[转帖]TiDB 内存控制文档
https://docs.pingcap.com/zh/tidb/stable/configure-memory-usage
目前 TiDB 已经能够做到追踪单条 SQL 查询过程中的内存使用情况,当内存使用超过一定阈值后也能采取一些操作来预防 OOM 或者排查 OOM 原因。你可以使用系统变量 tidb_mem_oom_action 来控制查询超过内存限制后所采取的操作:
- 如果变量值为
LOG,那么当一条 SQL 的内存使用超过一定阈值(由 session 变量tidb_mem_quota_query控制)后,这条 SQL 会继续执行,但 TiDB 会在 log 文件中打印一条 LOG。 - 如果变量值为
CANCEL,那么当一条 SQL 的内存使用超过一定阈值后,TiDB 会立即中断这条 SQL 的执行,并给客户端返回一个错误,错误信息中会详细写明在这条 SQL 执行过程中占用内存的各个物理执行算子的内存使用情况。
如何配置一条 SQL 执行过程中的内存使用阈值
使用系统变量 tidb_mem_quota_query 来配置一条 SQL 执行过程中的内存使用阈值,单位为字节。例如:
配置整条 SQL 的内存使用阈值为 8GB:
配置整条 SQL 的内存使用阈值为 8MB:
配置整条 SQL 的内存使用阈值为 8KB:
如何配置 tidb-server 实例使用内存的阈值
自 v6.5.0 版本起,可以通过系统变量 tidb_server_memory_limit 设置 tidb-server 实例的内存使用阈值。
例如,配置 tidb-server 实例的内存使用总量,将其设置成为 32 GB:
设置该变量后,当 tidb-server 实例的内存用量达到 32 GB 时,TiDB 会依次终止正在执行的 SQL 操作中内存用量最大的 SQL 操作,直至 tidb-server 实例内存使用下降到 32 GB 以下。被强制终止的 SQL 操作会向客户端返回报错信息 Out Of Memory Quota!。
当前 tidb_server_memory_limit 所设的内存限制不终止以下 SQL 操作:
- DDL 操作
- 包含窗口函数和公共表表达式的 SQL 操作
- TiDB 在启动过程中不保证
tidb_server_memory_limit限制生效。如果操作系统的空闲内存不足,TiDB 仍有可能出现 OOM。你需要确保 TiDB 实例有足够的可用内存。 - 在内存控制过程中,TiDB 的整体内存使用量可能会略微超过
tidb_server_memory_limit的限制。 server-memory-quota配置项自 v6.5.0 起被废弃。为了保证兼容性,在升级到 v6.5.0 或更高版本的集群后,tidb_server_memory_limit会继承配置项server-memory-quota的值。如果集群在升级至 v6.5.0 或更高版本前没有配置server-memory-quota,tidb_server_memory_limit会使用默认值,即80%。
在 tidb-server 实例内存用量到达总内存的一定比例时(比例由系统变量 tidb_server_memory_limit_gc_trigger 控制), tidb-server 会尝试主动触发一次 Golang GC 以缓解内存压力。为了避免实例内存在阈值上下范围不断波动导致频繁 GC 进而带来的性能问题,该 GC 方式 1 分钟最多只会触发 1 次。
在混合部署的情况下,tidb_server_memory_limit 为单个 tidb-server 实例的内存使用阈值,而不是整个物理机的总内存阈值。
使用 INFORMATION_SCHEMA 系统表查看当前 tidb-server 的内存用量
要查看当前实例或集群的内存使用情况,你可以查询系统表 INFORMATION_SCHEMA.(CLUSTER_)MEMORY_USAGE。
