爬山算法 | Java版HA_TSP
嗯哼,今天记录下采用Java编写的爬山算法(Hill Algorithm)求解TSP问题。
爬山算法与其他智能算法类似,是一种用来求解多峰函数最值的算法,爬山算法的基本思想是新解不劣于当前解则转移,否则不转移。通俗的解说是兔子爬山的例子,其他博客上介绍的十分细致,在此不再赘述。
爬山算法的算法描述为:
- Step1:初始化。通过某种方法产生初始解S0,令当前解S = S0,全局最优解的值bs = inf,全局最优解BS = S0,当前迭代次数count = 0,最大迭代次数为MaxCount;
- Step2:评价当前解。通过评价函数 Eval() 对当前解S进行评价;
- Step3:更新最优解。如果 Eval(S) 优于(或不劣于) bs,则令全局最优解BS = S,全局最优解的值bs = Eval(BS);
- Step3:更新当前解。令当前解S = BS,迭代次数count++;
- Step4:终止条件判定。如果count < MaxCount, 转至Step2,否者终止程序,输出结果。
下面上干货:
package Hill_Algorithm; import java.util.Random; /**
* @file_name SATSP.java
* @author Alex Xu
* @date 2018/8/11
* @detail Simulated Annealing to solve Travel Salesman Problem
*/ public class HATSP { public static double[] HA() { //参数列表
int MaxCount = 10000; //初始化
double[][] xy = Data.XY();
int N = xy.length; double bs ;
double Nowbs;
int[] BS = new int[N];
int[] S = new int[N]; //生成随机初始解
for (int i = 0; i < N; i++) {
S[i] = i + 1;
}
for (int k = 0; k < N;k++) {
Random rand = new Random();
int r = rand.nextInt(N);
int tmp;
tmp = S[r];
S[r] = S[k];
S[k] = tmp;
}
bs = Evaluate.Eval(S); //进入迭代过程
int effI = 0;
for (int count = 0; count < MaxCount; count++) { //产生一个新解
int[] newS = new int[N];
double R = Math.random(); if (R < 0.33) {
newS = Sharking.Swap(S);
}else if (R > 0.67) {
newS = Sharking.Insert(S);
}else {
newS = Sharking.Flip(S);
}
Nowbs = Evaluate.Eval(newS); //解的更新
if (Nowbs < bs) {
bs = Nowbs;
effI++;
System.out.println( "第 " + effI + "次有效迭代出现在第 " + count + "次迭代,对应的解为 " + bs);
System.arraycopy(newS, 0, BS, 0, N);
}
System.arraycopy(BS, 0, S, 0, N);
} //结果输出
double[] Solution = new double[N + 2];
Solution[0] = bs;
Solution[1] = MaxCount; for (int i = 2; i < N+2; i++) {
Solution[i] = BS[i-2];
}
return Solution;
}
}
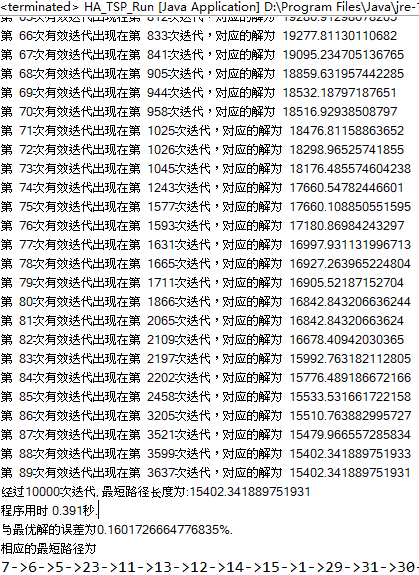
求解31个城市的TSP,求解结果如下,程序总迭代次数为10000次,有效迭代次数为89次,最后一次有效迭代出现在第3637次。与目前已知最优解误差0.16%。
爬山算法 | Java版HA_TSP的更多相关文章
- 排序算法Java版,以及各自的复杂度,以及由堆排序产生的top K问题
常用的排序算法包括: 冒泡排序:每次在无序队列里将相邻两个数依次进行比较,将小数调换到前面, 逐次比较,直至将最大的数移到最后.最将剩下的N-1个数继续比较,将次大数移至倒数第二.依此规律,直至比较结 ...
- 排序算法系列:插入排序算法JAVA版(靠谱、清晰、真实、可用、不罗嗦版)
在网上搜索算法的博客,发现一个比较悲剧的现象非常普遍: 原理讲不清,混乱 啰嗦 图和文对不上 不可用,甚至代码还出错 我总结一个清晰不罗嗦版: 原理: 和选择排序类似的是也分成“已排序”部分,和“未排 ...
