tensorflow解决回归问题简单案列
1 待拟合函数
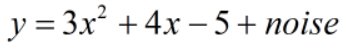
noise服从均值为0,方差为15的正太分布,即noise ~ N(0,15)。
2 基于模型的训练
根据散点图分布特点,猜测原始数据是一个二次函数模型,如下:
其中,a,b,c为待训练参数
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(-10,10,200) #生成200个随机点
noise=np.random.normal(0,15,x.shape) #生成噪声
y=3*np.square(x)+4*x-5+noise
a=tf.Variable(.0)
b=tf.Variable(.0)
c=tf.Variable(.0)
y_=a*np.square(x)+b*x+c #构造一个非线性模型
loss=tf.reduce_mean(tf.square(y-y_))#二次代价函数
optimizer=tf.train.AdamOptimizer(0.2) #Adam自适应学习率优化器
train=optimizer.minimize(loss) #最小化代价函数
init=tf.global_variables_initializer() #变量初始化
with tf.Session() as sess:
sess.run(init)
for epoch in range(601):
sess.run(train)
if epoch>0 and epoch%100==0:
print(epoch,sess.run([a,b,c]),"mse:",sess.run(loss))
pre=sess.run(y_)
plt.figure()
plt.scatter(x,y)
plt.plot(x,pre,'-r',lw=4)
plt.show()
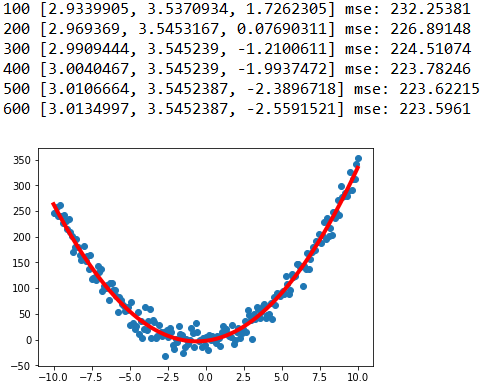
经过600次训练后得到二次函数模型如下:
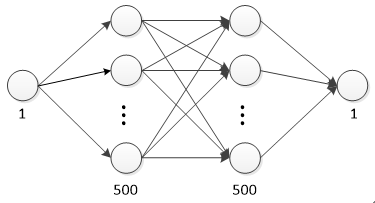
3 基于网络的训练
网络结构如下:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(-10,10,200)[:,np.newaxis] #生成200个随机点
noise=np.random.normal(0,15,x.shape) #生成噪声
y=3*np.square(x)+4*x-5+noise
x_=tf.placeholder(tf.float32,[None,1]) #定义placeholder
y_=tf.placeholder(tf.float32,[None,1]) #定义placeholder
#定义神经网络中间层(layer_1)
w1=tf.Variable(tf.random_normal([1,500]))
b1=tf.Variable(tf.zeros([500]))
z1=tf.matmul(x_,w1)+b1
a1=tf.nn.relu(z1)
#定义神经网络中间层(layer_2)
w2=tf.Variable(tf.random_normal([500,500]))
b2=tf.Variable(tf.zeros([500]))
z2=tf.matmul(a1,w2)+b2
a2=tf.nn.relu(z2)
#定义神经网络输出层
w3=tf.Variable(tf.random_normal([500,1]))
b3=tf.Variable(tf.zeros([1]))
z3=tf.matmul(a2,w3)+b3
loss=tf.reduce_mean(tf.square(y_-z3))#二次代价函数
optimizer=tf.train.FtrlOptimizer(0.2) #Ftrl优化器
train=optimizer.minimize(loss) #最小化代价函数
init=tf.global_variables_initializer() #变量初始化
with tf.Session() as sess:
sess.run(init)
for epoch in range(6001):
