大数据学习——spark-steaming学习
官网http://spark.apache.org/docs/latest/streaming-programming-guide.html
1.1. 用Spark Streaming实现实时WordCount
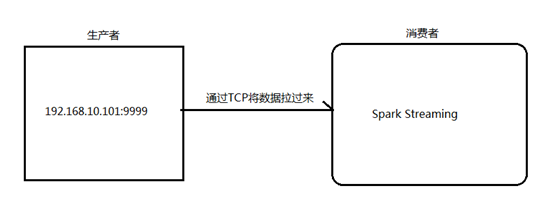
1.安装并启动生成者
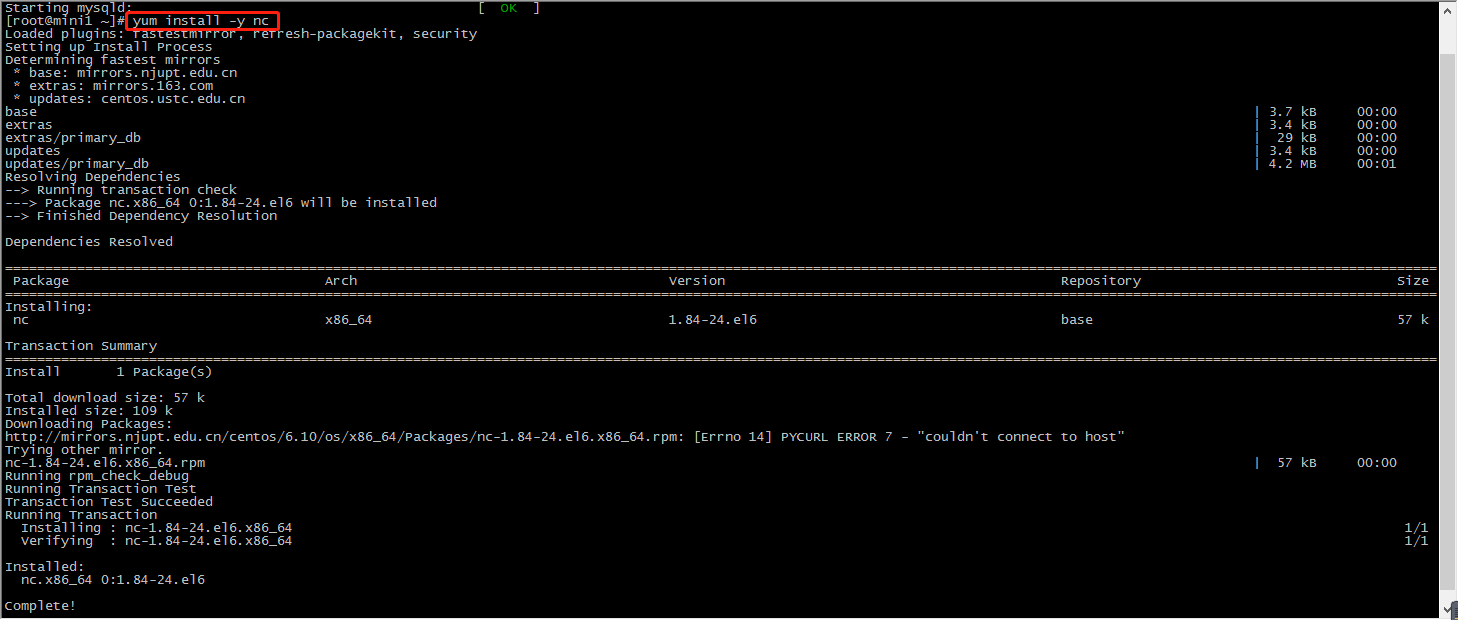
首先在一台Linux(ip:192.168.10.101)上用YUM安装nc工具
yum install -y nc
启动一个服务端并监听9999端口
nc -lk 9999
2.编写Spark Streaming程序
package org.apache.spark import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds object TCPWordCount {
def main(args: Array[String]) {
//setMaster("local[2]")本地执行2个线程,一个用来接收消息,一个用来计算
val conf = new SparkConf().setMaster("local[2]").setAppName("TCPWordCount")
//创建spark的streaming,传入间隔多长时间处理一次,间隔在5秒左右,否则打印控制台信息会被冲掉
val scc = new StreamingContext(conf, Seconds(5))
//读取数据的地址:从某个ip和端口收集数据
val lines = scc.socketTextStream("192.168.74.100", 9999) //进行rdd处理 val results = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) //将结果打印控制台 results.print() //启动spark streaming scc.start() //等待终止 scc.awaitTermination() } }
3.启动Spark Streaming程序:由于使用的是本地模式"local[2]"所以可以直接在本地运行该程序
注意:要指定并行度,如在本地运行设置setMaster("local[2]"),相当于启动两个线程,一个给receiver,一个给computer。如果是在集群中运行,必须要求集群中可用core数大于1
4.在Linux端命令行中输入单词

5.在IDEA控制台中查看结果
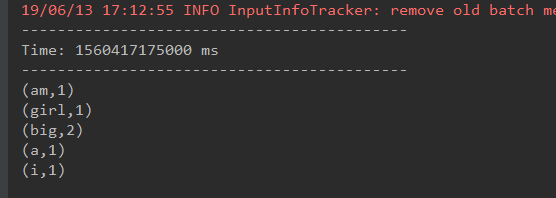
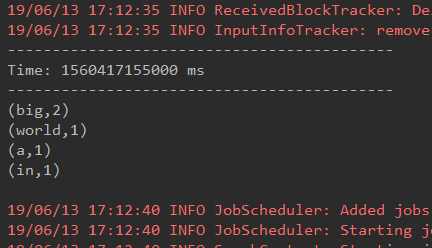
问题:结果每次在Linux段输入的单词次数都被正确的统计出来,但是结果不能累加!如果需要累加需要使用updateStateByKey(func)来更新状态,下面给出一个例子:
package org.apache.spark import org.apache.spark.HashPartitioner
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext object TCPWordCountUpdate {
/**
* String:某个单词
* Seq:[1,1,1,1,1,1],当前批次出现的次数的序列
* Option:历史的结果的sum
*/ val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
iter.map(t => (t._1, t._2.sum + t._3.getOrElse(0)))
//iter.map{case(x,y,z)=>(x,y.sum+z.getOrElse(0))}
} def updateFunction2(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
Some(newValues.sum + runningCount.getOrElse(0))
} def main(args: Array[String]) {
//setMaster("local[2]")本地执行2个线程,一个用来接收消息,一个用来计算
val conf = new SparkConf().setMaster("local[2]").setAppName("TCPWordCount")
//创建spark的streaming,传入间隔多长时间处理一次,间隔在5秒左右,否则打印控制台信息会被冲掉
val scc = new StreamingContext(conf, Seconds(5))
scc.checkpoint("./")//读取数据的地址:从某个ip和端口收集数据
val lines = scc.socketTextStream("192.168.74.100", 9999)
//进行rdd处理
/**
* updateStateByKey()更新数据
* 1、更新数据的具体实现函数
* 2、分区信息
* 3、boolean值
*/
//val results = lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunction2 _)