要查看本实例或集群中内存相关的操作和执行依据,可以查询系统表 INFORMATION_SCHEMA.(CLUSTER_)MEMORY_USAGE_OPS_HISTORY。对于每个实例,该表保留最近 50 条记录。
tidb-server 内存占用过高时的报警
当 tidb-server 实例的内存使用量超过内存阈值(默认为总内存量的 70%)且满足以下任一条件时,TiDB 将记录相关状态文件,并打印报警日志。
- 第一次内存使用量超过内存阈值。
- 内存使用量超过内存阈值,且距离上一次报警超过 60 秒。
- 内存使用量超过内存阈值,且
(本次内存使用量 - 上次报警时内存使用量) / 总内存量 > 10%。
你可以通过系统变量 tidb_memory_usage_alarm_ratio 修改触发该报警的内存使用比率,从而控制内存报警的阈值。
当触发 tidb-server 内存占用过高的报警时,TiDB 的报警行为如下:
TiDB 将以下信息记录到 TiDB 日志文件
filename所在目录中。- 当前正在执行的所有 SQL 语句中内存使用最高的 10 条语句和运行时间最长的 10 条语句的相关信息
- goroutine 栈信息
- 堆内存使用状态
TiDB 将输出一条包含关键字
tidb-server has the risk of OOM以及以下内存相关系统变量的日志。
为避免报警时产生的状态文件累积过多,目前 TiDB 默认只保留最近 5 次报警时所生成的状态文件。你可以通过配置系统变量 tidb_memory_usage_alarm_keep_record_num 调整该次数。
下例通过构造一个占用大量内存的 SQL 语句触发报警,对该报警功能进行演示:
配置报警比例为
0.85:SET GLOBAL tidb_memory_usage_alarm_ratio = 0.85;创建单表
CREATE TABLE t(a int);并插入 1000 行数据。执行
select * from t t1 join t t2 join t t3 order by t1.a。该 SQL 语句会输出 1000000000 条记录,占用巨大的内存,进而触发报警。检查
tidb.log文件,其中会记录系统总内存、系统当前内存使用量、tidb-server 实例的内存使用量以及状态文件所在目录。[2022/10/11 16:39:02.281 +08:00] [WARN] [memoryusagealarm.go:212] ["tidb-server has the risk of OOM because of memory usage exceeds alarm ratio. Running SQLs and heap profile will be recorded in record path"] ["is tidb_server_memory_limit set"=false] ["system memory total"=33682427904] ["system memory usage"=22120655360] ["tidb-server memory usage"=21468556992] [memory-usage-alarm-ratio=0.85] ["record path"=/tiup/deploy/tidb-4000/log/oom_record]以上 Log 字段的含义如下:
is tidb_server_memory_limit set:表示系统变量tidb_server_memory_limit是否被设置system memory total:表示当前系统的总内存system memory usage:表示当前系统的内存使用量tidb-server memory usage:表示 tidb-server 实例的内存使用量memory-usage-alarm-ratio:表示系统变量tidb_memory_usage_alarm_ratio的值record path:表示状态文件存放的目录
通过访问状态文件所在目录(该示例中的目录为
