【Python】批量查询-提取站长之家IP批量查询的结果v1.0
0 前言
写报告的时候为了细致性,要把IP地址对应的地区给整理出来。500多条IP地址找出对应地区复制粘贴到报告里整了一个上午。
为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本。
1 使用库
- 1)requests
- 简介:Requests是一常用的http请求库,它使用python语言编写,可以方便地发送http请求,以及方便地处理响应结果。
- 安装方法:pip install requests
- 2)BeautifulSoup
- 简介:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档
- 安装方法:pip install beautifulsoup4
2 代码
#-*-coding:utf-8-*-
# chinaz-extractIPandCountry.py
# 主要功能:批量查询-提取站长之家IP批量查询的结果
# By zzzhhh (http://www.cnblogs.com/17bdw)
import sys
import os
import requests
from bs4 import BeautifulSoup
ip_list = []
#匹配出IP地址函数
def matchIP (str):
url = "http://ip.chinaz.com/"
url = url+str
## 根据传入的IP地址截取出地区
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata, 'lxml')
for tag in soup.find_all('span', class_='Whwtdhalf w50-0'):
tag_extractl = tag.get_text().encode('utf-8')
if tag_extractl.find("IP的物理位置"): #过滤掉【IP的物理位置】这个字符
print str, tag.get_text()
#读取文件函数
def read_file(file_path):
if not os.path.exists(file_path):
print 'Please confirm correct filepath !'
sys.exit(0)
else:
with open(file_path, 'r') as source:
for line in source:
ip_list.append(line.rstrip('\r\n').rstrip('\n'))
for ip in ip_list:
matchIP(ip)
if __name__ == '__main__':
file_str=raw_input('Input file IP.txt filepath eg:D:\\\\test.txt \n')
read_file(file_str) #读取文件
3 效果
输入存有IP的.txt文件路径
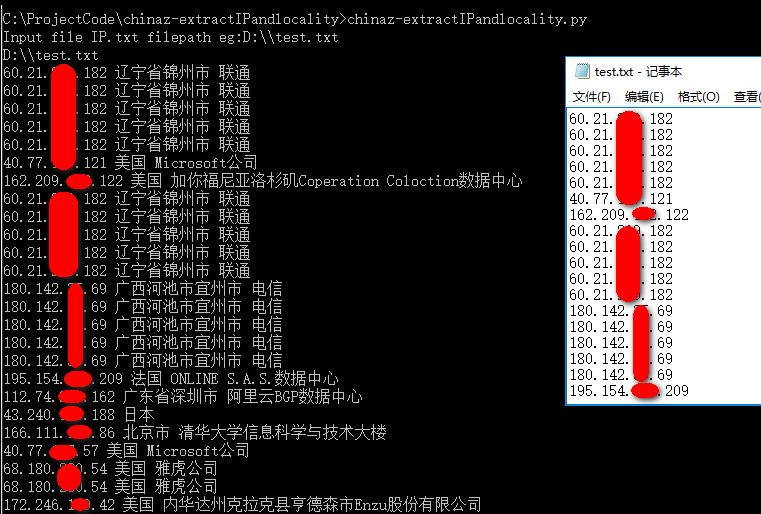
复制到Notepad++,然后粘贴到Word中。爽爽爽。。。
【Python】批量查询-提取站长之家IP批量查询的结果v1.0的更多相关文章
- 【Python】批量查询-提取站长之家IP批量查询的结果加强版本v3.0
1.工具说明 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 某 ...
- 提取站长之家IP批量查询
1.工具说明 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 使 ...
- 【python数据挖掘】批量爬取站长之家的图片
概述: 站长之家的图片爬取 使用BeautifulSoup解析html 通过浏览器的形式来爬取,爬取成功后以二进制保存,保存的时候根据每一页按页存放每一页的图片 第一页:http://sc.china ...
- Python 超简单 提取音乐高潮(附批量提取)
很多时候我们想提取某首歌的副歌部分(俗称 高潮部分),只能手动直接卡点剪切,但是对于大批量的获取就很头疼,如何解决? 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后 ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
- [1]IP地址查询
今天起开始玩百度APIStore里面的免费API.以前用过的有12306的:数据.接口,有时间整理出来,12306的有点乱就是了.还有扇贝以及有道的API,之前用在留言板里自动翻译,公司用过百度地图以 ...
- 利用Python制作简单的小程序:IP查看器
前言 说实话,查看电脑的IP,也挺无聊的,但是够简单,所以就从这里开始吧.IP地址在操作系统里就可以直接查看.但是除了IP地址,我们也想通过IP获取地理地址和网络运营商情况.IP地址和地理地址并没有固 ...
- python扫描proxy并获取可用代理ip列表
mac或linux下可以work的代码如下: # coding=utf-8 import requests import re from bs4 import BeautifulSoup as bs ...
- 【学习】Python进行数据提取的方法总结【转载】
链接:http://www.jb51.net/article/90946.htm 数据提取是分析师日常工作中经常遇到的需求.如某个用户的贷款金额,某个月或季度的利息总收入,某个特定时间段的贷款金额和笔 ...
随机推荐
- MT【40】一道联赛二试题
让我通过这道题来演示如何利用切比雪夫多项式的内功心法: 评:如此大道至简,当年为之叫绝的精彩的做法
- emwin 解决在A窗口上新建B窗口后‘只激活’B窗口问题
@2018-08-08 问题来源: 要实现A窗口上的参数修改,通过A窗口上新建的B窗口小键盘实现数据录入,但结果是只要点击A窗口上的任何地方(包括B窗口上的任意位置),则B窗口就消失了 解决办法: 使 ...
- 【AGC005F】简单的问题 Many Easy Problems
Description 链接 Solution 对于每个\(k\),统计任选\(k\)个点作为关键点的"最小生成树"的大小之和 正向想法是枚举或者计算大小为\(x\).叶子数目为\ ...
- luogu3195/bzoj1010 玩具装箱(斜率优化dp)
推出来式子然后斜率优化水过去就完事了 #include<cstdio> #include<cstring> #include<algorithm> #include ...
- POJ3287(BFS水题)
Description Farmer John has been informed of the location of a fugitive cow and wants to catch her i ...
- 【Linux】fg、bg让你的进程在前后台之间切换
Linux下的fg和bg命令是进程的前后台调度命令,即将指定号码(非进程号)的命令进程放到前台或后台运行.比如一个需要长时间运行的命令,我们就希望把它放入后台,这样就不会阻塞当前的操作:而一些服务型的 ...
- 【洛谷P1273】有线电视网
题目大意:给定一棵 N 个节点的有根树,1 号节点为根节点,叶子节点有点权,每条边有边权,每经过一条边都减去该边权,每经过一个节点都加上该点权,求在保证权值和为非负数的前提下最多能经过多少个叶子节点. ...
- (转)git中关于fetch的使用
将远程仓库的分支及分支最新版本代码拉取到本地: 命令:git fetch 该命令执行后,不会将拉取的分支的最新代码合并到当前分支,仅仅是拉取/下载下来到本地仓库中. 首先,我们使用git branch ...
- 跟我一起使用electron搭建一个文件浏览器应用吧(三)
第二篇博客中我们可以看到我们构建的桌面应用会显示我们的文件及文件夹. In the second blog, we can see that the desktop application we bu ...
- 目前最全的IT技术问答、社区、科技服务网站合集
资源网站 推荐一个资源丰富齐全的网站:风云社区(SCOEE),主要特点是提供的是纯净.优质.无广告.无附加东西的资源.资源很丰富,包括各类软件资源(mac.Windows.ios.ipad.安装等软件 ...