连续值的CART(分类回归树)原理和实现
上一篇我们学习和实现了CART(分类回归树),不过主要是针对离散值的分类实现,下面我们来看下连续值的cart分类树如何实现
思考连续值和离散值的不同之处:
二分子树的时候不同:离散值需要求出最优的两个组合,连续值需要找到一个合适的分割点把特征切分为前后两块
这里不考虑特征的减少问题
切分数据的不同:根据大于和小于等于切分数据集
def splitDataSet(dataSet, axis, value,threshold):
retDataSet = []
if threshold == 'lt':
for featVec in dataSet:
if featVec[axis] <= value:
retDataSet.append(featVec)
else:
for featVec in dataSet:
if featVec[axis] > value:
retDataSet.append(featVec) return retDataSet
选择最好特征的最好特征值
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
bestGiniGain = 1.0; bestFeature = -1;bsetValue=""
for i in range(numFeatures): #遍历特征
featList = [example[i] for example in dataSet]#得到特征列
uniqueVals = list(set(featList)) #从特征列获取该特征的特征值的set集合
uniqueVals.sort()
for value in uniqueVals:# 遍历所有的特征值
GiniGain = 0.0
# 左增益
left_subDataSet = splitDataSet(dataSet, i, value,'lt')
left_prob = len(left_subDataSet)/float(len(dataSet))
GiniGain += left_prob * calGini(left_subDataSet)
# print left_prob,calGini(left_subDataSet),
# 右增益
right_subDataSet = splitDataSet(dataSet, i, value,'gt')
right_prob = len(right_subDataSet)/float(len(dataSet))
GiniGain += right_prob * calGini(right_subDataSet)
# print right_prob,calGini(right_subDataSet),
# print GiniGain
if (GiniGain < bestGiniGain): #比较是否是最好的结果
bestGiniGain = GiniGain #记录最好的结果和最好的特征
bestFeature = i
bsetValue=value
return bestFeature,bsetValue
生成cart:总体上和离散值的差不多,主要差别在于分支的值要加上大于或者小于等于号
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