/tiup/deploy/tidb-4000/log/oom_record),可以看到标记了记录时间的 record 目录(例:record2022-10-09T17:18:38+08:00),其中包括goroutinue、heap、running_sql3 个文件,文件以记录状态文件的时间为后缀。这 3 个文件分别用来记录报警时的 goroutine 栈信息,堆内存使用状态,及正在运行的 SQL 信息。其中running_sql文件内容请参考expensive-queries。
tidb-server 其它内存控制策略
流量控制
- TiDB 支持对读数据算子的动态内存控制功能。读数据的算子默认启用
tidb_distsql_scan_concurrency所允许的最大线程数来读取数据。当单条 SQL 语句的内存使用每超过tidb_mem_quota_query一次,读数据的算子就会停止一个线程。 - 流控行为由参数
tidb_enable_rate_limit_action控制。 - 当流控被触发时,会在日志中打印一条包含关键字
memory exceeds quota, destroy one token now的日志。
数据落盘
TiDB 支持对执行算子的数据落盘功能。当 SQL 的内存使用超过 Memory Quota 时,tidb-server 可以通过落盘执行算子的中间数据,缓解内存压力。支持落盘的算子有:Sort、MergeJoin、HashJoin、HashAgg。
- 落盘行为由参数
tidb_mem_quota_query、tidb_enable_tmp_storage_on_oom、tmp-storage-path、tmp-storage-quota共同控制。 - 当落盘被触发时,TiDB 会在日志中打印一条包含关键字
memory exceeds quota, spill to disk now或memory exceeds quota, set aggregate mode to spill-mode的日志。 - Sort、MergeJoin、HashJoin 落盘是从 v4.0.0 版本开始引入的,HashAgg 落盘是从 v5.2.0 版本开始引入的。
- 当包含 Sort、MergeJoin 或 HashJoin 的 SQL 语句引起内存 OOM 时,TiDB 默认会触发落盘。当包含 HashAgg 算子的 SQL 语句引起内存 OOM 时,TiDB 默认不触发落盘,请设置系统变量
tidb_executor_concurrency = 1来触发 HashAgg 落盘功能。
- HashAgg 落盘功能目前不支持 distinct 聚合函数。使用 distinct 函数且内存占用过大时,无法进行落盘。
本示例通过构造一个占用大量内存的 SQL 语句,对 HashAgg 落盘功能进行演示:
将 SQL 语句的 Memory Quota 配置为 1GB(默认 1GB):
SET tidb_mem_quota_query = 1 << 30;创建单表
CREATE TABLE t(a int);并插入 256 行不同的数据。尝试执行以下 SQL 语句:
[tidb]> explain analyze select /*+ HASH_AGG() */ count(*) from t t1 join t t2 join t t3 group by t1.a, t2.a, t3.a;该 SQL 语句占用大量内存,返回 Out of Memory Quota 错误。
ERROR 1105 (HY000): Out Of Memory Quota![conn_id=3]设置系统变量
tidb_executor_concurrency将执行器的并发度调整为 1。在此配置下,内存不足时 HashAgg 会自动尝试触发落盘。SET tidb_executor_concurrency = 1;执行相同的 SQL 语句,不再返回错误,可以执行成功。从详细的执行计划可以看出,HashAgg 使用了 600MB 的硬盘空间。