val results = lines.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunction, new HashPartitioner(scc.sparkContext.defaultParallelism), true)
//将结果打印控制台
results.print()
//启动spark streaming
scc.start()
//等待终止
scc.awaitTermination()
}
}
1.1. 使用reduceByKeyAndWindow计算每分钟数据
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext} object SparkSqlTest {
def main(args: Array[String]) {
LoggerLevels.setStreamingLogLevels()
val conf = new SparkConf().setAppName("sparksql").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("./")
val textStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.74.100",9999)
val result: DStream[(String, Int)] = textStream.flatMap(_.split(" ")).map((_,1)).reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(5),Seconds(5))
result.print()
ssc.start()
ssc.awaitTermination()
}
}
1.1. Spark Streaming整合Kafka完成网站点击流实时统计
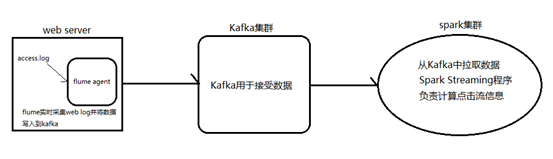
1.安装并配置zk
2.安装并配置Kafka
3.启动zk
4.启动Kafka
5.创建topic
bin/kafka-topics.sh --create --zookeeper node1.itcast.cn:2181,node2.itcast.cn:2181 \
--replication-factor 3 --partitions 3 --topic urlcount
6.编写Spark Streaming应用程序
package cn.itcast.spark.streaming
package cn.itcast.spark
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object UrlCount {
val updateFunc = (iterator: Iterator[(String, Seq[Int], Option[Int])]) => {
iterator.flatMap{case(x,y,z)=> Some(y.sum + z.getOrElse(0)).map(n=>(x, n))}
}
def main(args: Array[String]) {
//接收命令行中的参数
// val Array(zkQuorum, groupId, topics, numThreads, hdfs) = args
val Array(zkQuorum, groupId, topics, numThreads) = Array[String]("master1ha:2181,master2:2181,master2ha:2181","g1","wangsf-test","2")
//创建SparkConf并设置AppName
val conf = new SparkConf().setAppName("UrlCount")
//创建StreamingContext
val ssc = new StreamingContext(conf, Seconds(2))
//设置检查点
ssc.checkpoint(hdfs)
//设置topic信息
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//重Kafka中拉取数据创建DStream
val lines = KafkaUtils.createStream(ssc, zkQuorum ,groupId, topicMap, StorageLevel.MEMORY_AND_DISK).map(_._2)
//切分数据,截取用户点击的url
val urls = lines.map(x=>(x.split(" ")(6), 1))
//统计URL点击量
val result = urls.updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
//将结果打印到控制台
result.print()
ssc.start()
ssc.awaitTermination()
}
}
生产数据测试:
kafka-console-producer.sh --broker-list h2slave1:9092 --topic wangsf-test
大数据学习——spark-steaming学习的更多相关文章
- 【互动问答分享】第8期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第8期互动问答分享] Q1:spark线上用什么版本好? 建议从最低使用的Spark 1.0.0版本,Spark在1.0.0开始核心 ...