- 排序算法系列:选择排序算法JAVA版(靠谱、清晰、真实、可用、不罗嗦版)
在网上搜索算法的博客,发现一个比较悲剧的现象非常普遍: 原理讲不清,混乱 啰嗦 图和文对不上 不可用,甚至代码还出错 我总结一个清晰不罗嗦版: 原理: 从数组头元素索引i开始,寻找后面最小的值(比i位 ...
- 排序算法系列:快速排序算法JAVA版(靠谱、清晰、真实、可用、不罗嗦版)
在网上搜索算法的博客,发现一个比较悲剧的现象非常普遍: 原理讲不清,混乱 啰嗦 图和文对不上 不可用,甚至代码还出错 为了不误人子弟耽误时间,推荐看一些靠谱的资源,如[啊哈!算法]系列: https: ...
- 常用排序算法--java版
package com.whw.sortPractice; import java.util.Arrays; public class Sort { /** * 遍历一个数组 * @param sor ...
- Kruskal算法java版
/** * sample Kruskal.java Description: * kruskal算法的思想是找最小边,且每次找到的边不会和以找出来的边形成环路,利用一个一维数组group存放当前顶点所 ...
- 快速排序算法Java版
网上关于快速排序的算法原理和算法实现都比较多,不过java是实现并不多,而且部分实现很难理解,和思路有点不搭调.所以整理了这篇文章.如果有不妥之处还请建议.首先先复习一些基础. 1.算法概念. ...
- A*(也叫A star, A星)寻路算法Java版
寻路算法有非常多种,A*寻路算法被公觉得最好的寻路算法. 首先要理解什么是A*寻路算法,能够參考这三篇文章: http://www.gamedev.net/page/resources/_/techn ...
- 快排算法Java版-每次以最左边的值为基准值手写QuickSort
如题 手写一份快排算法. 注意, 两边双向找值的时候, 先从最右边起找严格小于基准值的值,再从最左边查找严格大于基准base的值; 并且先右后左的顺序不能反!!这个bug改了好久,233~ https ...
随机推荐
- 批量 多个JPG生产PDF .net C#
using iTextSharp.text; using iTextSharp.text.pdf; using System; using System.Collections.Generic; us ...
- .net 中的托管与非托管
托管代码 托管代码就是Visual Basic .NET和C#编译器编译出来的代码.编译器把代码编译成中间语言(IL),而不是能直接在你的电脑上运行的机器码.中间语言被封装在一个叫程序集(assemb ...
- StringMVC返回字符串
@RequestMapping(value="twoB.do") public void twoBCode(HttpServletRequest request,HttpServl ...
- 一个简单的EventEmitter
用JS写了一个简单的EventEmitter: class EventEmitter { /** * 事件名/回调列表 字典 * @type {Map<string, Array<func ...
- 【Java】Maven 常用命令
Maven 常用命令 mvn compile 编译,生成target文件夹,里边有classes文件夹,存放.class文件 mvn test 执行测试 mvn package 打包,在targert ...
- Caused by: java.lang.NoSuchMethodError: org.objectweb.asm.ClassWriter.<init>(I)V
项目中各种缺包现象... Caused by: java.lang.NoSuchMethodError: org.objectweb.asm.ClassWriter.<init>(I)V ...
- 父类和子类以及super关键字
super和this关键字的特点类似:super代表的是父类对象的引用. 当子父类的成员出现同名时,可以通过super来进行区分. 子类的构造方法中,通过super关键字调用父类的构造方法. publ ...
- arcgis api for js 地图查询
arcgis api for js入门开发系列四地图查询(含源代码) 上一篇实现了demo的地图工具栏,本篇新增地图查询功能,包括属性查询和空间查询两大块,截图如下: 属性查询效果图: 空间查询效 ...
- c++ STL stack容器成员函数
这是后进先出的栈,成员函数比较简单,因为只能操作栈顶的元素.不提供清除什么的函数. 函数 描述 bool s.empty() 栈是否为空(即size=0).若空,返回true,否则,false. vo ...
- oracle安装报错[INS-30131]执行安装程序验证所需的初始设置失败(无法访问临时位置)解决方法!
最近在电脑上安装oracle12c,安装时,在执行检查环境步骤时候报错: [INS-30131]执行安装程序验证所需的初始设置失败(无法访问临时位置) 最后在网上搜索解决方法,特记录下,以防以后再用到 ...