Linux — 物理内存管理
物理内存的组织方式
- 物理内存是由连续的一页一页的块组成,每个物理页都有页号
- 每个页由
struct page表示,放进数组里——平坦内存模型
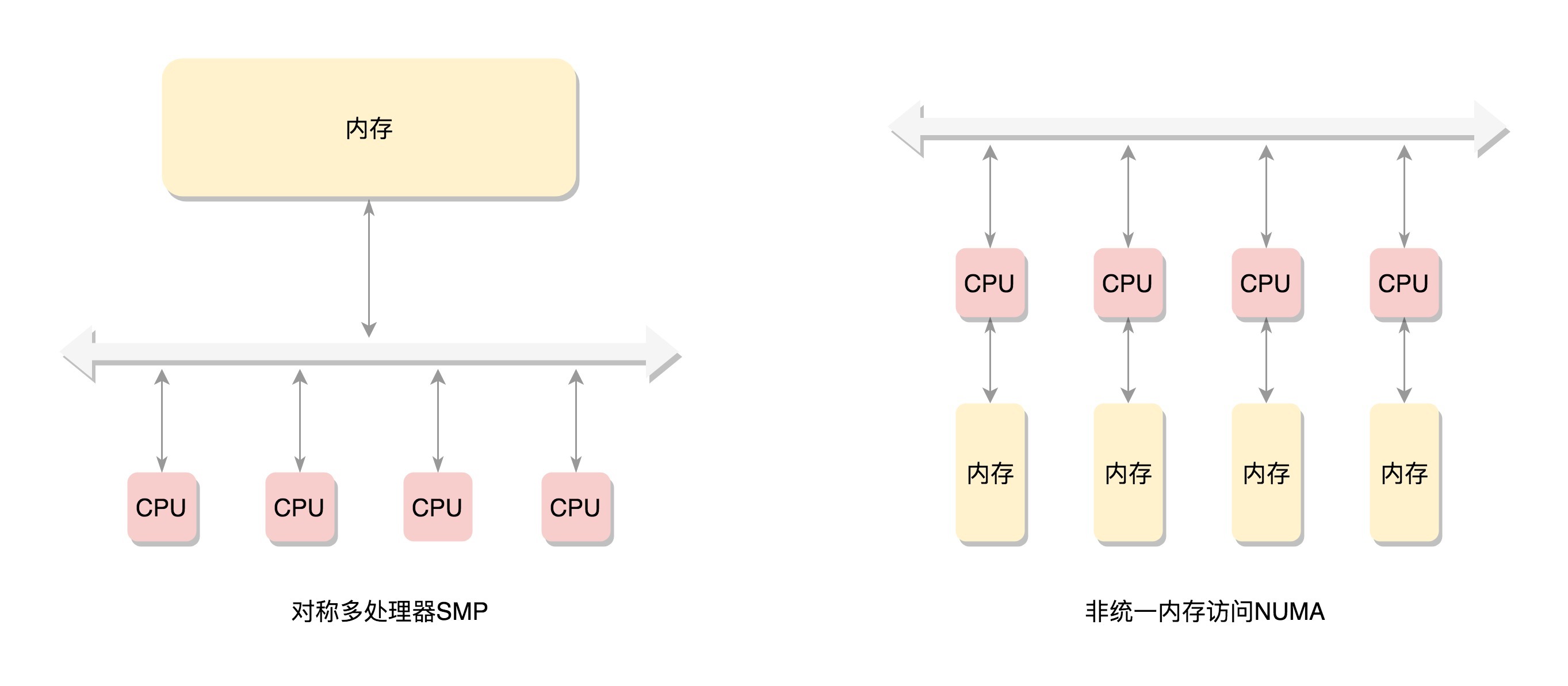
SMP和NUMA
- SMP中,总线会称为瓶颈,因为数据都要经过它
- NUMA中
- 每个CPU都有本地内存,CPU访存不用过总线
- 但本地内存不足时,每个CPU可以去另外的NUMA节点申请内存,延时较长
- NUMA基本是非连续内存模型,非连续内存模型不一定就是NUMA
typedef struct pglist_data
{
struct zone node_zones[MAX_NR_ZONES]; // 每个节点还会分成一个个区域zone
struct zonelist node_zonelists[MAX_ZONELISTS]; // 备用节点
int nr_zones;
struct page *node_mem_map; // 此节点的struct page数组
unsigned long node_start_pfn; // 起始页号
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page range, including holes */
int node_id; // 自己的id
......