[tidb]> explain analyze select /*+ HASH_AGG() */ count(*) from t t1 join t t2 join t t3 group by t1.a, t2.a, t3.a;+---------------------------------+-------------+----------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------+-----------+----------+ | id | estRows | actRows | task | access object | execution info | operator info | memory | disk | +---------------------------------+-------------+----------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------+-----------+----------+ | HashAgg_11 | 204.80 | 16777216 | root | | time:1m37.4s, loops:16385 | group by:test.t.a, test.t.a, test.t.a, funcs:count(1)->Column#7 | 1.13 GB | 600.0 MB | | └─HashJoin_12 | 16777216.00 | 16777216 | root | | time:21.5s, loops:16385, build_hash_table:{total:267.2µs, fetch:228.9µs, build:38.2µs}, probe:{concurrency:1, total:35s, max:35s, probe:35s, fetch:962.2µs} | CARTESIAN inner join | 8.23 KB | 4 KB | | ├─TableReader_21(Build) | 256.00 | 256 | root | | time:87.2µs, loops:2, cop_task: {num: 1, max: 150µs, proc_keys: 0, rpc_num: 1, rpc_time: 145.1µs, copr_cache_hit_ratio: 0.00} | data:TableFullScan_20 | 885 Bytes | N/A | | │ └─TableFullScan_20 | 256.00 | 256 | cop[tikv] | table:t3 | tikv_task:{time:23.2µs, loops:256} | keep order:false, stats:pseudo | N/A | N/A | | └─HashJoin_14(Probe) | 65536.00 | 65536 | root | | time:728.1µs, loops:65, build_hash_table:{total:307.5µs, fetch:277.6µs, build:29.9µs}, probe:{concurrency:1, total:34.3s, max:34.3s, probe:34.3s, fetch:278µs} | CARTESIAN inner join | 8.23 KB | 4 KB | | ├─TableReader_19(Build) | 256.00 | 256 | root | | time:126.2µs, loops:2, cop_task: {num: 1, max: 308.4µs, proc_keys: 0, rpc_num: 1, rpc_time: 295.3µs, copr_cache_hit_ratio: 0.00} | data:TableFullScan_18 | 885 Bytes | N/A | | │ └─TableFullScan_18 | 256.00 | 256 | cop[tikv] | table:t2 | tikv_task:{time:79.2µs, loops:256} | keep order:false, stats:pseudo | N/A | N/A | | └─TableReader_17(Probe) | 256.00 | 256 | root | | time:211.1µs, loops:2, cop_task: {num: 1, max: 295.5µs, proc_keys: 0, rpc_num: 1, rpc_time: 279.7µs, copr_cache_hit_ratio: 0.00} | data:TableFullScan_16 | 885 Bytes | N/A | | └─TableFullScan_16 | 256.00 | 256 | cop[tikv] | table:t1 | tikv_task:{time:71.4µs, loops:256} | keep order:false, stats:pseudo | N/A | N/A | +---------------------------------+-------------+----------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------+-----------+----------+ 9 rows in set (1 min 37.428 sec)
其它
设置环境变量 GOMEMLIMIT 缓解 OOM 问题
Golang 自 Go 1.19 版本开始引入 GOMEMLIMIT 环境变量,该变量用来设置触发 Go GC 的内存上限。
对于 v6.1.3 <= TiDB < v6.5.0 的版本,你可以通过手动设置 Go GOMEMLIMIT 环境变量的方式来缓解一类 OOM 问题。该类 OOM 问题具有一个典型特征:观察 Grafana 监控,OOM 前的时刻,TiDB-Runtime > Memory Usage 面板中 estimate-inuse 立柱部分在整个立柱中仅仅占一半。如下图所示:
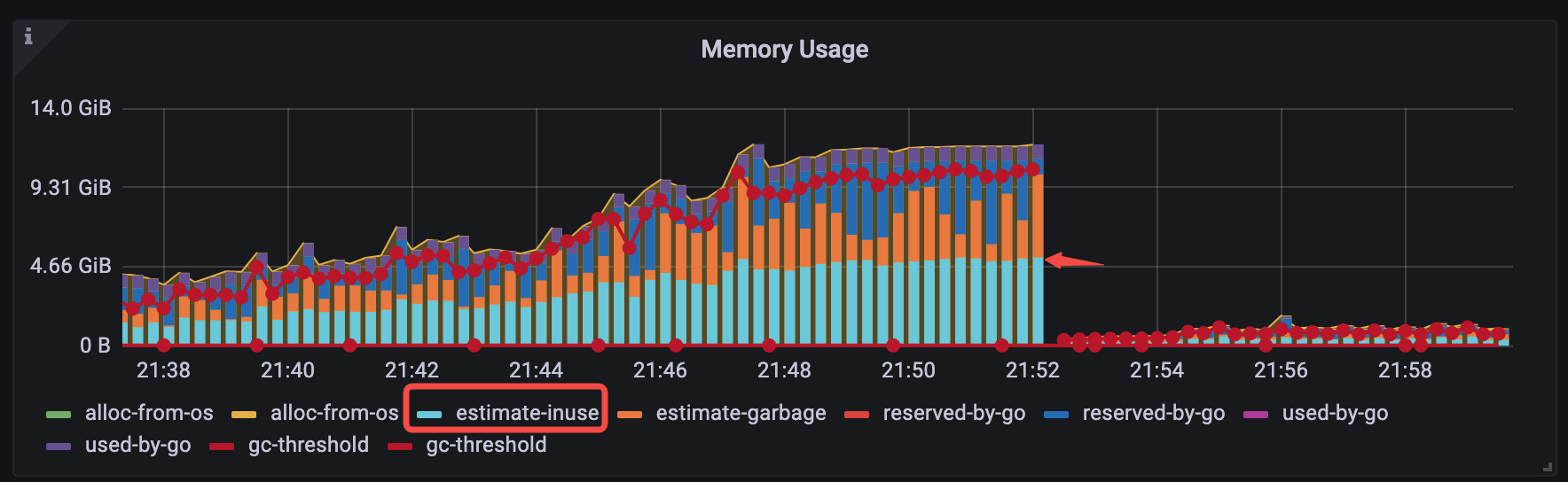
为了验证 GOMEMLIMIT 在该类场景下的效果,以下通过一个对比实验进行说明:
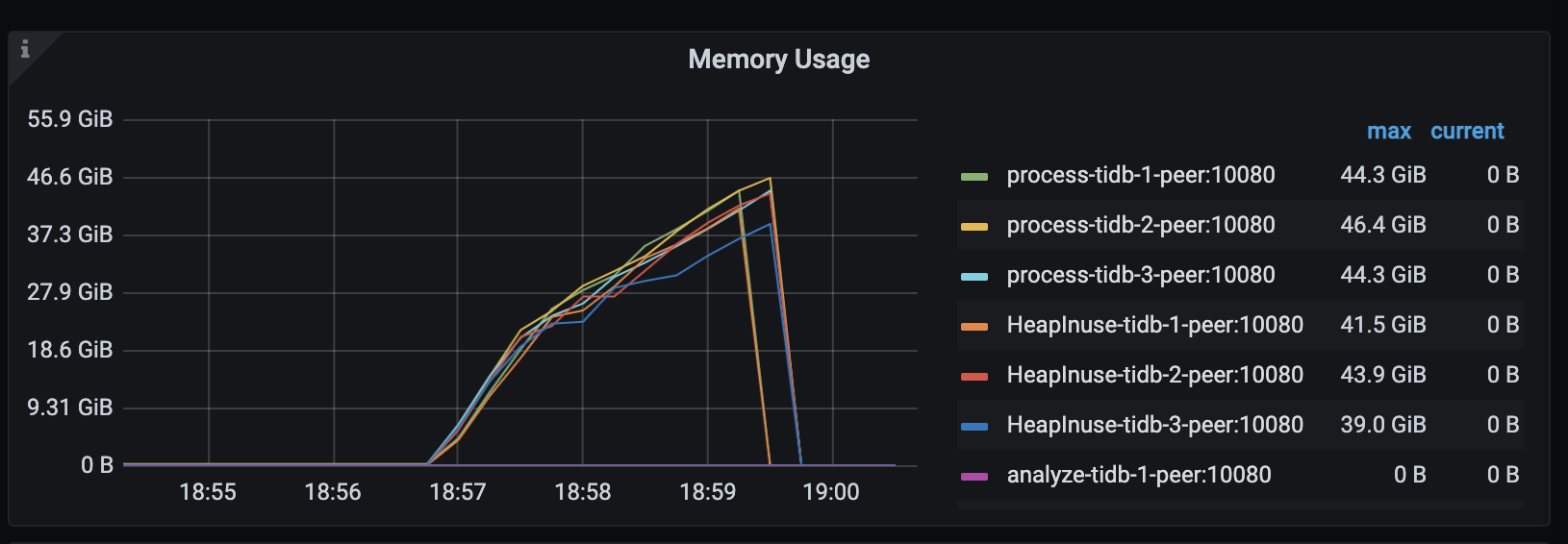
在 TiDB v6.1.2 下,模拟负载在持续运行几分钟后,TiDB server 会发生 OOM(系统内存约 48 GiB):
在 TiDB v6.1.3 下,设置
GOMEMLIMIT为 40000 MiB,模拟负载长期稳定运行、TiDB server 未发生 OOM 且进程最高内存用量稳定在 40.8 GiB 左右: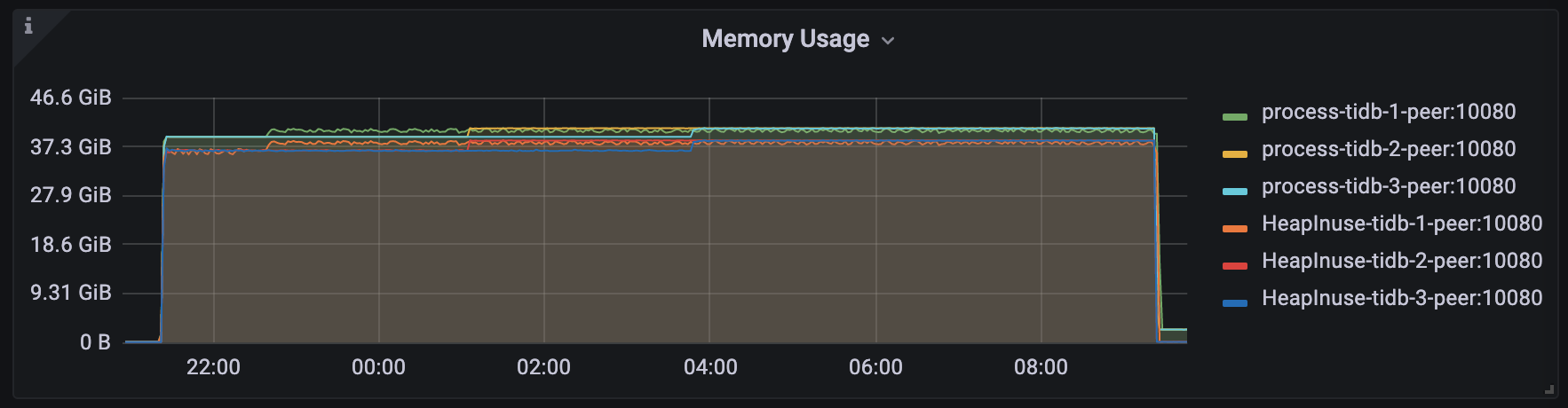
[转帖]TiDB 内存控制文档的更多相关文章
- FreeRTOS内存管理文档
heap1.c:只能申请内存,不能释放内存.适合运行后不申请新内存的程序. heap2.c: 既能申请内存,也能释放内存,但释放内存后,相邻的空余内存不能合并.适合每次申请相同大小内存的变量的程序使用 ...
- sharepoint 2013 文档库eventhandle权限控制
记录一下如何在sharepoint server 2013文档库中,使用eventhandle控制文档库document library的条目item权限. ///<summary> // ...
- 在asp.net core2.1中添加中间件以扩展Swashbuckle.AspNetCore3.0支持简单的文档访问权限控制
Swashbuckle.AspNetCore3.0 介绍 一个使用 ASP.NET Core 构建的 API 的 Swagger 工具.直接从您的路由,控制器和模型生成漂亮的 API 文档,包括用于探 ...
