MySQL之索引(三)
聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体的细节依赖于其实现方式,但InnoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。当表有聚簇索引时,它的数据行实际上存放在索引的叶子页(leaf page)中。术语“聚簇”表示数据行和相邻的键值紧凑地存储在一起。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
因为是存储引擎负责实现索引,因此不是所有的存储引擎都支持聚簇索引。图1-3展示了聚簇索引中的记录是如何存放的。注意到,叶子页包含了行的全部数据,但是节点页只包含了索引列。在这个案例中,索引列包含的是整数值。
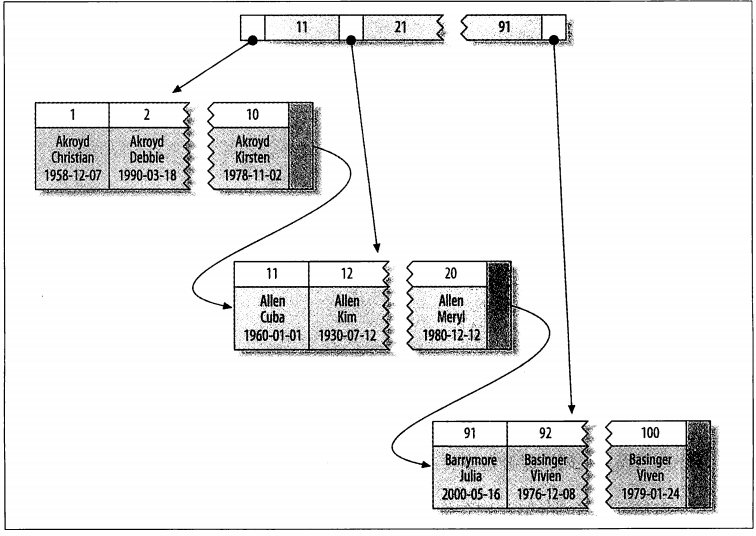
图1-3 聚簇索引的数据分布
一些数据库服务器允许选择哪个索引作为聚簇索引,但MySQL内建的存储引擎尚未支持这一点。InnoDB将通过主键聚集数据,这也就是说图1-3中的“被索引的列”就是主键列。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。InnoDB只聚集在同一个页面中的记录。包含相邻键值的页面可能会相距甚远。
聚集的数据有一些重要的优点:
- 可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘I/O。
- 数据访问更快。聚簇索引将索引和数据保存在同一个B-Tree中,因此从聚簇索引中获取数据通常比非聚簇索引中查找要快。
- 使用覆盖索引扫描的查询可以直接使用页节点的主键值。
聚簇索引也有一些些缺点:
- 聚簇数据最大限度的提高了I/O密集型应用的性能,但如果数据全部都放在内存中,则访问的顺序就没有那么重要了,聚簇索引也就没有那么优势了。
- 插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用OPTIMIZE TABLE命令重新组织一下表。
- 更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置。
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临“页分裂”的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次分裂操作。页分裂会导致表占用更多的磁盘空间。
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。
- 二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列。
- 二级索引访问需要两次索引查找,而不是一次。
最后一点可能让人有些疑惑,为什么二级索引需要两次索引查找?答案在于二级索引中保存的“行指针”的实质。要记住,二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。这意味着通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值去聚簇索引中查找到对应的行。这里做了重复的工作:两次B-Tree查找而不是一次。对于InnoDB,自适应哈希索引能够减少这样的重复工作。
InnoDB和MyISAM的数据分布对比
聚簇索引和非聚簇索引的数据分布有区别,以及对应的主键索引和二级索引的数据分布也有区别。来看看InnoDB和MyISAM是如何存储下面这张表的:
CREATE TABLE layout_test (
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
