论文笔记:Attention Is All You Need
Attention Is All You Need
2018-04-17 10:35:25
Paper:http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
Code(PyTorch Version):https://github.com/jadore801120/attention-is-all-you-need-pytorch
Video Tutorial: https://www.youtube.com/watch?v=S0KakHcj_rs
另一个不错的关于这个文章的 Blog:https://kexue.fm/archives/4765
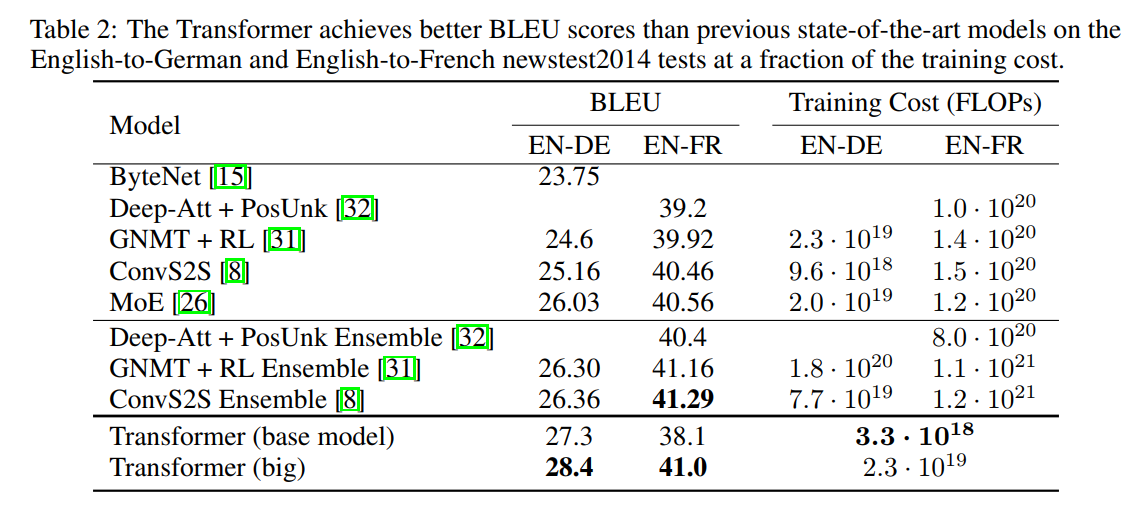
1. Introduction:
现有的做 domain translation 的方法大部分都是基于 encoder-decoder framework,取得顶尖性能的框架也都是 RNN + Attention Mechanism 的思路。而本文别出心裁,仅仅依赖于 attention 机制,就可以做到很好的性能,并且,这种方法并适用于并行(parallelization)。
2. Model Architecture:
大部分神经序列转换模型(neural sequence transduction models)都有 encoder-decoder structure。此处,encoder 将输入的序列(x1, x2, ... , xn)转换为连续的表示 z = (z1, z2, ..., zn)。给定 z,decoder 然后每一输出一个元素,构成了序列 (y1, y2, ... , ym)。在每一个时间步骤,该模型是 auto-regressive,当产生下一个输出时,会使用上一个时刻产生的符号作为额外的输入(consuming the previously generated symbols as additional input when generating the next)。
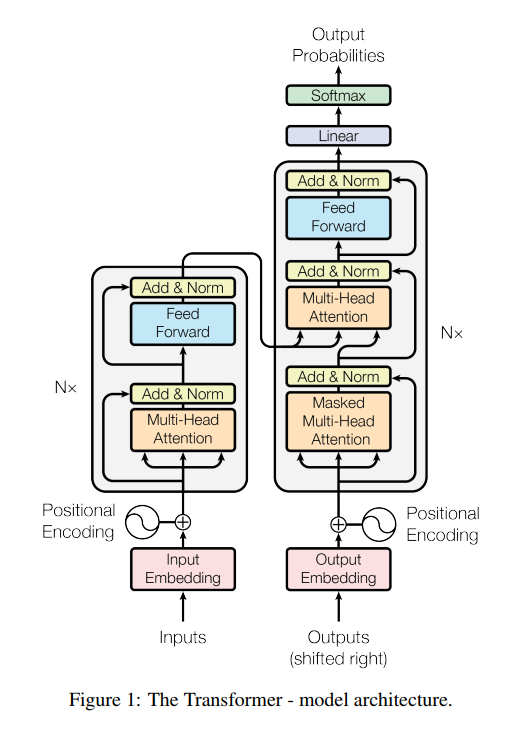
2.1 Encoder and Decoder Stacks :
Encoder:encoder 是由 6 个相同的 layer 堆叠起来的。每一个 layer 包括 两个 sub-layers:
第一个是:mutli-head self-attention mechanism ;
第二个是:position-wise fully connected feed-forward network.
每一个这样的 two sub-layers 附近都会用上 residual connection,然后加上 layer normalization。
Decoder:decoder 也有 6 层,不同的是:decoder layer 中包含 3个 sub-layers, which performs multi-head attention over the output of the encoder stack. 类似于 the encoder,我们采用 residual connections,followed by layer normalization. 我们也修改了 the self-attention sub-layer in the decoder。这个 masking,结合了这么一个事实:the output embeddings are offset by one position, 确保对于位置 i 的预测可以仅仅依赖于 the known outputs at positions less than i (less than i 是什么意思???). This maksing, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
