Scrapy项目结构分析和工作流程
新建的空Scrapy项目:

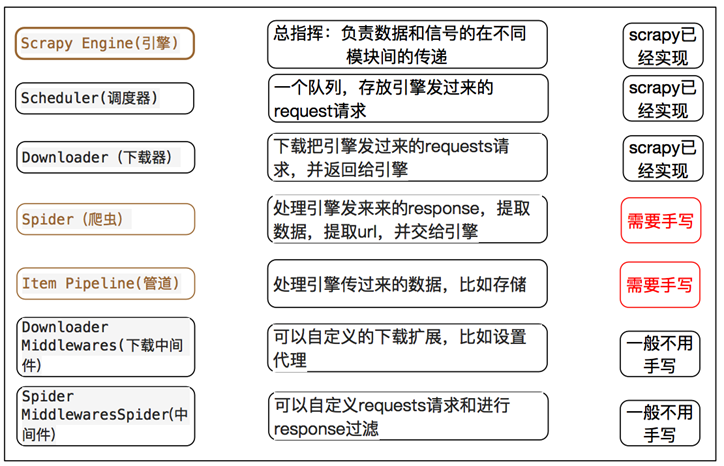
spiders目录: 负责存放继承自scrapy的爬虫类。里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或一些网站。
__init__.py: 项目的初始化文件。
items.py: 负责数据模型的建立,类似于实体类。定义我们所要爬取的信息的相关属性。Item对象是种容器,用来保存获取到的数据。
middlewares.py: 自己定义的中间件。可以定义相关的方法,用以处理蜘蛛的响应输入和请求输出。
pipelines.py: 负责对spider返回数据的处理。在item被Spider收集之后,就会将数据放入到item pipelines中,在这个组件是一个独立的类,他们接收到item并通过它执行一些行为,同时也会决定item是否能留在pipeline,或者被丢弃。
settings.py: 负责对整个爬虫的配置。提供了scrapy组件的方法,通过在此文件中的设置可以控制包括核心、插件、pipeline以及Spider组件。 scrapy.cfg: scrapy基础配置
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
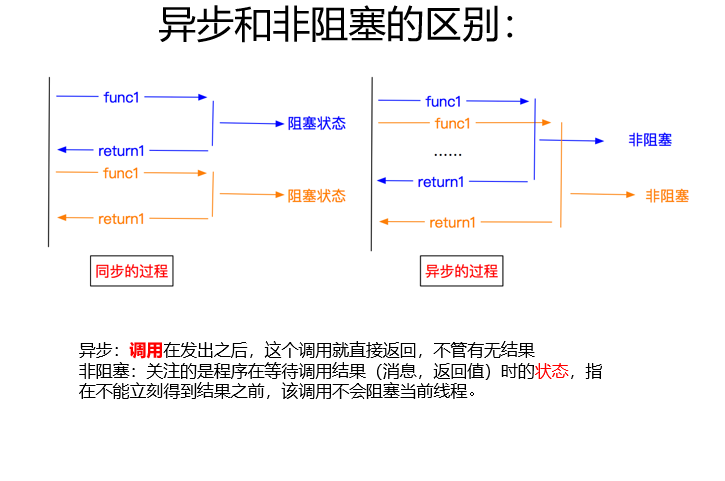
普通爬虫流程:

Scrapy工作流程
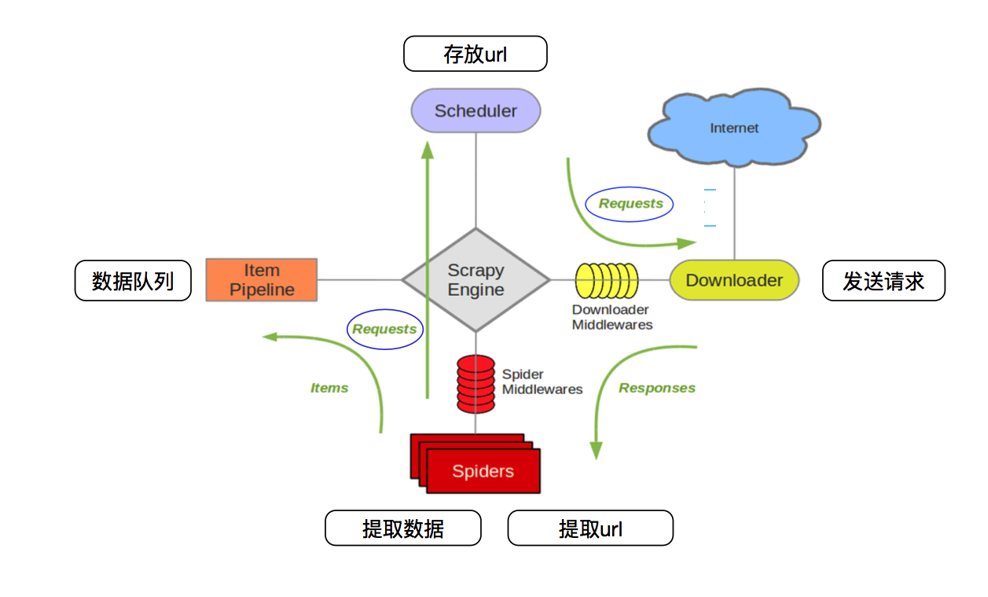
scrapy框架的工作流程:
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
scrapy爬虫框架之理解篇(个人理解)
Scrapy项目结构分析和工作流程的更多相关文章
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- YARN结构分析与工作流程
YARN Architecture Link: http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html ...