sess.run(train,feed_dict={x_:x,y_:y})
if epoch>0 and epoch%1000==0:
mse=sess.run(loss,feed_dict={x_:x,y_:y})
print(epoch,mse)
pre=sess.run(z3,feed_dict={x_:x,y_:y})
plt.figure()
plt.scatter(x,y)
plt.plot(x,pre,'-r',lw=4)
plt.show()
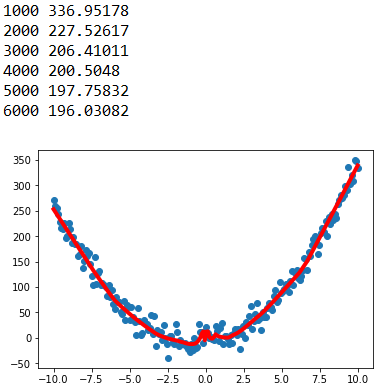
注意:在网络出口处不要加上sigmoid、tanh、relu激活函数进行非线性变换,因为sigmoid函数会将回归值压缩到(0,1),tanh函数会将回归值压缩到(-1,1),relu函数会将回归值映射到(0,+oo),而真实值没有这些限制,导致损失函数的计算不合理,误差反馈较慢,模型不收敛。
另外,可以先将真实值y归一化,记为y1,再将回归值z3与z1比较,计算误差并调节网络权值和偏值,将z3逆归一化的值作为网络预测值。
5 常用优化器
#1.梯度下降优化器
optimizer=tf.train.GradientDescentOptimizer(0.2)
#2.自适应学习率优化器
optimizer=tf.train.AdagradOptimizer(0.2)
#3.自适应学习率优化器
optimizer=tf.train.RMSPropOptimizer(0.2)
#4.Adam自适应学习率优化器
optimizer=tf.train.AdamOptimizer(0.2)
#5.Adadelta优化器
optimizer=tf.train.AdadeltaOptimizer(0.2)
#6.Proximal梯度下降优化器
optimizer=tf.train.ProximalGradientDescentOptimizer(0.2)
#7.Proximal自适应学习率优化器
optimizer=tf.train.ProximalAdagradOptimizer(0.2)
#8.Ftrl优化器
optimizer=tf.train.FtrlOptimizer(0.2)
声明:本文转自tensorflow解决回归问题简单案列
tensorflow解决回归问题简单案列的更多相关文章
- 洗礼灵魂,修炼python(4)--从简单案列中揭示常用内置函数以及数据类型
上一篇说到print语句,print是可以打印任何类型到屏幕上,都有哪些类型呢? 整形(int) 长整型(long) 浮点型(float) 字符型(str) 布尔型(bool) 最常见的就这几种. 在 ...
- 【Python】从简单案列中揭示常用内置函数以及数据类型
前面提到了BIF(内置函数)这个概念,什么是内置函数,就是python已经定义好的函数,不需要人为再自己定义,直接拿来就可以用的函数,那么都有哪些BIF呢? 可以在交互式界面(IDLE)输入这段代码, ...
- 简单案列完美搞定Mvc设计模式
一个小列子搞定Mvc模式,包括数据库以及如何提高用户体验度 1.首先来web.xml配置servlet的访问路径: <?xml version="1.0" encoding= ...
- Tensorflow 中(批量)读取数据的案列分析及TFRecord文件的打包与读取
内容概要: 单一数据读取方式: 第一种:slice_input_producer() # 返回值可以直接通过 Session.run([images, labels])查看,且第一个参数必须放在列表中 ...
- 深入浅出TensorFlow(二):TensorFlow解决MNIST问题入门
2017年2月16日,Google正式对外发布Google TensorFlow 1.0版本,并保证本次的发布版本API接口完全满足生产环境稳定性要求.这是TensorFlow的一个重要里程碑,标志着 ...
- 2021年-在windwos下如何用TOMACT发布一个系统(完整配置案列)
2021年新年第一篇:博主@李宗盛-关于在Windwos下使用TOMCAT发布一个系统的完成配置案列. 之前写过关于TOMCAT的小篇幅文档,比较分散,可以作为对照与参考. 此篇整合在一起,一篇文档写 ...
