AI歌姬,C位出道,基于PaddleHub/Diffsinger实现音频歌声合成操作(Python3.10)
懂乐理的音乐专业人士可以通过写乐谱并通过乐器演奏来展示他们的音乐创意和构思,但不识谱的素人如果也想跨界玩儿音乐,那么门槛儿就有点高了。但随着人工智能技术的快速迭代,现在任何一个人都可以成为“创作型歌手”,即自主创作并且让AI进行演唱,极大地降低了音乐制作的门槛。
本次我们基于PaddleHub和Diffsinger实现音频歌声合成操作,魔改歌曲《学猫叫》。
配置PaddleHub
首先确保本地就已经安装好了百度的PaddlePaddle深度学习框架,随后输入命令安装PaddleHub库:
pip install paddlehub@2.4.0
PaddleHub是基于PaddlePaddle生态下的预训练模型,旨在为开发者提供丰富的、高质量的、直接可用的预训练模型,也就是说语音模型我们不需要单独训练,直接使用paddlehub提供的模型进行推理即可,注意这里版本为最新的2.4.0。
安装成功之后,配置环境变量:
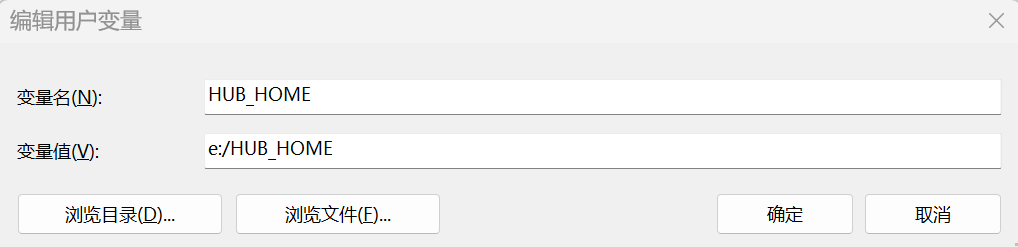
由于PaddleHub会把音色模型下载到本地,如果不配置环境变量,默认会下载到系统的C盘,所以这里单独设置为E盘。
随后需要将Win11的cmd编码设置为utf-8:
首先找到设置页面
搜索地区,并点击更改国家或地区
选择管理语言设置
选择更改系统区域设置
勾选Beta版: 使用Unicode UTF-8 提供全球语言支持,重启生效。
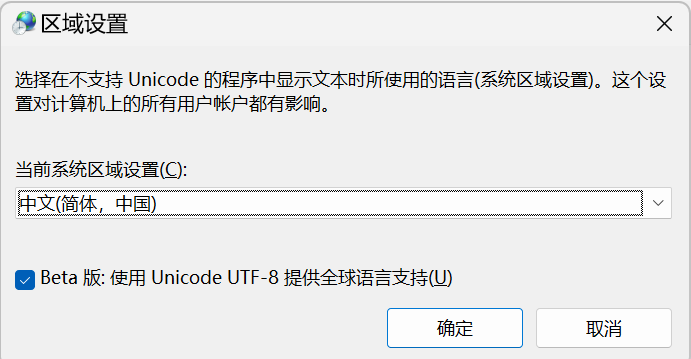
如果不设置utf-8编码,PaddleHub会因为乱码问题报错。
接着安装diffsinger:
hub install diffsinger
随后在终端运行代码:
import paddlehub as hub
module = hub.Module(name="diffsinger")
这里指定diffsinger的模型库,程序返回:
C:\Program Files\Python310\lib\site-packages\_distutils_hack\__init__.py:33: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
| Hparams chains: ['configs/config_base.yaml', 'configs/tts/base.yaml', 'configs/tts/fs2.yaml', 'configs/tts/base_zh.yaml', 'configs/singing/base.yaml', 'usr\\configs\\base.yaml', 'usr/configs/popcs_ds_beta6.yaml', 'usr/configs/midi/cascade/opencs/opencpop_statis.yaml', 'model\\config.yaml']
| Hparams:
K_step: 100, accumulate_grad_batches: 1, audio_num_mel_bins: 80, audio_sample_rate: 24000, base_config: ['usr/configs/popcs_ds_beta6.yaml', 'usr/configs/midi/cascade/opencs/opencpop_statis.yaml'],
binarization_args: {'shuffle': False, 'with_txt': True, 'with_wav': True, 'with_align': True, 'with_spk_embed': False, 'with_f0': True, 'with_f0cwt': True}, binarizer_cls: data_gen.singing.binarize.OpencpopBinarizer, binary_data_dir: data/binary/opencpop-midi-dp, check_val_every_n_epoch: 10, clip_grad_norm: 1,
content_cond_steps: [], cwt_add_f0_loss: False, cwt_hidden_size: 128, cwt_layers: 2, cwt_loss: l1,
cwt_std_scale: 0.8, datasets: ['popcs'], debug: False, dec_ffn_kernel_size: 9, dec_layers: 4,
decay_steps: 50000, decoder_type: fft, dict_dir: , diff_decoder_type: wavenet, diff_loss_type: l1,