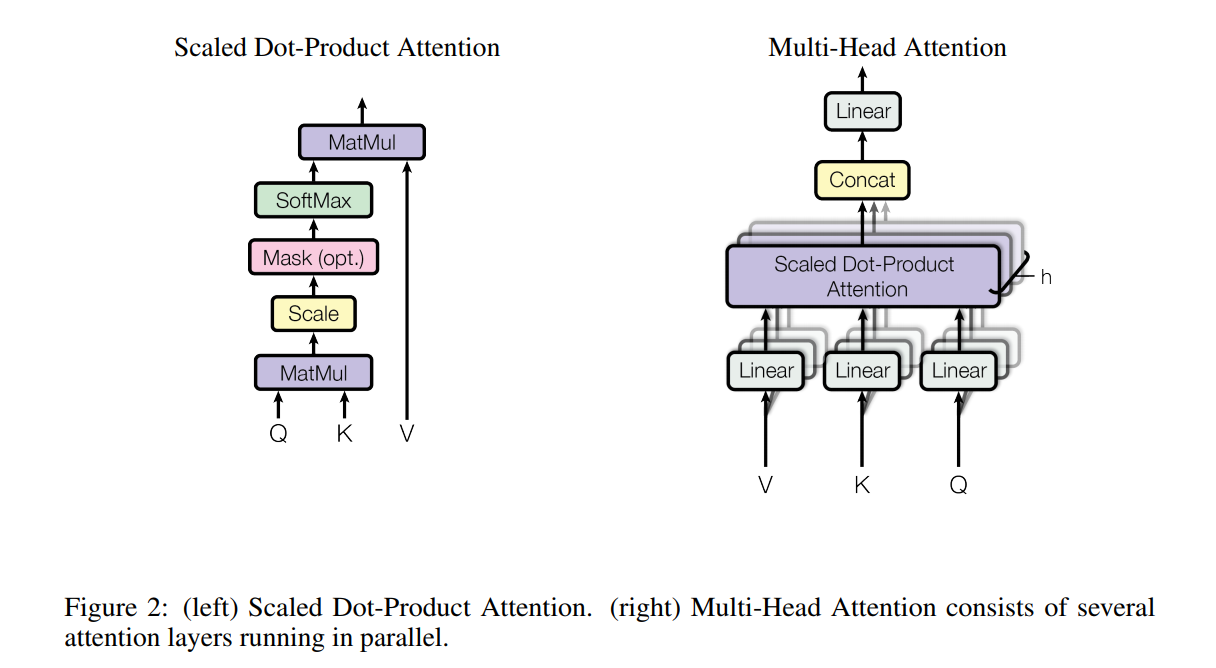
2.2 Attention :
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. 输出可以看做是 the values 的加权组合,给每一个 value 的加权可以计算为:a compatibility function of the query with the corresponding key.
2.2.1 Scaled Dot-Product Attention
我们称我们特定的 attention 为:“Scaled Dot-Product Attention”。输入包括:queries and keys of dimension $d_k$, and values of dimension $d_v$。我们计算 the dot products of the query with all keys, divide each by 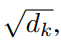 and apply a softmax function to obtain the weights on the values.
and apply a softmax function to obtain the weights on the values.
实际上,我们同时在一个 queries 的集合上计算 attention function,将其打包为 a matrix Q。The keys and values 也被打包为:K and V. 我们计算输出的矩阵为:
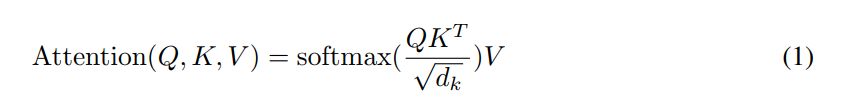
两个最常用的 attention functions 是:additive attention,and dot-product (multiplicative) attention.
2.2.2 Multi-Head Attention
用 $d_{model}-dimensional$ keys, values and queries,我们发现:it is beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively. 在每一个这些投影的版本,我们然后并行的执行 attention function,产生 dv-dimensional 的输出 values。这些东西组合起来,然后再次投影,得到最终的 values,如图2所示。
Multi-head attention allows the model to jointly attend to information from different reprentation subspaces at different positions. With a single attention head, averaging inhibits this.

