【PRML读书笔记-Chapter1-Introduction】1.5 Decision Theory
初体验:
概率论为我们提供了一个衡量和控制不确定性的统一的框架,也就是说计算出了一大堆的概率。那么,如何根据这些计算出的概率得到较好的结果,就是决策论要做的事情。
一个例子:
文中举了一个例子:
给定一个X射线图x,目标是如何判断这个病人是否得癌症(C1或C2).我们把它看作是一个二分类问题,根据bayes的概率理论模型,我们可以得到:
因此,
就是
的先验概率;(假设Ck表示患病,那么
则作为是后验概率。
假设,我们的目标是:在给定一个x的情况下,我们希望最小化误分类的概率,因此,我们的直觉会告诉我们,应该选择后验概率较大的那一类作为我们最终的决策类。这就是决策理论。
接下来,我们就来说说为什么这种直觉是正确的。

最小化误分类概率(1.5.1 Minimizing the misclassification rate)
假设我们的目标只是单纯的尽可能减小误分类的概率,对于二分类问题而言,我们需要建立起这么一种规则:将整个输入x划分成两个空间,这两个空间分别对应两个类。新的输入属于哪个区域,就属于哪一类。这两个区域我们把他叫做决策区域(decision regions)(属于同一类别的子区域可以不相连),这两个区域的边界就叫做决策边界(decision boundaries)。
为了找到最优的规则,我们可以表示出误分类的概率表达式:
其中,Rk表示决策类别,Ck表示实际类别。
因此,如果已知
,那么,为了最小化
,我们就应该决策出x属于C1。因为:
假设我们决策x属于C1,那么
=0,即
;
同理,假设我们决策x属于C2,那么
=0,即
。
又因为
,
大家都一样,因此,最小化误分类的概率的问题就转化成了哪一类的
的值更大的问题。如下图所示:
说明:如果把
作为决策边界,那么
X>
,则决策为class2,X<
,则决策为class1。
主要看红色区域,显然,当X0<
,可以发现,p(X,C2)>P(X,C1),但是,由于把
对于多分类的问题,我们计算正确分类的概率p(correct)更为容易。








最小化期望损失
最小化误分类概率是一种相对简单的策略,我们经常会遇到更佳复杂的情况,这时候,我们需要采用一些其他策略去解决。
还是刚才的判断是否患病的例子:如果一个健康的人,你给诊断有患病,那么,他可以通过接受更近一步的检查来确定是否是真的患病;但是,如果是一个病人,你给出的诊断是没病,那么,这样就很有可能由于你的误诊,错过了最佳的治疗的时间,最终导致严重的后果。因此,同样是误诊,但是他们付出的代价是不一样的(后者的代价显然会高于前者)。
因此,为了反映这种情况,损失函数(loss function)的概念被提出来。更进一步地,我们引入了损失矩阵(loss matrix),其中每个元素
表示当某样本真实类别为k,而被决策为j时带来的损失。
患癌症的病人被误诊为健康所付出的代价为1000,而健康的人被误诊患癌症所付出的代价为1.
所以呢,这次我们优化的目标就是最小化损失函数(loss function):
参考:
我们可以把上式改写为:
又因为
其中p(x)大家都一样,因此,最小化损失函数的问题转化为:
最小化