假设主键的值位于1---10,000之间,且按随机顺序插入,然后用OPTIMIZE TABLE进行优化。换句话说,数据在磁盘上的存储方式已经最优,但行的顺序是随机的。列col2的值是从1~100之间随机赋值,所以会存在许多重复的值。
MyISAM的数据分布非常简单,按照数据插入的顺序存储在磁盘上,如图1-4所示:
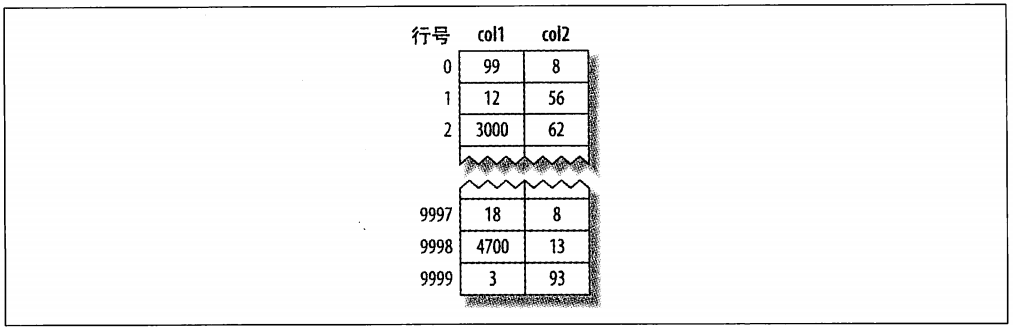
图1-4 MyISAM表layout_test的数据分布
在行的旁边显示了行号,从0开始递增,因为行是定长的,所以MyISAM可以从表的开头跳过所需的字节找到需要的行。这种分布方式很容易创建索引。下面显示的一系列图,隐藏了页的物理细节,只显示索引中的“节点”,索引中的每个叶子节点包含“行号”。图1-5显示了表的主键。
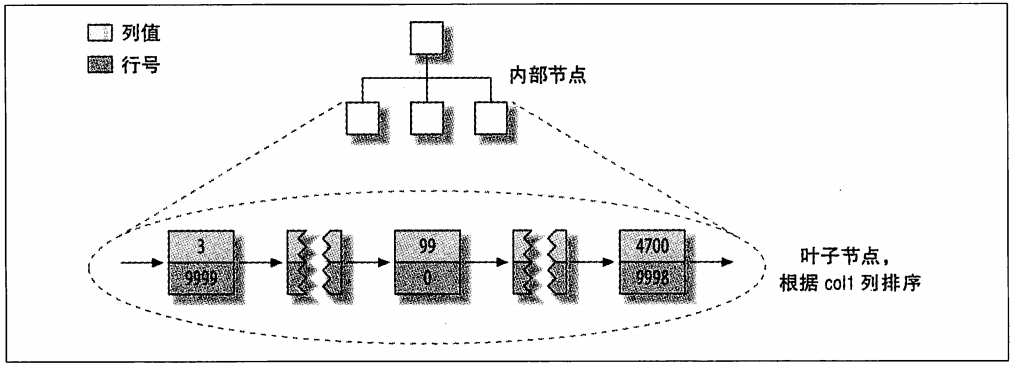
图1-5 MyISAM表layout_test的主键分布
这里忽略了一些细节,例如前一个B-Tree节点有多少个内部节点,不过这并不影响对非聚簇存储引擎的基本数据分布的理解。
那col2列上的索引又会如何呢?有什么特殊的吗?回答是否定的:它和其他索引没有什么区别。图1-6显示了col2列上的索引。
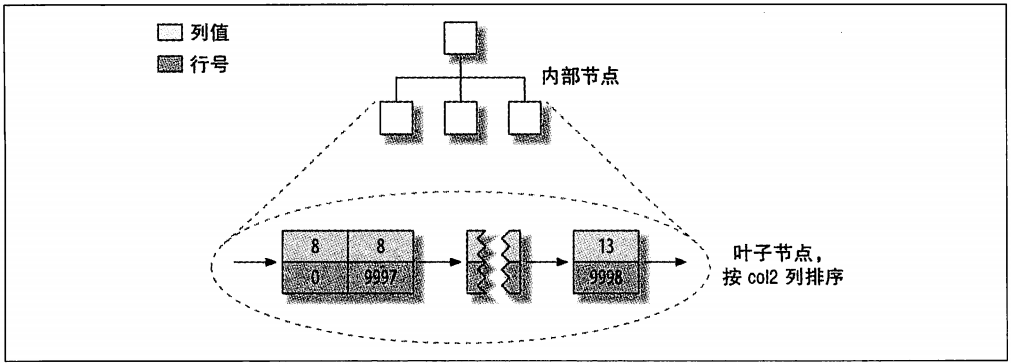
图1-6 MyISAM表layout_test的col2列索引的分布
事实上,MyISAM中主键索引和其他索引在结构上没有什么不同。主键索引就是一个名为PRIMARY的唯一非空索引。
因为InnoDB支持聚簇索引,所以使用非常不同的方式存储同样的数据。InnoDB以如图1-7所示的方式存储数据。
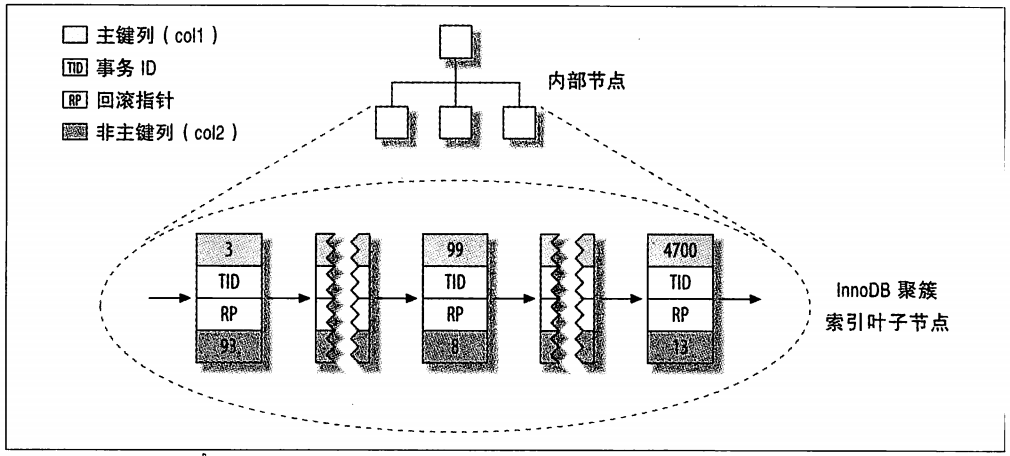
图1-7 InnoDB表layout_test的主键分布
乍看上去,图1-7和图1-5没有什么不同,但仔细观察,还是会注意到该图显示了整个表,而不是只有索引。因为在InnoDB中,聚簇索引“就是”表,所以不像MyISAM那样需要独立的行存储。聚簇索引的每个叶子节点都包含了主键值、事务ID、用于事务和MVCC的回滚指针以及所有的剩余列。如果主键是一个列前缀索引,InnoDB也会包含完整的主键列和剩下的其他列。
还有一点和MyISAM的不同是,InnoDB的二级索引和聚簇索引很不相同。InnoDB二级索引的叶子节点中存储的不是“行指针”,而是主键值,并以此作为指向行的“指针”。这样的策略减少了当出现行移动或者数据页分裂时二级索引的维护工作。使用主键值当作指针会让二级索引占用更多的空间,换来的好处是,InnoDB在移动行时无需更新二级索引中的这个“指针”。
图1-8显示了表的col2索引。每一个叶子节点都包含了索引列(这里是col2),紧接着是主键值(col1)。图1-8展示了B-Tree的叶子节点结构,但我们故意省略了非叶子节点这样的细节。InnoDB的非叶子节点包含了索引列和一个指向下级节点的指针(下一级可以是非叶子节点,也可以是叶子节点)。这对聚簇索引和二级索引都适用。
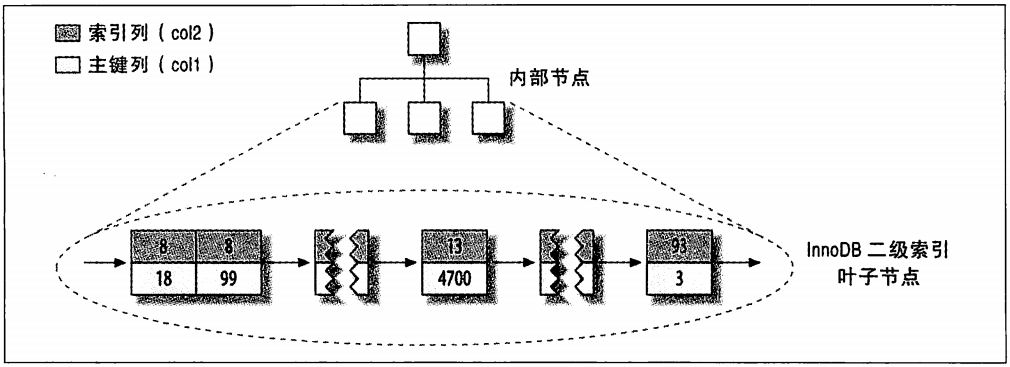
图1-8 InnoDB表layout_test的二级索引分布
图1-9是描述InnoDB和MyISAM如何存放表的抽象图,从图1-9可以看出InnoDB和MyISAM保存数据和索引的区别。
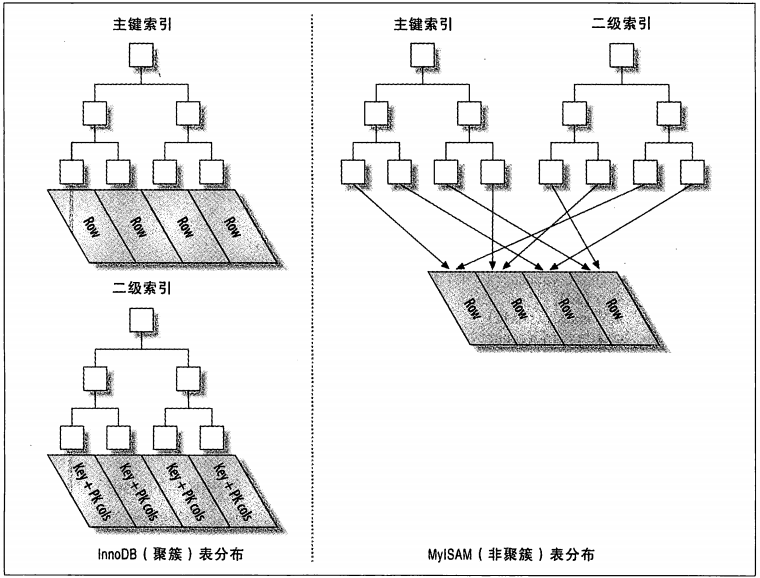
图1-9 聚簇和非聚簇表对比图
覆盖索引
通常大家会根据查询的WHERE条件来创建合适的索引,不过这只是索引优化的一个方面。设计优秀的索引应该考虑到整个查询,而不单单是WHERE条件部分。索引确实是一种查找数据的高效方式,但是MySQL也可以使用索引来直接获取列的数据,这样就不需要读取数据行。如果索引的叶子节点中已经包含要查询的数据,那么还有什么必要回表查询呢?如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