本文才用 h=8 并行的 attention layers,or heads.
2.2.3 Applications of Attention in our Model :

2.3 Position-wise Feed-Forward Networks
除了 attention sub-layers, 我们 encoder and decoder 的每一层都包含一个全连接的 feed-forward network, 单独且平等的适用于每一个位置。这包含:two linear transformations with a ReLU activation in between:

2.4 Embeddings and Softmax
和其他序列转换模型一样,我们利用学习到的 embeddings 来转换输入的符号,然后输出符号为维度是 $d_{model}$ 的向量。
2.5 Positional Encoding
由于我们的模型没有任何 recurrence 和 convolution,为了使得模型充分利用 sequence 的序列信息,我们必须注入相对或者绝对位置的信息。因此,我们将 “Positional encoding” to the input embeddings at the bottoms of the encoder and decoder stacks. 位置编码和 embeddings 有相同的维度,所以这两个东西可以相加起来。
本文我们采用 sine and cosine functions of different frequencies:

其中,pos 是 位置,i 是维度。

论文笔记:Attention Is All You Need的更多相关文章
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记:语音情感识别(四)语音特征之声谱图,log梅尔谱,MFCC,deltas
一:原始信号 从音频文件中读取出来的原始语音信号通常称为raw waveform,是一个一维数组,长度是由音频长度和采样率决定,比如采样率Fs为16KHz,表示一秒钟内采样16000个点,这个时候如果 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
随机推荐
- 【Linux学习三】VI/VIM全屏文本编辑器
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 一.打开关闭文件打开文件:vim /path/to/somefilev ...
- QT 通过QNetworkReply *获取对应请求的URL地址
[1]QT 通过QNetworkReply *获取对应请求的URL地址 reply->url().toString(); Good Good Study, Day Day Up. 顺序 选择 循 ...
- Linux服务器下jdk 安装与环境变量的配置
1,Oracle 官网下载jdk Linux版本 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-213 ...
- MySQL超时配置
connect_timeout:连接响应超时时间.服务器端在这个时间内如未连接成功,则会返回连接失败. wait_timeout:连接空闲超时时间.与服务器端无交互状态的连接,直到被服务器端强制关闭而 ...
- ResourceBundle与Properties读取配置文件
ResourceBundle与Properties的区别在于ResourceBundle通常是用于国际化的属性配置文件读取,Properties则是一般的属性配置文件读取. ResourceBundl ...
- linux常用命令:more 命令
more命令,功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上. more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会 ...
- HDU 1846 Brave Game (巴什博弈)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1846 十年前读大学的时候,中国每年都要从国外引进一些电影大片,其中有一部电影就叫<勇敢者的游戏& ...
- vue打包报内存溢出
vue-cli 构建的项目:package.json 文件里修改: "build": "node build/build.js" 修改为: "buil ...
- 不懂RPC实现原理怎能实现架构梦
RPC(Remote Procedure Call Protocol)——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些传输协议的存在 ...
- Linux的简单介绍.
Linux操作系统概述: Linux是基于Unix的开源免费的操作系统,由于系统的稳定性和安全性几乎成为程序代码运行的最佳系统环境.Linux是由Linux Torvalds(林纳斯·托瓦兹)起初开发 ...