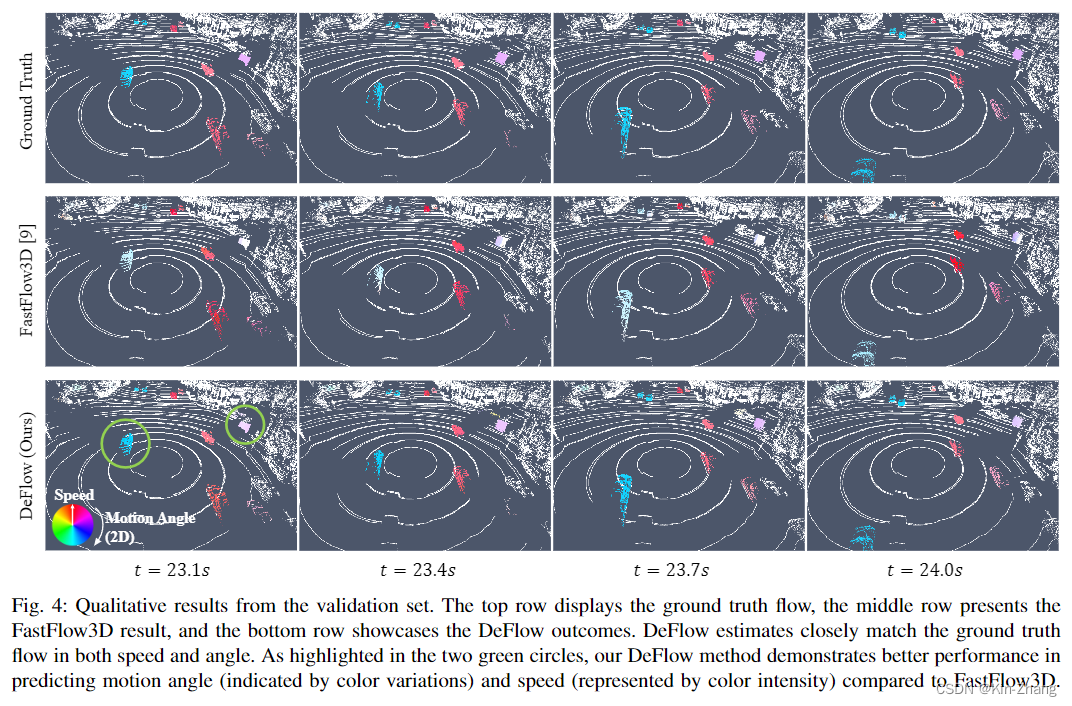
4. Conclusion
结论重复了一遍贡献

然后说了以下future work:自监督的模型训练,毕竟gt难标呀;欢迎查看最新ECCV2024的工作SeFlow,也就是我当时写下future work的时候已经在尝试路上的时候了;同开源(只要我主手的工作都开源 并在文章出版前 code上传完全能复现论文结果,我的信条 hahaha)
赠人点赞 手有余香 ;正向回馈 才能更好开放记录 hhh
【论文阅读】自动驾驶光流任务 DeFlow: Decoder of Scene Flow Network in Autonomous Driving的更多相关文章
- 论文阅读(XiangBai——【PAMI2018】ASTER_An Attentional Scene Text Recognizer with Flexible Rectification )
目录 XiangBai--[PAMI2018]ASTER_An Attentional Scene Text Recognizer with Flexible Rectification 作者和论文 ...
- 论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
Weilin Huang--[AAAI2016]Reading Scene Text in Deep Convolutional Sequences 目录 作者和相关链接 方法概括 创新点和贡献 方法 ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- 论文阅读(Lukas Neuman——【ICDAR2015】Efficient Scene Text Localization and Recognition with Local Character Refinement)
Lukas Neuman--[ICDAR2015]Efficient Scene Text Localization and Recognition with Local Character Refi ...