覆盖索引是非常有用的工具,能极大地提高性能。因为它只需扫描索引无需回表,会带来以下好处:
- 索引条目通常远小于数据行大小,所以如果只需要读取索引,那MySQL就会极大地减少数据访问量。这对缓存的负载非常重要,因为这种情况下响应时间大部分花费在数据拷贝上。覆盖索引对于I/O密集型的应用也有帮助,因为索引比数据更小,更容易全部放入内存中(这对于MyISAM尤其正确,因为MyISAM能压缩索引以变得更小)。
- 因为索引是按照列值顺存储的(至少在单个页内是如此),所以对于I/O密集型的范围查询会比随机从磁盘读取每一行数据的I/O要少得多。对于某些存储引擎,例如MyISAM和Percona XtraDB,甚至可以通过OPTIMIZE命令使得索引完全顺序排列,这让简单的范围查询能使用完全顺序的索引访问。
- 一些存储引擎如MyISAM在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用。这可能会导致严重的性能问题,尤其是那些系统调用占了数据访问中的最大开销的场景。
- 由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询。
在所有这些场景中,在索引中满足查询的成本一般比查询行要小得多。
不是所有类型的索引都可以称为覆盖索引。覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引。另外,不同的存储引擎实现覆盖索引的方式也不同,而且不是所有的引擎都支持覆盖索引。
当发起一个被索引覆盖的查询时,在EXPLAIN的Extra列可以看到“Using index”的信息。例如,表sakila.inventory有一个多列索引(store_id,film_id)。MySQL如果只需访问这两列,就可以使用这个索引做覆盖索引,如下所示:
mysql> EXPLAIN SELECT store_id, film_id FROM inventory\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: inventory
partitions: NULL
type: index
possible_keys: NULL
key: idx_store_id_film_id
key_len: 3
ref: NULL
rows: 4581
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
索引覆盖查询还有很多陷阱可能会导致无法实现优化。MySQL查询优化器会在执行查询前判断是否有一个索引能进行覆盖。假设索引覆盖了WHERE条件中的字段,但不是整个查询涉及的字段。如果条件为假,MySQL 5.5和更早的版本也总是会回表获取数据行,尽管并不需要这一行且最终会被过滤掉。
在大多数存储引擎中,覆盖索引只能覆盖那些只访问索引中部分列的查询。不过,可以更进一步优化InnoDB。回想一下,InnoDB的二级索引的叶子节点包含了主键的值,这意味着InnoDB的二级索引可以有效的利用这些“额外”的主键列来覆盖查询。
例如,sakila.actor使用InnoDB存储引擎,并在last_name字段有二级索引,虽然该索引的列不包括主键actor_id,但也能够用于对actor_id做覆盖查询:
mysql> EXPLAIN SELECT actor_id, last_name FROM sakila.actor WHERE last_name = 'HOPPER'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ref
possible_keys: idx_actor_last_name
key: idx_actor_last_name
key_len: 137