} pg_data_t;
举个例子:
64M 物理内存隔着一个 4M 的空洞,然后是另外的 64M 物理内存。 换算成页面数目就是,16K 个页面隔着 1K 个页面,然后是另外 16K 个页面。这种情况下,
node_spanned_pages就是 33K 个页面,node_present_pages就是 32K 个页面。
ZONE_DMA
ZONE_DMA可用于做直接内存存取的内存。
DMA机制:
要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。
64位系统有两个DMA系统,除了ZONE_DMA还有ZONE_DMA32
区域
上面把内存分成了节点,把节点分成了区域。区域zone的定义:
struct zone {
......
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset; // 用于区分冷热页
unsigned long zone_start_pfn; // 表示属于这个zone的第一页
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
*/
unsigned long managed_pages; // 此zone被伙伴系统管理的所有page数目
unsigned long spanned_pages; // 包括中间的物理内存空洞
unsigned long present_pages; // 物理内存中真实存在的page数
const char *name;
......
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
......
} ____cacheline_internodealigned_in_
什么是冷热页?
x86 体系结构中,为了让 CPU 快速访问段描述符,在 CPU 里面有段描述符缓存。CPU 访问这个缓存的速度比内存快得多。同样对于页来讲,也是这样的。如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而 per_cpu_pageset 也是每个 CPU 一个。
页(Page)
一个物理页面可以使用多种模式:
- 要用就用一整页
- 匿名页:一整页的内存,或者直接和虚拟地址空间建立映射关系
- 内存映射文件:或者用于关联一个文件,然后再和虚拟地址空间建立映射关系
- 每个进程都有自己的页表
- 仅需分配小块内存
- Linux采用了slab allocator 的技术,用于分配称为slab的小块内存
- 基本原理:
- 从内存管理模块申请一整块页
- 划分成多个小块的存储池,用复杂的队列维护小块的状态
- 状态包括:被分配了/被放回池子/应该被回收
Linux中把所有空闲页分为了11个页块链表,每个块链表分别包含很多个大小的页块,有1、2、4、8、16、32、64、128、512和1024个连续的页块。
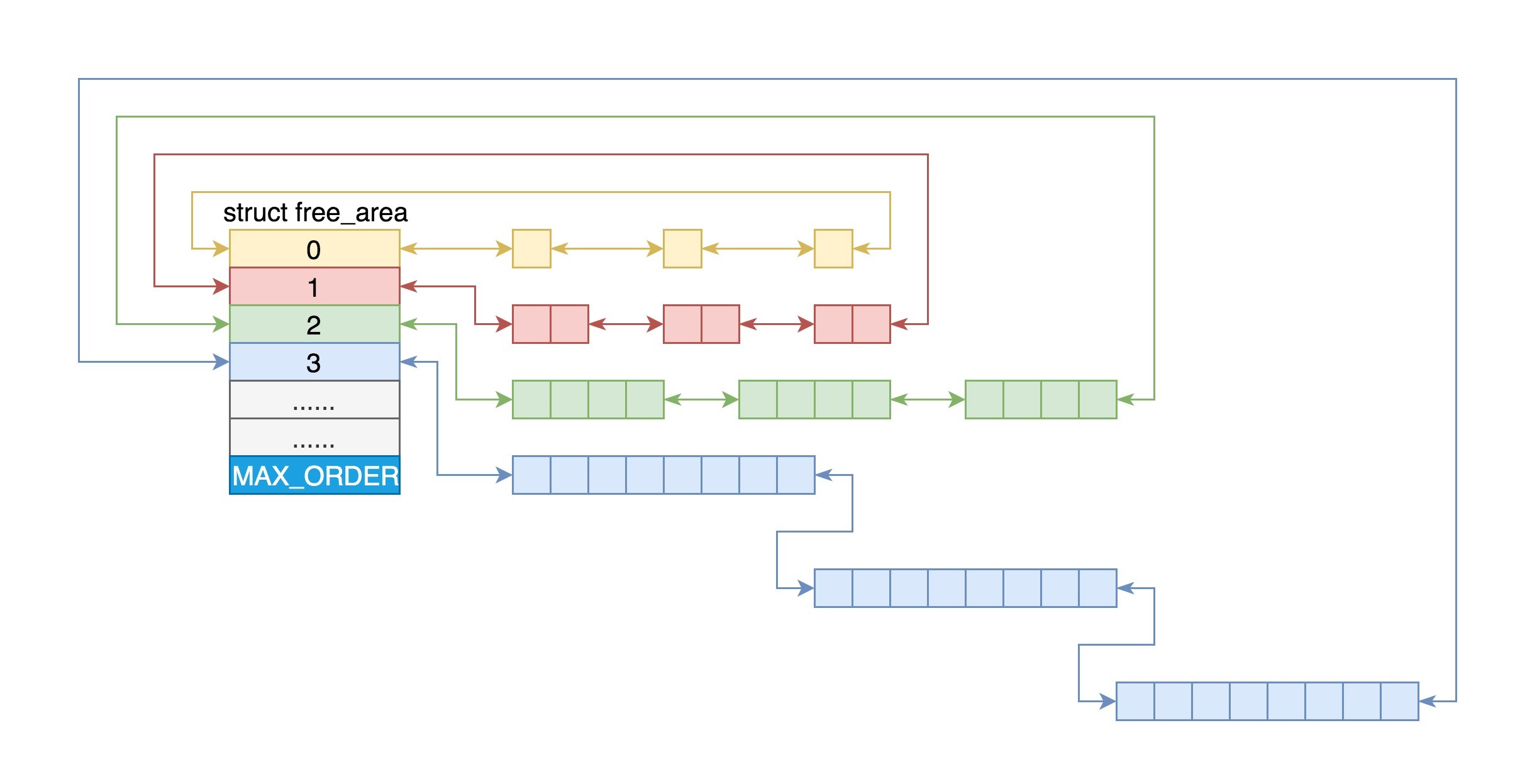
请求分配页块时,依次按照更大的页块链表去找。分配的页块有多余的页时,伙伴系统会根据多余的页块大小,插入到对应的空闲页块链表中。
举个栗子:
要请求一个 128 个页的页块时,先检查 128 个页的页块链表是否有空闲块。如果没有,则查 256 个页的页块链表;如果有空闲块的话,则将 256 个页的页块分成两份,一份使用,一份插入 128 个页的页块链表中。如果还是没有,就查 512 个页的页块链表;如果有的话,就分裂为 128、128、256 三个页块,一个 128 的使用,剩余两个插入对应页块链表。
小结
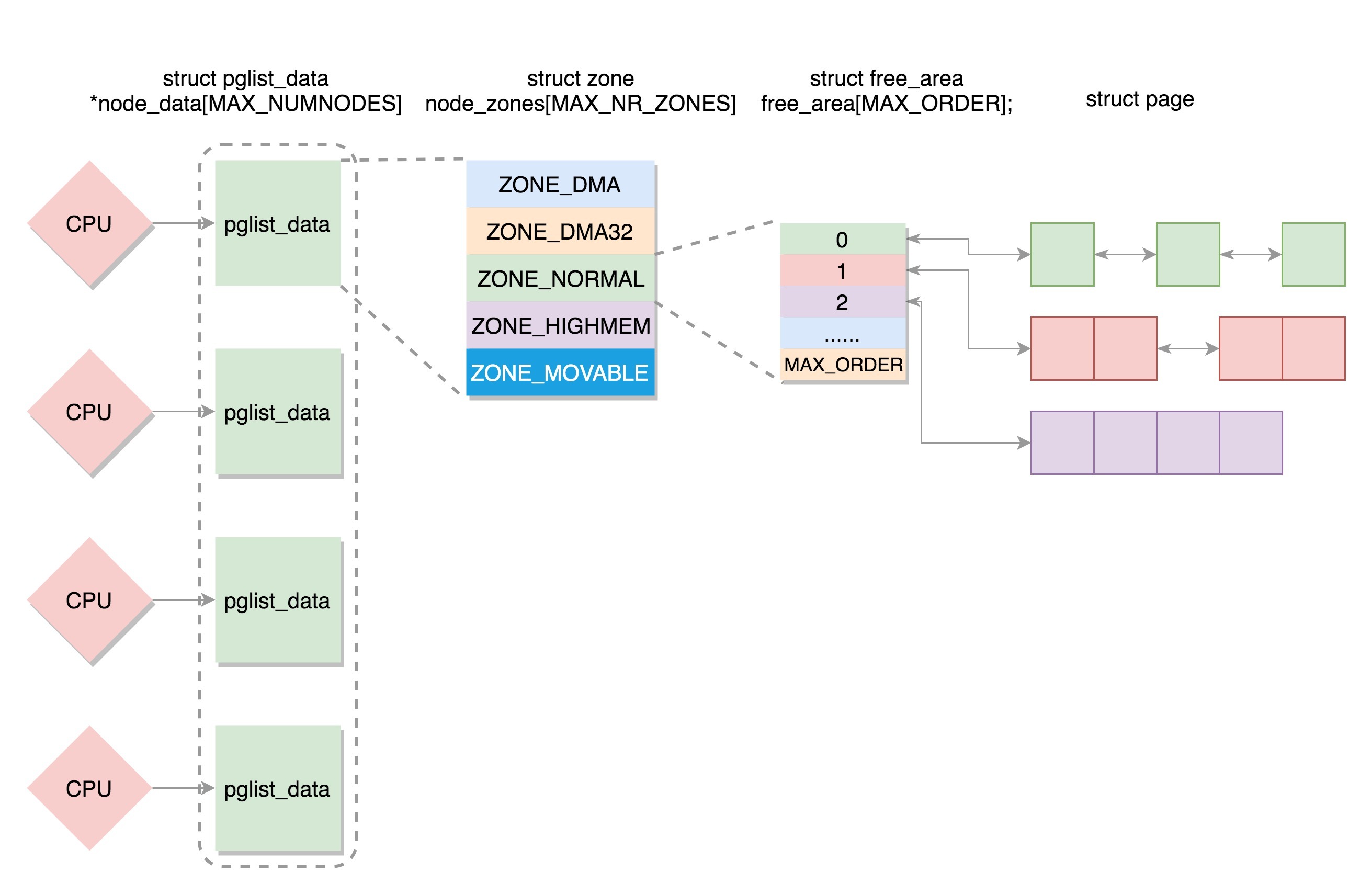