dilation_cycle_length: 4, dropout: 0.1, ds_workers: 4, dur_enc_hidden_stride_kernel: ['0,2,3', '0,2,3', '0,1,3'], dur_loss: mse,
dur_predictor_kernel: 3, dur_predictor_layers: 5, enc_ffn_kernel_size: 9, enc_layers: 4, encoder_K: 8,
encoder_type: fft, endless_ds: True, ffn_act: gelu, ffn_padding: SAME, fft_size: 512,
fmax: 12000, fmin: 30, fs2_ckpt: , gaussian_start: True, gen_dir_name: ,
gen_tgt_spk_id: -1, hidden_size: 256, hop_size: 128, infer: False, keep_bins: 80,
lambda_commit: 0.25, lambda_energy: 0.0, lambda_f0: 0.0, lambda_ph_dur: 1.0, lambda_sent_dur: 1.0,
lambda_uv: 0.0, lambda_word_dur: 1.0, load_ckpt: , log_interval: 100, loud_norm: False,
lr: 0.001, max_beta: 0.06, max_epochs: 1000, max_eval_sentences: 1, max_eval_tokens: 60000,
max_frames: 8000, max_input_tokens: 1550, max_sentences: 48, max_tokens: 40000, max_updates: 160000,
mel_loss: ssim:0.5|l1:0.5, mel_vmax: 1.5, mel_vmin: -6.0, min_level_db: -120, norm_type: gn,
num_ckpt_keep: 3, num_heads: 2, num_sanity_val_steps: 1, num_spk: 1, num_test_samples: 0,
num_valid_plots: 10, optimizer_adam_beta1: 0.9, optimizer_adam_beta2: 0.98, out_wav_norm: False, pe_ckpt: checkpoints/0102_xiaoma_pe,
pe_enable: True, pitch_ar: False, pitch_enc_hidden_stride_kernel: ['0,2,5', '0,2,5', '0,2,5'], pitch_extractor: parselmouth, pitch_loss: l1,
pitch_norm: log, pitch_type: frame, pre_align_args: {'use_tone': False, 'forced_align': 'mfa', 'use_sox': True, 'txt_processor': 'zh_g2pM', 'allow_no_txt': False, 'denoise': False}, pre_align_cls: data_gen.singing.pre_align.SingingPreAlign, predictor_dropout: 0.5,
predictor_grad: 0.1, predictor_hidden: -1, predictor_kernel: 5, predictor_layers: 5, prenet_dropout: 0.5,
prenet_hidden_size: 256, pretrain_fs_ckpt: , processed_data_dir: data/processed/popcs, profile_infer: False, raw_data_dir: data/raw/popcs,
ref_norm_layer: bn, rel_pos: True, reset_phone_dict: True, residual_channels: 256, residual_layers: 20,
save_best: False, save_ckpt: True, save_codes: ['configs', 'modules', 'tasks', 'utils', 'usr'], save_f0: True, save_gt: False,