- 激光雷达Lidar与毫米波雷达Radar:自动驾驶的利弊
激光雷达Lidar与毫米波雷达Radar:自动驾驶的利弊 Lidar vs Radar: pros and cons for autonomous driving 新型无人驾驶汽车的数量在缓慢增加,各 ...
- 斯坦福发布2019全球AI报告:中国论文数量超美国,自动驾驶汽车领域获投资最多
近日,斯坦福联合MIT.哈佛.OpenAI等院校和机构发布了一份291页的<2019年度AI指数报告>. 这份长达291页的报告从AI的研究&发展.会议.技术性能.经济.教育.自动 ...
- ICCV 2019|70 篇论文抢先读,含目标检测/自动驾驶/GCN/等(提供PDF下载)
虽然ICCV2019已经公布了接收ID名单,但是具体的论文都还没放出来,为了让大家更快得看论文,我们汇总了目前已经公布的大部分ICCV2019 论文,并组织了ICCV2019论文汇总开源项目(http ...
- 论文阅读笔记四十三:DeeperLab: Single-Shot Image Parser(CVPR2019)
论文原址:https://arxiv.org/abs/1902.05093 github:https://github.com/lingtengqiu/Deeperlab-pytorch 摘要 本文提 ...
- 自动驾驶研究回顾:CVPR 2019摘要
我们相信开发自动驾驶技术是我们这个时代最大的工程挑战之一,行业和研究团体之间的合作将扮演重要角色.由于这个原因,我们一直在通过参加学术会议,以及最近推出的自动驾驶数据集和基于语义地图的3D对象检测的K ...
- 多目标跟踪:CVPR2019论文阅读
多目标跟踪:CVPR2019论文阅读 Robust Multi-Modality Multi-Object Tracking 论文链接:https://arxiv.org/abs/1909.0385 ...
随机推荐
- 在jeecg-boot中使用代码生成器&mybatis-plus
一.代码生成器代码生成器-->jeecgOneGUI配置文件:resource/jeecg/jeecg_config.properties,修改目标生成的路径和包名数据库连接:resource/ ...
- vue3中404路由匹配规则
{ path: '/:pathMatch(.)', component: () => import('@/views/error/404.vue') },
- width:100%与width:auto区别
小知识 width:100%与width:auto区别 width:100% : 子元素的 content 撑满父元素的content,如果子元素还有 padding.border等属性,或者是在父元 ...
- ctf_web
ctfshow web13 访问题目链接 一看是一道文件上传题,上传文件进行测试 上传php会显示 error suffix 因此推测会检测格式 当文件字数超出一定字数时,显示 error file ...
- 4G EPS 中的 Bearer
目录 文章目录 目录 前文列表 承载的内涵 EPS Bearer QoS QoS 的关键参数 APR GBR.MBR AMBR UE 是如何选择 EPS Bearer 的? E-RAB Radio B ...
- OpenNESS & OpenVINO Demo 部署
目录 文章目录 目录 部署架构 部署 Edge Controller 基础配置 配置 Proxy 配置防火墙 Install necessary package Install MySQL Insta ...
- git cherry-pick合并其它分支的某次提交(commits)到当前分支
git cherry-pick 可以选择某一个分支中的一个或几个commit(s)来进行操作. 例如,假设我们有个稳定版本的分支,叫v2.0.0,另外还有个开发版本的分支v3.0.0,我们不能直接把两 ...
- Machine Learning - 梯度下降
一.梯度下降:目的是为了寻找到最合适的 $w$ 和 $b$ ,让成本函数的值最小 \[w = w - α\frac{\partial J(w,b)}{\partial w} \] \[b = b - ...
- 多线程池Flask实战应用
多线程池Flask实战应用 import json import time import flask from concurrent.futures import ThreadPoolExecutor ...
- CSS——position定位属性
就像photoshop中的图层功能会把一整张图片分层一个个图层一样,网页布局中的每一个元素也可以看成是一个个类似图层的层模型.层布局模型就是把网页中的每一个元素看成是一层一层的,然后通过定位属性pos ...