- 如果有多个 CPU,那就有多个节点。每个节点用 struct pglist_data 表示,放在一个数组里面。
- 每个节点分为多个区域,每个区域用 struct zone 表示,也放在一个数组里面。
- 每个区域分为多个页。为了方便分配,空闲页放在 struct free_area 里面,使用伙伴系统进行管理和分配,每一页用 struct page 表示。
Linux — 物理内存管理的更多相关文章
- 一步一图带你深入理解 Linux 物理内存管理
1. 前文回顾 在上篇文章 <深入理解 Linux 虚拟内存管理> 中,笔者分别从进程用户态和内核态的角度详细深入地为大家介绍了 Linux 内核如何对进程虚拟内存空间进行布局以及管理的相 ...
- linux物理内存管理
1.为什么需要连续的物理内存: Linux内核管理物理内存是通过分页机制实现的,它将整个内存划分成无数个4k(在i386体系结构中)大小的页,从而分配和回收内存的基本单位便是内存页了.利用分页管理有助 ...
- 深入理解 Linux 物理内存分配全链路实现
前文回顾 在上篇文章 <深入理解 Linux 物理内存管理>中,笔者详细的为大家介绍了 Linux 内核如何对物理内存进行管理以及相关的一些内核数据结构. 在介绍物理内存管理之前,笔者先从 ...
- Linux内存管理 (1)物理内存初始化
专题:Linux内存管理专题 关键词:用户内核空间划分.Node/Zone/Page.memblock.PGD/PUD/PMD/PTE.lowmem/highmem.ZONE_DMA/ZONE_NOR ...
- LInux中的物理内存管理
2017-02-23 一.伙伴系统 LInux下用伙伴系统管理物理内存页,伙伴系统得益于其良好的算法,一定程度上可以避免外部碎片为何这么说?先回顾下Linux下虚拟地址空间的分布. 在X86架构下,系 ...