ref: const
rows: 2
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
使用索引扫描来做排序
MySQL有两种方式可以生成有序的结果:通过排序操作;或者按索引顺序扫描;如果EXPLAIN出来type列的值为“index”,则说明MySQL使用索引扫描来做排序。
扫描索引本身是很快的,因为只需从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那就不得不每扫描一条索引记录就都回表查询一次对应的行。这基本上都是随机I/O,因此按索引顺序读取的速度通常要比顺序地全表扫描慢,尤其是在I/O密集型的工作负载时。
MySQL可以同时使用同一个索引既满足查找,又满足排序。因此,如果可能,设计索引是应该尽可能
地同时满足这两个任务,这样是最好的。
只有当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方向(倒序或升序)都一样时,MySQL才能使用索引来对结果做排序,如果查询需要关联多张表,则只有当ORDER BY子句引用的字段全部为第一个表时,才能使用索引做排序。ORDER BY子句和查找型查询的限制是一样的:需要满足索引的最左前缀的要求,否则mMySQL都需要执行排序操作,而无法使用索引排序。
有一种情况下ORDER BY子句可以不满足索引的最左前缀的要求,就是前导列为常量的时候。如果WHERE子句或JOIN子句中对这些列指定了常量,就可以“弥补”索引的不足。
例如,Sakila示例数据库的表rental在列(rental_date、inventory_id、customer_id)上有名为rental_date的索引。MySQL可以使用rental_date索引为下面的查询做排序,从EXPLAIN中可以看到没有出现文件排序操作:
mysql> EXPLAIN SELECT rental_id, staff_id FROM rental
-> WHERE rental_date = '2005-05-25'
-> ORDER BY inventory_id, customer_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ref
possible_keys: rental_date
key: rental_date
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
即使ORDER BY子句不满足索引的最左前缀的要求,也可以用于查询排序,这是因为索引的第一列被指定为一个常数。
下面这个查询可以利用索引排序,是因为查询为索引的第一列提供了常量条件,而是用第二列进行排序,将两列组合在一起,就形成了索引的最左前缀:
mysql> EXPLAIN SELECT rental_id, staff_id FROM rental
-> WHERE rental_date = '2005-05-25'
-> ORDER BY inventory_id DESC\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ref
possible_keys: rental_date
key: rental_date
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
下面是一些不能使用索引做排序的查询。
这个查询的ORDER BY子句中引用了一个不在索引中的列:
mysql> EXPLAIN SELECT rental_id, staff_id FROM rental
-> WHERE rental_date > '2005-05-25'
-> ORDER BY inventory_id, customer_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ALL