# print dataSet
if classList.count(classList[0]) == len(classList):
return classList[0]#所有的类别都一样,就不用再划分了
if len(dataSet) == 1: #如果没有继续可以划分的特征,就多数表决决定分支的类别
return majorityCnt(classList)
bestFeat,bsetValue = chooseBestFeatureToSplit(dataSet)
# print bestFeat,bsetValue,labels
bestFeatLabel = labels[bestFeat]
if bestFeat==-1:
return majorityCnt(classList)
myTree = {bestFeatLabel:{}}
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = list(set(featValues))
subLabels = labels[:]
# print bsetValue
myTree[bestFeatLabel][bestFeatLabel+'<='+str(round(float(bsetValue),3))] = createTree(splitDataSet(dataSet, bestFeat, bsetValue,'lt'),subLabels)
myTree[bestFeatLabel][bestFeatLabel+'>'+str(round(float(bsetValue),3))] = createTree(splitDataSet(dataSet, bestFeat, bsetValue,'gt'),subLabels)
return myTree
我们看下连续值的cart大概是什么样的(数据集是我们之前用的100个点的数据集)
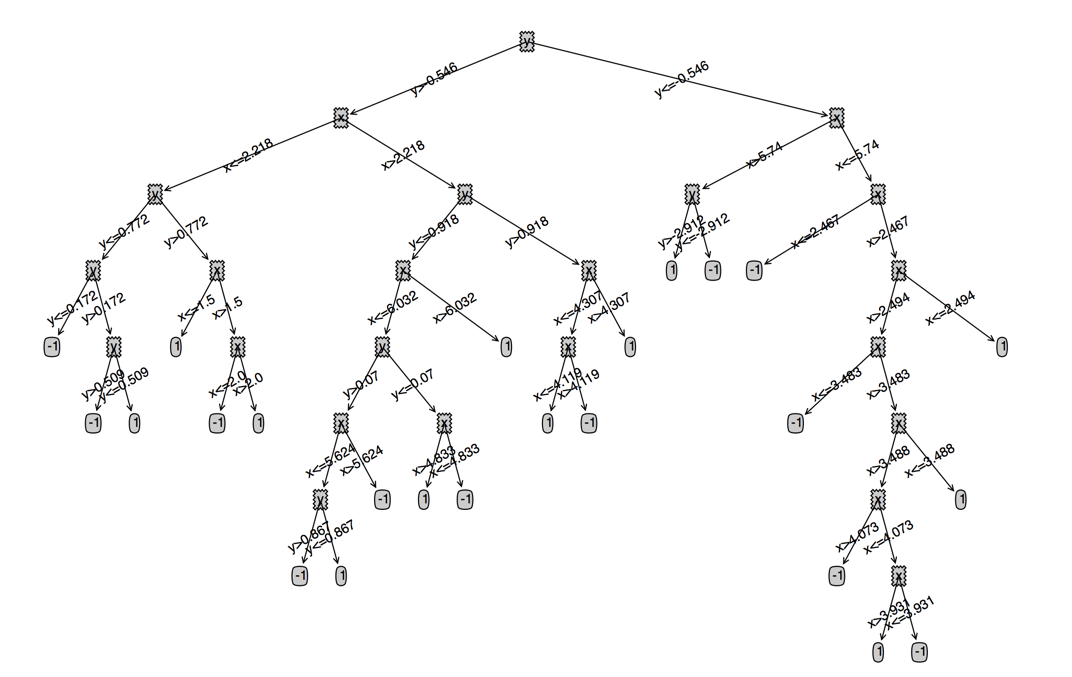
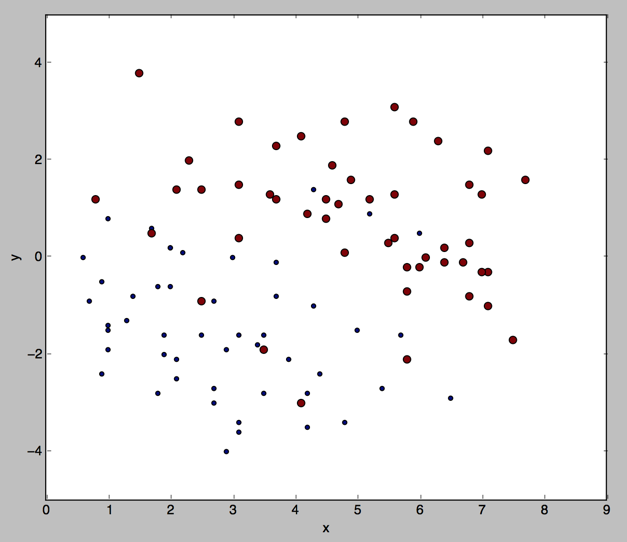
连续值的CART(分类回归树)原理和实现的更多相关文章
- 机器学习技法-决策树和CART分类回归树构建算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 重要!重要!重要~ 一.决策树(Decision Tree).口袋(Bagging),自适应增 ...
- 决策树的剪枝,分类回归树CART
决策树的剪枝 决策树为什么要剪枝?原因就是避免决策树“过拟合”样本.前面的算法生成的决策树非常的详细而庞大,每个属性都被详细地加以考虑,决策树的树叶节点所覆盖的训练样本都是“纯”的.因此用这个决策树来 ...
- 机器学习之分类回归树(python实现CART)
之前有文章介绍过决策树(ID3).简单回顾一下:ID3每次选取最佳特征来分割数据,这个最佳特征的判断原则是通过信息增益来实现的.按照某种特征切分数据后,该特征在以后切分数据集时就不再使用,因此存在切分 ...
- 利用CART算法建立分类回归树
常见的一种决策树算法是ID3,ID3的做法是每次选择当前最佳的特征来分割数据,并按照该特征所有可能取值来切分,也就是说,如果一个特征有四种取值,那么数据将被切分成4份,一旦按某特征切分后,该特征在之后 ...