停止决策(阈值)
给定一个输入x时,如果
<θ或

推理与决策
目前为止,我们把分类问题分成了两个阶段:
1、推理阶段(inference stage):利用训练集构建模型
;
2、 决策阶段(decision stage):利用这些后验概率获取最优决策(分类结果)
事实上,在解决决策问题的时候,有3种完全不同的思路:(复杂度由高到低):
1、生成模型(generative models):对输入数据和输出数据进行建模,因此,我们可以根据模型生成一些新的输入数据点;
a、首先对每一类都要计算一个
和
;
b、计算后验概率:
(
);
特点:比较费劲,涉及到x和Ck的联合概率,但是,我们可以从中获取一些额外的信息;比如可以通过归一化得到
,从而了解一个待测样本点是噪声点的可能性有多大(噪声检测)。
2、判别模型(discriminative models.):
a、对
建模;
b、直接指定输入x的类别;
3、判别函数(discriminant function):
就是一个映射函数,输入一个x,输出一个label。
特点:直接,无需计算后验概率
虽然说判别函数比较直接,无需计算后验概率,但是,计算后验概率还是很有必要的:
1、最小化经验风险:如果说损失矩阵经常变动,
生成模型:只需适当的修改一下最小化风险决策指标(minimum risk decision criterion)即可;(
);
判别函数:重新回到训练数据,重新跑一遍;
2、停止决策(阈值):
后验概率可以通过设定阈值来最小化误分类概率
3、对类别先验的补充:
如果在类极度不平衡的情况下,对导致模型的精度下降,影响最终结果。因此,我们想的是尽可能让类之间能够balance。因此,我们可以从人工构造的balance的数据集中获取后验概率,然后再乘以实际的先验。(这句我也不是很明白)(We can therefore simply take the posterior probabilities obtained from our artificially balanced data set and first divide by the class fractions in that data set and then multiply by the class fractions in the population to which we wish to apply the model. )
4、合成模型:
对于复杂的应用,把大问题分解成为独立的小问题进行解决。例子:假设患病和x射线图以及血液信息有关。这样,我们可以对x射线图XI和血液信息XB分别进行建模,他们两两独立:
对于判别模型和生成模型的区别,知乎上有个比较好的例子:
假设你现在有一个分类问题,x是特征,y是类标记。用生成模型学习一个联合概率分布P(x,y),而用判别模型学习一个条件概率分布P(y|x)。
用一个简单的例子来说明这个这个问题。假设x就是两个(1或2),y有两类(0或1),有如下如下样本(1,0)、(1,0)、(1,1)、(2,1)
则学习到的联合概率分布(生成模型)如下:
-------0------1----
--1-- 1/2---- 1/4
--2-- 0 ------1/4
而学习到的条件概率分布(判别模型)如下:
-------0------1----
--1-- 2/3--- 1/3
--2-- 0--- 1
在实际分类问题中,判别模型可以直接用来判断特征的类别情况,而生成模型,需要加上贝耶斯法则,然后应用到分类中。但是,生成模型的概率分布可以还有其他应用,就是说生成模型更一般更普适。不过判别模型更直接,更简单。


回归中的损失函数
前面一直在讲分类问题,现在转到回归问题:
分类和回归不清楚什么意思的可以参照一下说明:{
分类和回归的区别在于输出变量的类型。
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
举个例子:
预测明天的气温是多少度,这是一个回归任务;
预测明天是阴、晴还是雨,就是一个分类任务。
}
决策阶段:选择一个合适的映射,使得y(x)=t

如果把预测的结果和实际的结果的平方差来当作损失函数的话:


我们的目标当然是最小化损失函数,也就是:minimizeE[L],,如果对y(x)求偏导数,即y(x)等于多少时,取得最小值(偏导数为0):

转化为:

如图所示:当x=x0时,它的分布为蓝线

另外,还有一种不一样的方法也可以得到这个结果:式子可以写成这样:


为最小化上面这个损失函数,等式右侧第一项当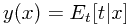 时取得最小值为零,而第二项则表示了期望意义下输入变量x的响应值t的波动情况(方差)。因为它仅与联合概率分布有关与
时取得最小值为零,而第二项则表示了期望意义下输入变量x的响应值t的波动情况(方差)。因为它仅与联合概率分布有关与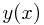 无关,所以它表示了损失函数中无法约减的部分。
无关,所以它表示了损失函数中无法约减的部分。
与分类问题相似,回归问题也可以分为3种不同的方法(复杂度由高到低):
1、联合分布: ,归一化得条件分布,最后得到条件均值
,归一化得条件分布,最后得到条件均值 ;
;
2、直接得到条件密度 ,然后再得到条件均值;
,然后再得到条件均值;
3、直接找到一个y(x)映射,x为训练集;
当然,求平方差只是其中一种损失函数,而且很多时候也并不准确,优雅。所以,我们需要一些其他的误差函数。比如,明科夫斯基误差(Minkowski loss):