possible_keys: rental_date
key: NULL
key_len: NULL
ref: NULL
rows: 16005
filtered: 50.00
Extra: Using where; Using filesort
1 row in set, 1 warning (0.00 sec)
这个查询在索引列的第一列上是范围条件,所以MySQL无法使用索引的其余列:
mysql> EXPLAIN SELECT rental_id, staff_id FROM rental
-> WHERE rental_date > '2005-05-25'
-> ORDER BY inventory_id, customer_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: ALL
possible_keys: rental_date
key: NULL
key_len: NULL
ref: NULL
rows: 16005
filtered: 50.00
Extra: Using where; Using filesort
1 row in set, 1 warning (0.00 sec)
这个查询在inventory_id列上有多个等于条件。对于排序来说,这也属于一种范围查询:
mysql> EXPLAIN SELECT rental_id, staff_id FROM rental
-> WHERE rental_date = '2005-05-25' AND inventory_id IN(1,2)
-> ORDER BY customer_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
partitions: NULL
type: range
possible_keys: rental_date,idx_fk_inventory_id
key: rental_date
key_len: 8
ref: NULL
rows: 2
filtered: 100.00
Extra: Using index condition; Using filesort
1 row in set, 1 warning (0.00 sec)
下面这个例子理论上是可以使用索引进行关联排序的,但由于优化器在优化时将film_actor表当作关联的第二张表,所以实际上无法使用索引:
mysql> EXPLAIN SELECT actor_id, title FROM film_actor
-> INNER JOIN film USING(film_id) ORDER BY actor_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: index
possible_keys: PRIMARY
key: idx_title
key_len: 767
ref: NULL
rows: 1000
filtered: 100.00
Extra: Using index; Using temporary; Using filesort
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 5
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.01 sec)
MySQL之索引(三)的更多相关文章
- MySQL 系列(三)你不知道的 视图、触发器、存储过程、函数、事务、索引、语句
第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 你不知道的数据库操作 第三篇:MySQL 系列(三)你不知道的 视图.触发器.存储过程.函数 ...