- 段合并 segments merge 被删除的文档的删除时间
2.5 段合并 每个索引分为多个“写一次,读多次”的段 write once and read many times segments 建立索引时,一个段写入磁盘以后就不能更新:被删除的文档的信息存 ...
- DOM和SAX是应用中操纵XML文档的差别
查看原文:http://www.ibloger.net/article/205.html DOM和SAX是应用中操纵XML文档的两种主要API.它们分别解释例如以下: DOM.即Do ...
- vxWidgets(二):接口文档
第一章 介绍 在这一章中,我们会回答这样一些基本的问题:wxWidgets是什么,它和别的类似的开发库有什么不同.我们还会大概说一下这个项目的历史,以及wxWidgets社区的工作,它采用的许可协议, ...
- 四种生成和解析XML文档的方法详解(介绍+优缺点比较+示例)
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml- ...
- JCarouselLite--帮助文档
jcarousellite是一款jquery插件,可以控制文档元素滚动,丰富的参数设置可以控制滚动的更多细节,是一款不可多得的滚动插件. ------------------ 官网地址:http:// ...
- Indri中的动态文档索引技术
Indri中的动态文档索引技术 戴维 译 摘要: Indri 动态文档索引的实现技术,支持在更新索引的同时处理用户在线查询请求. 文本搜索引擎曾被设计为针对固定的文档集合进行查询,对不少应用来说,这种 ...
- 浅谈用java解析xml文档(三)
接上一篇,本文介绍使用JDOM解析xml文档, 首先我们还是应该知道JDOM从何而来,是Breet Mclaughlin和Jason Hunter两大Java高手的创作成果,2000年初, JDOM作 ...
随机推荐
- 高版本jdk的访问私有成员属性的正确姿势
在jdk17+已经不能直接通过 setAccessible 来访问私有属性了 Field name = access.getClass().getDeclaredField("name&qu ...
- 从C++CLI工程的依赖库引用问题看.Net加载程序集机制
问题 最近在为某第三方MFC项目写C++/CLI工程插件时遇到了如下一个问题: MFC的工程不允许把.Net的依赖程序集放到执行程序的目录(防止影响其稳定性),依赖库只能放到非执行程序子目录的其他目录 ...
- C++篇:第十四章_编程_知识点大全
C++篇为本人学C++时所做笔记(特别是疑难杂点),全是硬货,虽然看着枯燥但会让你收益颇丰,可用作学习C++的一大利器 十四.编程 (一)概念 系统函数及其库是 C++语言所必须的,预处理命令不是 C ...
- 第十三部分_awk
一.awk介绍 1. awk概述 awk是一种编程语言,主要用于在linux/unix下对文本和数据进行处理,是linux/unix下的一个工具.数据可以来自标准输入.一个或多个文件,或其它命令的输出 ...
- 容器中域名解析流程以及不同dnsPolicy对域名解析影响
本文分享自华为云社区<容器中域名解析流程以及不同dnsPolicy对域名解析影响>,作者:可以交个朋友 . 一.coreDNS背景 部署在kubernetes集群中的容器业务通过coreD ...
- 【华为云技术分享】40%性能提升,华为云推出PostgreSQL 12 商用版
摘要:日前,华为云数据库正式推出了RDS for PostgreSQL 12版本,并开始商用.本文将从华为云RDS for PostgreSQL 12的4大特性和架构图等多方面来解读华为云Postgr ...
- 华为云IoT智简联接,开启物联世界新纪元
摘要:华为云IoT将聚焦物联网技术和商业基础能力建设,联接万物.联接生态.联接行业,帮助各行各业做好数字化转型. 近日,华为云通过线上专题演讲发布了IoT最新战略.华为云IoT将聚焦物联网基础能力(包 ...
- Nacos是什么?
摘要:Nacos是 Dynamic Naming and Configuration Service的首字母简称,相较之下,它更易于构建云原生应用的动态服务发现.配置管理和服务管理平台. 本文分享自华 ...
- Nginx在windows下常用命令
cmd 进入Nginx解压目录 执行以下命令 start nginx : 启动nginx服务 nginx -s reload :修改配置后重新加载生效 nginx -s reopen :重新打开日志文 ...
- python argparse传入布尔参数不生效解决
前言 在一个需要用到flag作为信号控制代码中一些代码片段是否运行的,比如"--flag True"或者"--flag False". 但是古怪的是无法传入Fa ...