可以发现,它是更一般的形式,当q=2的时候就是平方损失。
decision boundaries
【PRML读书笔记-Chapter1-Introduction】1.5 Decision Theory的更多相关文章
- 【PRML读书笔记-Chapter1-Introduction】1.6 Information Theory
熵 给定一个离散变量,我们观察它的每一个取值所包含的信息量的大小,因此,我们用来表示信息量的大小,概率分布为.当p(x)=1时,说明这个事件一定会发生,因此,它带给我的信息为0.(因为一定会发生,毫无 ...
- 【PRML读书笔记-Chapter1-Introduction】1.2 Probability Theory
一个例子: 两个盒子: 一个红色:2个苹果,6个橘子; 一个蓝色:3个苹果,1个橘子; 如下图: 现在假设随机选取1个盒子,从中.取一个水果,观察它是属于哪一种水果之后,我们把它从原来的盒子中替换掉. ...
- PRML读书笔记——机器学习导论
什么是模式识别(Pattern Recognition)? 按照Bishop的定义,模式识别就是用机器学习的算法从数据中挖掘出有用的pattern. 人们很早就开始学习如何从大量的数据中发现隐藏在背后 ...
- PRML读书笔记——线性回归模型(上)
本章开始学习第一个有监督学习模型--线性回归模型."线性"在这里的含义仅限定了模型必须是参数的线性函数.而正如我们接下来要看到的,线性回归模型可以是输入变量\(x\)的非线性函数. ...
- PRML读书笔记——Introduction
1.1. Example: Polynomial Curve Fitting 1. Movitate a number of concepts: (1) linear models: Function ...
- PRML读书笔记——3 Linear Models for Regression
Linear Basis Function Models 线性模型的一个关键属性是它是参数的一个线性函数,形式如下: w是参数,x可以是原始的数据,也可以是关于原始数据的一个函数值,这个函数就叫bas ...
- 《深入PHP与jQuery开发》读书笔记——Chapter1
由于去实习过后,发现真正的后台也要懂前端啊,感觉javascript不懂,但是之前用过jQuery感觉不错,很方便,省去了一些内部函数的实现. 看了这一本<深入PHP与jQuery开发>, ...
- PRML读书笔记——2 Probability Distributions
2.1. Binary Variables 1. Bernoulli distribution, p(x = 1|µ) = µ 2.Binomial distribution + 3.beta dis ...
- PRML读书笔记——Mathematical notation
x, a vector, and all vectors are assumed to be column vectors. M, denote matrices. xT, a row vcetor, ...
随机推荐
- MySQL group_concat 1024 大小
1. GROUP_CONCAT有个最大长度的限制,超过最大长度就会被截断掉,你可以通过下面的语句获得: SELECT @@global.group_concat_max_len; show varia ...
- 从MySQL 5.5到5.7看复制的演进
概要:MySQL 5.5 支持单线程模式复制,MySQL 5.6 支持库级别的并行复制,MySQL 5.7 支持事务级别并行复制.结合这个主线我们可以来分析一下MySQL以及社区发展的一个前因后果. ...
- iOS----友盟分享完善版本
分享 详细集成 注意:1.线上集成文档的示例代码对应的是最新版本的SDK,如果你所用的SDK版本类名或者方法名与此文档不符合,请看随包里面的线下文档或者下载使用最新版本的SDK. 设置友盟appkey ...
- python中x的平方
x ** 2 sqdEvens = [x ** 2 for x in range(8) if not x % 2] for i in sqdEvens: print(i) 0 4 16 36 > ...
- C#程序中注释过多的8条理由
程序中中的注释,一般是有益处的,可以知晓程序的一些逻辑说明,或是参数解释.但是有些程序,因为注释太多,反而引起维护上的不方便,删掉了怕以后不能出现问题不好查找原因,不删除留在代码中,对程序的维护人员, ...
- Lowest Common Ancestor of Two Nodes in a Binary Tree
Reference: http://blog.csdn.net/v_july_v/article/details/18312089 http://leetcode.com/2011/07/lowes ...
- 如何成为一位优秀的创业CEO
英文原文:How to Be Startup CEO 编者按:本文来自 Ryan Allis,是一位来自旧金山的创业者和投资人.在 2003 年创立了 iContact,并任 CEO. 做创业公司的 ...
- spring scope="prototype", scope="session"
转自: http://www.cnblogs.com/JemBai/archive/2010/11/10/1873954.html struts+spring action应配置为scope=&quo ...
- linux内核设计模式
原文来自:http://lwn.net/Articles/336224/ 选择感兴趣内容简单翻译了下: 在内核社区一直以来的兴趣是保证质量.我们需要保证和改善质量是显而易见的.但是如何做到却不是那么简 ...
- android实现qq邮箱多个图标效果
前几天,蛋疼的技术主管非要实现类似装一个qq邮箱,然后能够使用qq邮箱日历的那么一个东西.相当于一个应用生成两个图标,可是不同的是点击不同的图标能够进入不同的应用,例如以下图的效果. 这效果百度了一天 ...