- Spring MVC的配置文件(XML)的几个经典案列
1.既然是配置文件版的,那配置文件自然是必不可少,且应该会很复杂,那我们就以一个一个的来慢慢分析这些个经典案列吧! 01.实现Controller /* * 控制器 */ public class M ...
- js闭包的作用域以及闭包案列的介绍:
转载▼ 标签: it js闭包的作用域以及闭包案列的介绍: 首先我们根据前面的介绍来分析js闭包有什么作用,他会给我们编程带来什么好处? 闭包是为了更方便我们在处理js函数的时候会遇到以下的几 ...
- 每日学习心得:Linq解决DataTable按照某一列的值排序问题/DataTable 导出CSV文件/巧用text-overflow解决数据绑定列数据展示过长问题
2013-8-5 1 Linq解决DataTable按照某一列的值排序 在之前的总结中提到过对拼接而成的复合的DataTable按照某一列值的大小排序,那个主要的思想是在新建表结构时将要排序的那一列的 ...
- 10分钟搞懂Tensorflow 逻辑回归实现手写识别
1. Tensorflow 逻辑回归实现手写识别 1.1. 逻辑回归原理 1.1.1. 逻辑回归 1.1.2. 损失函数 1.2. 实例:手写识别系统 1.1. 逻辑回归原理 1.1.1. 逻辑回归 ...
随机推荐
- 状态: 失败 -测试失败: IO 错误: The Network Adapter could not establish the connection (CONNECTION_ID=BMRc/8PgR2+0i4PK2tnHQA==)
1.问题 问题如标题所示,在使用Oracle SQL Developer连接时发现错误: 状态: 失败 -测试失败: IO 错误: The Network Adapter could not esta ...
- [转帖]RAC AWR重要指标说明
1.Global Cache Load Profile Global Cache blocks received: 接收到的全局缓冲块 Global Cache blocks served: 发送的 ...
- [转帖]TiDB 数据库统计表的大小方法
简介:TiDB统计表的大小,列出了一些方法: 1.第一种的统计方式: 基于统计表 METRICS_SCHEMA.store_size_amplification 要预估 TiDB 中一张表的大小,你可 ...
- [转帖]jmeter实现不写代码把测试结果存入execl
这里使用数据库作为中间件来实现不写代码就把测试结果存入execl,下面是步骤 1.新建一个setup线程组用来设置数据库连接信息和新建数据库,如下图所示,我们使用sqlite数据库来存储信息,因为不需 ...
- [转帖]JMETER结果分析
https://www.cnblogs.com/a00ium/p/10462892.html 我相信你同意:有很多方法可以收集和解释JMeter结果,你会感到迷茫. 嗯,看完这篇文章后,您将了解收集和 ...
- [转帖]kafka搭建kraft集群模式
kafka2.8之后不适用zookeeper进行leader选举,使用自己的controller进行选举 1.准备工作 准备三台服务器 192.168.3.110 192.168.3.111 192. ...
- 【转帖】基于paramiko的二次封装
https://www.jianshu.com/p/944674f44b24 paramiko 是 Python 中的一个用来连接远程主机的第三方工具,通过使用 paramiko 可以用来代替以 ss ...
- Redis7.0 编译安装以及简单创建Cluster测试服务器的方法
背景 北京时间2022.4.27 晚上九点半左右, Redis 7.0.0 已经GA. 为了进行简单的学习, 这边进行了简单验证工作. 本次主要分为编译, 测试集群搭建,以及springboot进行简 ...
- It is currently in use by another Gradle instance
FAILURE: Build failed with an exception. * What went wrong: Could not create service of type TaskHis ...
- Fabric区块链浏览器(1)
本文是区块链浏览器系列的第三篇,本文介绍区块链浏览器的主体部分,即区块数据的解析. 这一版本的区块链浏览器是基于gin实现的,只提供三种接口: /block/upload:POST,上传Protobu ...