- CART决策树(分类回归树)分析及应用建模
一.CART决策树模型概述(Classification And Regression Trees) 决策树是使用类似于一棵树的结构来表示类的划分,树的构建可以看成是变量(属性)选择的过程,内部节 ...
- 分类回归树(CART)
概要 本部分介绍 CART,是一种非常重要的机器学习算法. 基本原理 CART 全称为 Classification And Regression Trees,即分类回归树.顾名思义,该算法既 ...
- 秒懂机器学习---分类回归树CART
秒懂机器学习---分类回归树CART 一.总结 一句话总结: 用决策树来模拟分类和预测,那些人还真是聪明:其实也还好吧,都精通的话想一想,混一混就好了 用决策树模拟分类和预测的过程:就是对集合进行归类 ...
- 分类-回归树模型(CART)在R语言中的实现
分类-回归树模型(CART)在R语言中的实现 CART模型 ,即Classification And Regression Trees.它和一般回归分析类似,是用来对变量进行解释和预测的工具,也是数据 ...
- CART(分类回归树)
1.简单介绍 线性回归方法可以有效的拟合所有样本点(局部加权线性回归除外).当数据拥有众多特征并且特征之间关系十分复杂时,构建全局模型的想法一个是困难一个是笨拙.此外,实际中很多问题为非线性的,例如常 ...
随机推荐
- [leetcode] Min Stack @ Python
原题地址:https://oj.leetcode.com/problems/min-stack/ 解题思路:开辟两个栈,一个栈是普通的栈,一个栈用来维护最小值的队列. 代码: class MinSta ...
- BarEditItem ContentTemplate
<dxb:BarEditItem Name="txtSearch" > <dxb:BarEditItem.ContentTemplate> <Data ...
- JAVA自动化测试数据设计
数据管理是很重要的,数据管理与方法一样,依然是有层次的,我们在测试的过程中,可能会有多个环境,每个环境的URL啊,登录名啊,数据库连接地址啊等等不一样,我们可以把这些环境每个都配置一个数据文件,里面写 ...
- 对于程序开发者看书(指实在的书而不是PDF)的好处。(个人看法而已)
书是实在的东西.不同PDF.他能带你进入一种学习态度的环境 书上已经所列了知识点.看了.那些知识点就是你的. 第一次看,未必完全理解到里面的东西.说不定过几天,几周,几个月,甚至几年.再看.就有可能看 ...
- XE6 FMX之控件绘制与显示
中午,有个货随手买的2块钱的彩票,尼玛中了540块,这是啥子狗屎气运.稍微吐槽一下,现在开始正规的笔记录入.经常有朋友说为毛我的博客不更新了或者说更新的少了,为啥呢!一来自己懒了,没学习什么新的东西, ...
- No module named flask.ext.sqlalchemy.SQLALchemy
在学习<OReilly.Flask.Web.Development>的时候,按照书的例子到了数据库那一章,在运行python hello.py shell的时候出现了“ImportErro ...
- A/B测试
昨天把前段时间开发的二胡调音器的应用发布到了亚马逊应用程序商店,看到了一个A/B测试的标签,了解一下A/B测试的工作原理. A/B测试是一种新兴的网页优化方法,可以用于增加转化率注册率等网页指标. 使 ...
- Homebrew
Homebrew官网:http://brew.sh Homebrew installs the stuff you need that Apple didn't Homebrew的安装非常简单,打开终 ...
- 【Cocos2d-Js基础教学(5)资源打包工具的使用及资源的异步加载处理】
TexturePacker是纹理资源打包工具,支持Cocos2dx的游戏资源打包. 如果用过的同学可以直接看下面的资源的异步加载处理 首先为什么用TexturePacker? 1,节省图片资源实际大小 ...
- iOS CoreData 增删改查详解
最近在学习CoreData, 因为项目开发中需要,特意学习和整理了一下,整理出来方便以后使用和同行借鉴.目前开发使用的Swift语言开发的项目.所以整理出来的是Swift版本,OC我就放弃了. 虽然S ...