schedule_type: linear, seed: 1234, sort_by_len: True, spec_max: [-0.79453, -0.81116, -0.61631, -0.30679, -0.13863, -0.050652, -0.11563, -0.10679, -0.091068, -0.062174, -0.075302, -0.072217, -0.063815, -0.073299, 0.007361, -0.072508, -0.050234, -0.16534, -0.26928, -0.20782, -0.20823, -0.11702, -0.070128, -0.065868, -0.012675, 0.0015121, -0.089902, -0.21392, -0.23789, -0.28922, -0.30405, -0.23029, -0.22088, -0.21542, -0.29367, -0.30137, -0.38281, -0.4359, -0.28681, -0.46855, -0.57485, -0.47022, -0.54266, -0.44848, -0.6412, -0.687, -0.6486, -0.76436, -0.49971, -0.71068, -0.69724, -0.61487, -0.55843, -0.69773, -0.57502, -0.70919, -0.82431, -0.84213, -0.90431, -0.8284, -0.77945, -0.82758, -0.87699, -1.0532, -1.0766, -1.1198, -1.0185, -0.98983, -1.0001, -1.0756, -1.0024, -1.0304, -1.0579, -1.0188, -1.05, -1.0842, -1.0923, -1.1223, -1.2381, -1.6467], spec_min: [-6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0, -6.0],
spk_cond_steps: [], stop_token_weight: 5.0, task_cls: usr.diffsinger_task.DiffSingerMIDITask, test_ids: [], test_input_dir: ,
test_num: 0, test_prefixes: ['popcs-说散就散', 'popcs-隐形的翅膀'], test_set_name: test, timesteps: 100, train_set_name: train,
use_denoise: False, use_energy_embed: False, use_gt_dur: False, use_gt_f0: False, use_midi: True,
use_nsf: True, use_pitch_embed: False, use_pos_embed: True, use_spk_embed: False, use_spk_id: False,
use_split_spk_id: False, use_uv: True, use_var_enc: False, val_check_interval: 2000, valid_num: 0,
valid_set_name: valid, validate: False, vocoder: vocoders.hifigan.HifiGAN, vocoder_ckpt: checkpoints/0109_hifigan_bigpopcs_hop128, warmup_updates: 2000,
wav2spec_eps: 1e-6, weight_decay: 0, win_size: 512, work_dir: ,
Using these as onnxruntime providers: ['CPUExecutionProvider']
说明PaddleHub已经配置好了,执行过程中预训练模型会被下载到E盘。
Diffsinger模型推理
DiffSinger是一个基于扩散概率模型的 SVS 声学模型,一个参数化的马尔科夫链,它可以根据乐谱的条件,迭代地将噪声转换为旋律谱。
推理之前,安装推理加速模块:
pip install onnxruntime
通过隐式优化变异约束,DiffSinger 可以被稳定地训练并产生真实的输出。
这里通过内置的singing_voice_synthesis方法:
singing_voice_synthesis(inputs: Dict[str, str],sample_num: int = 1,
save_audio: bool = True,save_dir: str = 'outputs')
参数含义是:
1. inputs (Dict[str, str]): 输入歌词数据。
2. sample_num (int): 生成音频的数量。
3. save_audio (bool): 是否保存音频文件。
4.save_dir (str): 保存处理结果的文件目录。
在官方文档中:
https://github.com/MoonInTheRiver/DiffSinger/blob/master/docs/README-SVS-opencpop-cascade.md
作者给出了一段示例代码:
results = module.singing_voice_synthesis(
inputs={
'text': '小酒窝长睫毛AP是你最美的记号',
'notes': 'C#4/Db4 | F#4/Gb4 | G#4/Ab4 | A#4/Bb4 F#4/Gb4 | F#4/Gb4 C#4/Db4 | C#4/Db4 | rest | C#4/Db4 | A#4/Bb4 | G#4/Ab4 | A#4/Bb4 | G#4/Ab4 | F4 | C#4/Db4',
'notes_duration': '0.407140 | 0.376190 | 0.242180 | 0.509550 0.183420 | 0.315400 0.235020 | 0.361660 | 0.223070 | 0.377270 | 0.340550 | 0.299620 | 0.344510 | 0.283770 | 0.323390 | 0.360340',
'input_type': 'word'
},
sample_num=1,
save_audio=True,
save_dir='outputs'
)
# text:歌词文本
# notes:音名
# notes_duration:音符时值(时长)
# input_type:输入类型(文本)
示例中使用的是林俊杰的歌曲《小酒窝》。
这里,最核心的逻辑是inputs的notes参数,也就是乐谱中的音名,而notes_duration参数则是该音名的持续时长。
音名对照参照:
1 A0 6L4 A2 大字2组 27.5
2 A#0 #6L4 A#2 29.1353
3 B0 7L4 B2 30.8677
4 1 C1 1L3 C1 大字1组 32.7032
5 2 C#1 #1L3 C#1 34.6479
6 3 D1 2L3 D1 36.7081
7 4 D#1 #2L3 D#1 38.8909
8 5 E1 3L3 E1 41.2035
9 6 F1 4L3 F1 43.6536
10 7 F#1 #4L3 F#1 46.2493
11 8 G1 5L3 G1 48.9995
12 9 G#1 #5L3 G#1 51.913
13 10 A1 6L3 A1 55
14 11 A#1 #6L3 A#1 58.2705
15 12 B1 7L3 B1 61.7354
16 13 C2 1L2 C 大字组 65.4064
17 14 C#2 #1L2 #C 69.2957
18 15 D2 2L2 D 73.4162
19 16 D#2 #2L2 #D 77.7817
20 17 E2 3L2 E 82.4069
21 18 F2 4L2 F 87.3071
22 19 F#2 #4L2 #F 92.4986
23 20 G2 5L2 G 97.9989
24 21 G#2 #5L2 #G 103.826
25 22 A2 6L2 A 110
26 23 A#2 #6L2 #A 116.541
27 24 B2 7L2 B 123.471
28 25 C3 1L1 c 小字组 130.813
29 26 C#3 #1L1 #c 138.591
30 27 D3 2L1 d 146.832
31 28 D#3 #2L1 #d 155.563
32 29 E3 3L1 e 164.814
33 30 F3 4L1 f 174.614
34 31 F#3 #4L1 #f 184.997
35 32 G3 5L1 g 195.998
36 33 G#3 #5L1 #g 207.652
37 34 A3 6L1 a 220
38 35 A#3 #6L1 #a 233.082
39 36 B3 7L1 b 246.942
40 37 C4 1 c1 小字1组(中央C) 261.626
41 38 C#4 #1 c#1 277.183
42 39 D4 2 d1 293.665
43 40 D#4 #2 d#1 311.127
44 41 E4 3 e1 329.628
45 42 F4 4 f1 349.228
46 43 F#4 #4 f#1 369.994
47 44 G4 5 g1 391.995
48 45 G#4 #5 g#1 415.305
49 46 A4 6 a1 (国际标准A音) 440
50 47 A#4 #6 a#1 466.164
51 48 B4 7 b1 493.883
52 49 C5 1H1 c2 小字2组 523.251
53 50 C#5 #1H1 c#2 554.365
54 51 D5 2H1 d2 587.33
55 52 D#5 #2H1 d#2 622.254
56 53 E5 3H1 e2 659.255
57 54 F5 4H1 f2 698.456
58 55 F#5 #4H1 f#2 739.989
59 56 G5 5H1 g2 783.991
60 57 G#5 #5H1 g#2 830.609
61 58 A5 6H1 a2 880
62 59 A#5 #6H1 a#2 932.328
63 60 B5 7H1 b2 987.767