- 【互动问答分享】第15期决胜云计算大数据时代Spark亚太研究院公益大讲堂
"决胜云计算大数据时代" Spark亚太研究院100期公益大讲堂 [第15期互动问答分享] Q1:AppClient和worker.master之间的关系是什么? AppClien ...
- 【互动问答分享】第13期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第13期互动问答分享] Q1:tachyon+spark框架现在有很多大公司在使用吧? Yahoo!已经在长期大规模使用: 国内也有 ...
- 【互动问答分享】第10期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第10期互动问答分享] Q1:Spark on Yarn的运行方式是什么? Spark on Yarn的运行方式有两种:Client ...
- 【互动问答分享】第7期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第7期互动问答分享] Q1:Spark中的RDD到底是什么? RDD是Spark的核心抽象,可以把RDD看做“分布式函数编程语言”. ...
- 【互动问答分享】第6期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第6期互动问答分享] Q1:spark streaming 可以不同数据流 join吗? Spark Streaming不同的数据流 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 大数据技术之_16_Scala学习_01_Scala 语言概述
第一章 Scala 语言概述1.1 why is Scala 语言?1.2 Scala 语言诞生小故事1.3 Scala 和 Java 以及 jvm 的关系分析图1.4 Scala 语言的特点1.5 ...
随机推荐
- web标准、可用性、可访问性
前言:大家不难发现,只要是招聘UED相关的岗位,如前端开发工程师.交互设计师.用户研究员甚至视觉设计师,一般都对web标准.可用性和可访问性的理解有要求.那么到底什么是web标准.可用性.可访问性呢? ...
- windows服务器安装安全狗时服务名如何填写
安全狗安装时“服务名”这一栏指的是apache进程的服务名称,即进入“任务管理-服务”里显示的名称. phpstudy等软件搭建的环境需要设置运行模式为“系统服务”后才能看到服务名.
- Mac版 Slickedit 2013 v18.0.3.3 破解
今天在Windows机器上面,无调试器的情况下,把 Mac系统下的Slickedit给破解了并测试通过. 原始安装包下载: Mac Slickedit 2013 (v18.0.3.3) 破解文件下载地 ...
- gitinore修改不生效
.gitignore只能忽略那些尚未被被track的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的.一个简单的解决方法就是先把本地缓存删除(改变成未track状态),然后 ...
- 深度探索C++对象模型——关于对象
引言 以前读<C++ Primer>的时候一直有一种感觉:该书虽然是C++入门书籍,初学者读之却觉晦涩,越往后读越是如此.等到稍加理解后再读该书,顿感醍醐灌顶,茅塞顿开.究其原因,在于原作 ...
- Modelsim与Simulink协同仿真
当使用硬件描述语言(HDL)完成电路设计时,往往需要编写Testbench对所设计的电路进行仿真验证,测试设计电路的功能是否与预期的目标相符.而编写Testbench难度之大,这时可以借助交互式图形化 ...
- This implementation is not part of the Windows Platform FIPS validated cryptographic algorithms while caching
今天运行自己的网站时报了这样一个错误,很是纳闷,这个网站运行了这么久,怎么报这个错呢,原来是做缓存的时候用到了基于windows平台的加密算法.解决方法如下: 删除注册表下的这个节点即可.删除HKEY ...
- Android(java)学习笔记131:关于构造代码块,构造函数的一道面试题(华为面试题)
1. 代码实例: package text; public class TestStaticCon { public static int a = 0; static { a = 10; System ...
- [视觉] 基于YoloV3的实时摄像头记牌器
基于YoloV3的实时摄像头记牌器 github:https://github.com/aoru45/cards_recognition_recorder_pytorch 最终效果 数据准备 数据获取 ...
- JavaScript 获取对象中第一个属性
使用 Object.keys(object) 可以取出属性名为数组,但会打乱顺序 严格意义上对象中是只有映射关系而没有顺序的,但是在存储结构里是有顺序的,如果想获取存储结构里的第一个属性可以使用for ...