- CocosCreator资源工作流程
--摘自官方文档 资源工作流程 添加资源 资源管理器 提供了三种在项目中添加资源的方式: 通过 创建按钮 添加资源 在操作系统的文件管理器中,将资源文件复制到项目资源文件夹下,之后再打开或激活 Coc ...
- 【Git项目管理】分布式 Git - 分布式工作流程
分布式 Git - 分布式工作流程 你现在拥有了一个远程 Git 版本库,能为所有开发者共享代码提供服务,在一个本地工作流程下,你也已经熟悉了基本 Git 命令.你现在可以学习如何利用 Git 提供的 ...
- pip:带你认识一个 Python 开发工作流程中的重要工具
摘要:许多Python项目使用pip包管理器来管理它们的依赖项.它包含在Python安装程序中,是Python中依赖项管理的重要工具. 本文分享自华为云社区<使用Python的pip管理项目的依 ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- 爬虫之scrapy工作流程
Scrapy是什么? scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容.Scrapy 使用了 Twisted['twɪstɪd] ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- J2EE进阶(六)SSH框架工作流程项目整合实例讲解
J2EE进阶(六)SSH框架工作流程项目整合实例讲解 请求流程 经过实际项目的进行,结合三大框架各自的运行机理可分析得出SSH整合框架的大致工作流程. 首先查看一下客户端的请求信息: 对于一个Web项 ...
随机推荐
- 并行动画组QParallelAnimationGroup
QParallelAnimationGroup会同时执行添加到该组的所有动画 import sys from PyQt5.QtGui import QPixmap from PyQt5.QtCore ...
- <转载>iTerm2使用技巧
原文链接:http://www.cnblogs.com/756623607-zhang/p/7071281.html 1.设置窗口 定位到 [Preferences - Profiles - Wi ...
- nginx入门一
配置文件: server_name user root; worker_processes 2; error_log logs/error-test.log; #pid logs/nginx.pid; ...
- ROS Kinetic Install on Debian 9
Not Succesed! 1. 配置源$ sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release - ...
- Linux电源管理【转】
转自:http://www.cnblogs.com/sky-zhang/archive/2012/06/05/2536807.html PM notifier机制: 应用场景: There are s ...
- 在Ubuntu中通过update-alternatives切换软件版本
update-alternatives是ubuntu系统中专门维护系统命令链接符的工具,通过它可以很方便的设置系统默认使用哪个命令.哪个软件版本,比如,我们在系统中同时安装了open jdk和sun ...
- centos6.5环境使用RPM包离线安装MariaDB 10.0.20
1. 进入MariaDB官网下载MariaDB需要的RPM包 2. 使用下载软件下载所需要的RPM包, 总共4个, 并上传到CentOS主机指定目录. MariaDB-10.0.20-centos6- ...
- PL/SQL第三章 基础查询语句
--查询所有列 select * from tab_name|view_name; SELECT * FROM emp; SELECT * FROM (SELECT * FROM emp); --查询 ...
- Linux常用命令4(grep、df、du、awk、su、ll)
[grep命令] grep常用用法 [root@www ~]# grep [-acinv] [--color=auto] '搜寻字符串' filename选项与参数:-a :将 binary 文件以 ...
- go语言标准库 时刻更新
Packages Standard library Other packages Sub-repositories Community Standard library ▾ Name Synops ...