64 61 C6 1H2 c3 小字3组 1046.5
65 62 C#6 #1H2 c#3 1108.73
66 63 D6 2H2 d3 1174.66
67 64 D#6 #2H2 d#3 1244.51
68 65 E6 3H2 e3 1318.51
69 66 F6 4H2 f3 1396.91
70 67 F#6 #4H2 f#3 1479.98
71 68 G6 5H2 g3 1567.98
72 69 G#6 #5H2 g#3 1661.22
73 70 A6 6H2 a3 1760
74 71 A#6 #6H2 a#3 1864.66
75 72 B6 7H2 b3 1975.53
76 73 C7 1H3 c4 小字4组 2093
77 74 C#7 #1H3 c#4 2217.46
78 75 D7 2H3 d4 2349.32
79 76 D#7 #2H3 d#4 2489.02
80 77 E7 3H3 e4 2637.02
81 78 F7 4H3 f4 2793.83
82 79 F#7 #4H3 f#4 2959.96
83 80 G7 5H3 g4 3135.96
84 81 G#7 #5H3 g#4 3322.44
85 82 A7 6H3 a4 3520
86 83 A#7 #6H3 a#4 3729.31
87 84 B7 7H3 b4 3951.07
88 C8 1H4 c5 小字5组 4186.01
说白了,就是按照简谱的键位转换为音名。
以旋律相对简单的《学猫叫》为例子:
C’ D’ E’ G C’ E’ E’ D’ C’D’ G’ G’G’ G’ C’ B C’ C’ C’ C’ C’ B C’ B C’ B A G
我们一起学猫叫 一起喵喵喵喵喵 在你面前撒个娇 哎呦喵喵喵喵喵
F C Dm G
G G A A A A A G E G E G D’ C’ G E’ E’ E’ F’ G’ C’ C’ E’ D’
我的心脏砰砰跳 迷恋上你的坏笑 你不说爱我 我就喵喵喵
它的前七个音符分别对应CDEGCEE,对应代码:
results = module.singing_voice_synthesis(
inputs={
'text': '我们一起学猫叫',
'notes': 'D#3 | E3 | E5 | G4 | C5 | E5 | E5',
'notes_duration': '0.407140 | 0.307140 | 0.307140 | 0.307140 | 0.307140 | 0.307140 | 0.307140 ' ,
'input_type': 'word'
},
sample_num=1,
save_audio=True,
save_dir='./outputs'
)
这里推理的音频存储在outputs文件夹内。
结语
利用DiffSinger我们可以简单的将歌词和旋律通过代码转换为实体歌声,但需要注意的是该项目只是输出了清唱部分,真正的音乐作品还需要添加伴奏以及调音等操作,欲知后事如何,且听下回分解,另外,魔改版本的《学猫叫》已经上传到Youtube(B站):刘悦的技术博客,欢迎品鉴。
AI歌姬,C位出道,基于PaddleHub/Diffsinger实现音频歌声合成操作(Python3.10)的更多相关文章
- 笔精墨妙,妙手丹青,微软开源可视化版本的ChatGPT:Visual ChatGPT,人工智能AI聊天发图片,Python3.10实现
说时迟那时快,微软第一时间发布开源库Visual ChatGPT,把 ChatGPT 的人工智能AI能力和Stable Diffusion以及ControlNet进行了整合.常常被互联网人挂在嘴边的& ...
- 什么?云数据库也能C位出道?
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 是的,你没有看错.腾讯智造,新一代云数据库CynosDB,"C"位出道了! CynosDB是腾讯云自研的新一代高性能高可 ...
- 音视频技术“塔尖”之争,网易云信如何C位出道?
音视频技术“塔尖”之争,网易云信如何C位出道? 社交+美颜.抖音短视频.在线狼人杀.直播竞答.子弹短信……,过往两三年间,互联网新产品和新玩法层出不穷,风口不断切换.这些爆红的网络应用背后,都有一些共 ...
- 闻其声而知雅意,基于Pytorch(mps/cpu/cuda)的人工智能AI本地语音识别库Whisper(Python3.10)
前文回溯,之前一篇:含辞未吐,声若幽兰,史上最强免费人工智能AI语音合成TTS服务微软Azure(Python3.10接入),利用AI技术将文本合成语音,现在反过来,利用开源库Whisper再将语音转 ...
- 云原生的弹性 AI 训练系列之一:基于 AllReduce 的弹性分布式训练实践
引言 随着模型规模和数据量的不断增大,分布式训练已经成为了工业界主流的 AI 模型训练方式.基于 Kubernetes 的 Kubeflow 项目,能够很好地承载分布式训练的工作负载,业已成为了云原生 ...