- MySQL系列(三)---索引
MySQL系列(三)---索引 前言:如果有疏忽或理解不当的地方,请指正. 目录 MySQL系列(一):基础知识大总结 MySQL系列(二):MySQL事务 MySQL系列(三):索引 什么是索引 如 ...
- MySQL数据库(三)索引总结
一.什么是索引? 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存. 如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录 ...
- MySQL性能优化(三):索引
原文:MySQL性能优化(三):索引 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/vbi ...
- MySQL学习笔记(三)—索引
一.概述 1.基本概念 在大型数据库中,一张表中要容纳几万.几十万,甚至几百万的的数据,而当这些表与其他表连接后,所得到的新的数据数目更是要大大超出原来的表.当用户检索这么大量的数据时,经 ...
- MySQL中索引和优化的用法总结
1.什么是数据库中的索引?索引有什么作用? 引入索引的目的是为了加快查询速度.如果数据量很大,大的查询要从硬盘加载数据到内存当中. 2.InnoDB中的索引原理是怎么样的? InnoDB是Mysql的 ...
- 如何正确建立MYSQL数据库索引
索引是快速搜索的关键.MySQL索引的建立对于MySQL的高效运行是很重要的.下面介绍几种常见的MySQL索引类型. 在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytabl ...
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- Mysql中索引的 创建,查看,删除,修改
创建索引 MySQL创建索引的语法如下: ? 1 2 3 CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON ...
随机推荐
- mybatis-plus 异常 Invalid bound statement (not found)
最近吧项目中添加使用了mybatis-plus,发现操作sql的时候出现异常: Invalid bound statement (not found) ,异常位置位于mybatis-plus的jar中 ...
- Java算法面试题 一个顺子带一对
打牌里面经常出现的5张牌,一个顺子带一对,给你五张牌,比如:1,2,2,2,3 或者 5,6,7,4,4 或者 2,4,3,5,5 或者 7,5,9,6,9 ,这种情况就符合一个顺子带一对,则返回 t ...
- 从零开始的全栈工程师——js篇2.2
条件语句 补充: var a=“hello world” a这个变量是字符串了 对于里面每一个字母来说 他是字节 里面有11个字节 字节总数用length表示 如下: 根据上面的内容咱们又发现了一个运 ...
- Vue打包后页面出现cannot get
学习Vue有大半个月了,然而遇到了不少坑,完全没有高手们那么容易,中间有不少值得记录下的东东,回头好好理理.先理下今天的: Vue打包命令简单啊,直接在命令行输入:npm run build 然而没一 ...
- python基础-数据运算
*按位取反运算规则(按位取反再加1) 详解http://blog.csdn.net/wenxinwukui234/article/details/42119265 详细内容ht ...
- Azure School,让你系统化快速学习人工智能
要说目前最热门的技术,非人工智能莫属了,让计算机程序能够看懂.听懂.读懂.理解我们的世界!想想就激动!! 上至高大上的个人数字化助理,下至P图软件,各种应用都开始增加AI相关的功能,试问又有哪个技术爱 ...
- cms-帖子内容实现2
package com.open1111.controller.admin; import java.io.File;import java.util.Date;import java.util.Ha ...
- CRM User Status profile中Business Transaction字段的用途
有朋友问到User Status profile中Business Transaction字段的用途,如下图INPR, FINI所示. 实际上,这个字段作为一个桥梁,连接了User Status和Sy ...
- 为Visual Studio 2012添加MSDN离线帮助
之前有网络的情况下,一直使用的都是在线的,最近又有笔记本上面有时使用时没有网络,所以就想使用下离线的MSDN包.可是找了半天,发现都是需要再次进行下载的.VS2012使用的帮助程序是HelpViewe ...
- hdu-3549 Flow Problem---最大流模板题(dinic算法模板)
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=3549 题目大意: 给有向图,求1-n的最大流 解题思路: 直接套模板,注意有重边 传送门:网络流入门 ...