- Linux内存:物理内存管理概述
内存中的物理内存管理 概述 一般来说,linux内核一般将处理器的虚拟地址空间划分为2部分.底部比较大的部分用于用户进程,顶部则专用于内核. 在IA-32系统上,地址空间在用户进程和内核之间划分的典型 ...
- 浅谈Linux内存管理机制
经常遇到一些刚接触Linux的新手会问内存占用怎么那么多?在Linux中经常发现空闲内存很少,似乎所有的内存都被系统占用了,表面感觉是内存不够用了,其实不然.这是Linux内存管理的一个优秀特性,在这 ...
- linux内存管理
一.Linux 进程在内存中的数据结构 一个可执行程序在存储(没有调入内存)时分为代码段,数据段,未初始化数据段三部分: 1) 代码段:存放CPU执行的机器指令.通常代码区是共享的,即其它执行程 ...
- Linux内存管理原理
本文以32位机器为准,串讲一些内存管理的知识点. 1. 虚拟地址.物理地址.逻辑地址.线性地址 虚拟地址又叫线性地址.linux没有采用分段机制,所以逻辑地址和虚拟地址(线性地址)(在用户态,内核态逻 ...
- 了解linux内存管理机制(转)
今天了解了下linux内存管理机制,在这里记录下,原文在这里http://ixdba.blog.51cto.com/2895551/541355 根据自己的理解画了张图: 下面是转载的内容: 一 物理 ...
随机推荐
- archlinux virtualbox使用文件共享 主机arch,客机windows8.1 windows10
参照 https://www.cnblogs.com/cuitang/p/11263008.html 1.安装virtualbox增强功能VBoxGuestAdditions.iso (1)从virt ...
- 【Java面试题】Hibernate
六.Hibernate 50)简述一下 hibernate 的开发流程 第一步:加载 hibernate 的配置文件,读取配置文件的参数(jdbc 连接参数,数据 库方言,hbm 表与对象关系映射文件 ...
- MySQL查询表结构信息SQL语句
一.获取某数据库下的所有数据表名 SELECT TABLE_NAME, TABLE_COMMENT FROM information_schema.TABLES WHERE TABLE_SCHEMA ...
- ET介绍——强大的基于.dotnet7+Unity3d的双端C#开源游戏框架
ET是一个开源的游戏客户端(基于unity3d)服务端双端框架,服务端是使用C# .net core开发的分布式游戏服务端,其特点是开发效率高,性能强,双端共享逻辑代码,客户端服务端热更机制完善,同时 ...
- #博弈论#Poj 2484 A Funny Game
题目 \(n\)个石子排成一圈,每次可以取一个或相邻的一对, 取完为胜,问先手是否必胜 分析 无论先手如何取,后手都能模仿先手的取法. 比如说,当石子个数为奇数时先手取相邻的一对,后手可以将对面的那一 ...
- java中的内部类内部接口详解
目录 简介 内部类 静态内部类 非静态内部类 静态方法内部类 非静态方法的内部类 匿名类 内部接口 总结 简介 一般来说,我们创建类和接口的时候都是一个类一个文件,一个接口一个文件,但有时候为了方便或 ...
- SQL 数据库语句- 创建和管理数据库
SQL CREATE DATABASE 语句 SQL CREATE DATABASE 语句用于创建一个新的 SQL 数据库. 语法 CREATE DATABASE 数据库名称; 示例 以下 SQL 语 ...
- SQL HAVING 子句详解:在 GROUP BY 中更灵活的条件筛选
SQL HAVING子句 HAVING子句被添加到SQL中,因为WHERE关键字不能与聚合函数一起使用. HAVING语法 SELECT column_name(s) FROM table_name ...
- C#对接部标JT808协议实现北斗定位设备数据接收服务端
一.前言介绍 开发一套能够支撑几万台北斗定位设备数据接收的服务端,用于接收北斗定位器定位数据的平台.项目基于windows平台,C#语言开发框架Net Framework4.8,TCP主要基于Supe ...
- 美团一面,面试官让介绍AQS原理并手写一个同步器,直接凉了
写在开头 今天在牛客上看到了一个帖子,一个网友吐槽美团一面上来就让手撕同步器,没整出来,结果面试直接凉凉. 就此联想到一周前写的一篇关于AQS知识点解析的博文,当时也曾埋下伏笔说后面会根据AQS的原理 ...