- 登峰造极,师出造化,Pytorch人工智能AI图像增强框架ControlNet绘画实践,基于Python3.10
人工智能太疯狂,传统劳动力和内容创作平台被AI枪毙,弃尸尘埃.并非空穴来风,也不是危言耸听,人工智能AI图像增强框架ControlNet正在疯狂地改写绘画艺术的发展进程,你问我绘画行业未来的样子?我只 ...
- 好饭不怕晚,Google基于人工智能AI大语言对话模型Bard测试和API调用(Python3.10)
谷歌(Google)作为开源过著名深度学习框架Tensorflow的超级大厂,是人工智能领域一股不可忽视的中坚力量,旗下新产品Bard已经公布测试了一段时间,毁誉参半,很多人把Google的Bard和 ...
- 人工智能AI图像风格迁移(StyleTransfer),基于双层ControlNet(Python3.10)
图像风格迁移(Style Transfer)是一种计算机视觉技术,旨在将一幅图像的风格应用到另一幅图像上,从而生成一幅新图像,该新图像结合了两幅原始图像的特点,目的是达到一种风格化叠加的效果,本次我们 ...
- iOS冰与火之歌(番外篇) - 基于PEGASUS(Trident三叉戟)的OS X 10.11.6本地提权
iOS冰与火之歌(番外篇) 基于PEGASUS(Trident三叉戟)的OS X 10.11.6本地提权 蒸米@阿里移动安全 0x00 序 这段时间最火的漏洞当属阿联酋的人权活动人士被apt攻击所使用 ...
- 在Jena框架下基于MySQL数据库实现本体的存取操作
在Jena框架下基于MySQL数据库实现本体的存取操作 转自:http://blog.csdn.net/jtz_mpp/article/details/6224311 最近在做一个基于本体的管理系统. ...
随机推荐
- 安装centos系统,硬盘检测报错:修改BIOS为 Legacy
进bios,将模式修改为legacy. 硬盘使用 MBR 分区,需要用 Legacy BIOS 启动,而不是 UEFI BIOS . 至于为什么安装的时候会报错? 可能是系统有这方面限制.也可能是别的 ...
- 2021-7-12 VUE的增删改查功能简单运用
Vue增删改查简易实例 <!DOCTYPE html> <html> <head> <title> </title> <style t ...
- ESP32连接云服务器【WebSocket】
ESP32连接云服务器[ESP32+宝塔面板] 相关文章 ESP32连接MQ Sensor实现气味反应 https://blog.csdn.net/ws15168689087/article/deta ...
- Django: AssertionError: `HyperlinkedIdentityField` requires the request in the serializer context. Add `context={'request': request}` when instantiating the serializer.
错误翻译 AssertionError: ' HyperlinkedIdentityField '需要在序列化器上下文中请求.在实例化序列化器时添加' context={'request': requ ...
- 【Unity3D】反射和折射
1 前言 立方体纹理(Cubemap)和天空盒子(Skybox)中介绍了生成立方体纹理和制作天空盒子的方法,本文将使用立方体纹理进行采样,实现反射.菲涅耳反射和折射效果.另外,本文还使用了 Gra ...
- 【技术积累】Linux中的命令行【理论篇】【六】
as命令 命令介绍 在Linux中,as命令是一个汇编器,用于将汇编语言源代码转换为可执行的目标文件.它是GNU Binutils软件包的一部分,提供了一系列用于处理二进制文件的工具. 命令说明 as ...
- Ubuntu安装后续工作
更新源: sudo gedit /etc/apt/sources.list 清华的源 deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial ma ...
- 独奏者2 序章的wp
0x01 0ctf_2017_babyheap 2023.7.24 国防科技大学 合肥 本题除了fastbin attack,最重要的是伪造fakechunk,使得存放chunk的指针有两个指向同一个 ...
- js调起android安卓与ios苹果方法 vue3.0 + ts
let shareSelect = (ev :any) => { const u :any= navigator.userAgent; const win :any = window const ...
- 微信小程序 setData accepts an Object rather than some undefined 解决办法
问题 setData accepts an Object rather than some undefined setData接受一个对象而不是一些定义 让我猜猜, 你一定是在加载index页面(首页 ...