008 Spark中standalone模式的HA(了解,知道怎么配置即可)
standalone也存在单节点问题,这里主要是配置两个master。
1.官网

2.具体的配置

3.配置方式一(不是太理想)
这种知识基于未来可以重启,但是不能在宕机的时候提供服务。
方式一:Single-Node Recovery with Local File System
类似于Hadoop1中的SecondaryNameNode
当出现单点故障的时候,需要手动启动master,然后master会读刚刚断掉之前的日志,类似于secondarynamenode方式。
做法:
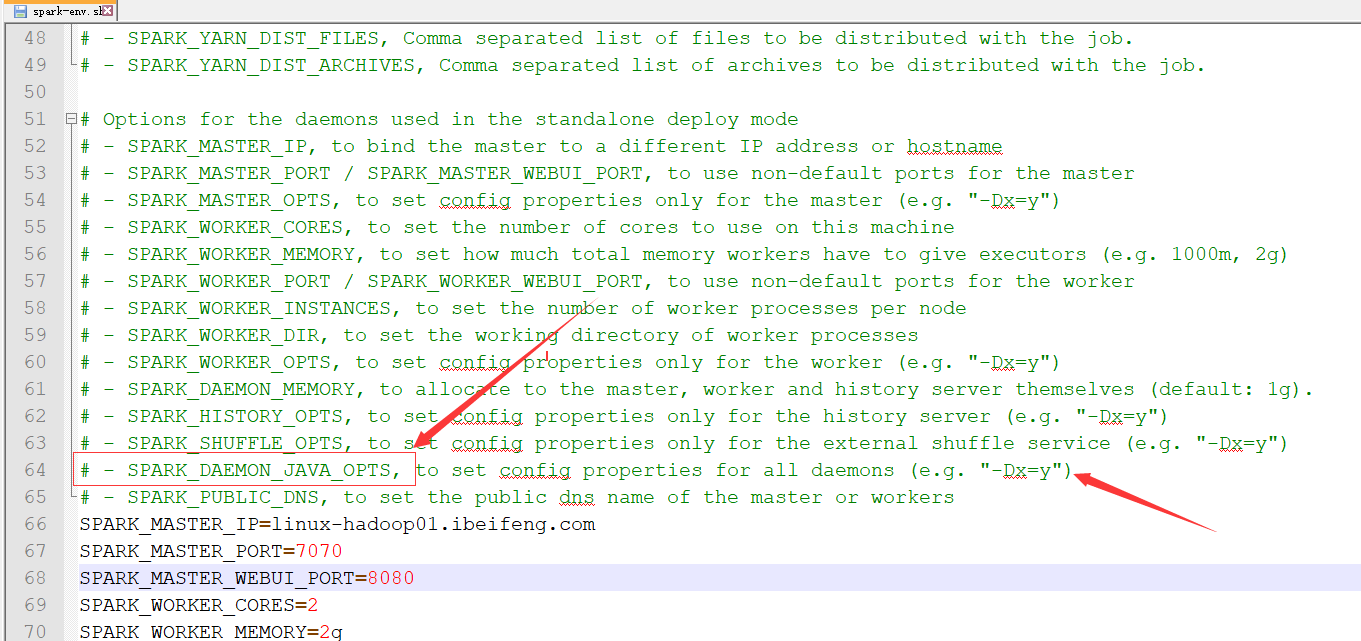
1. 修改conf/sparn-env.sh配置文件,打开conf/sparn-env.sh
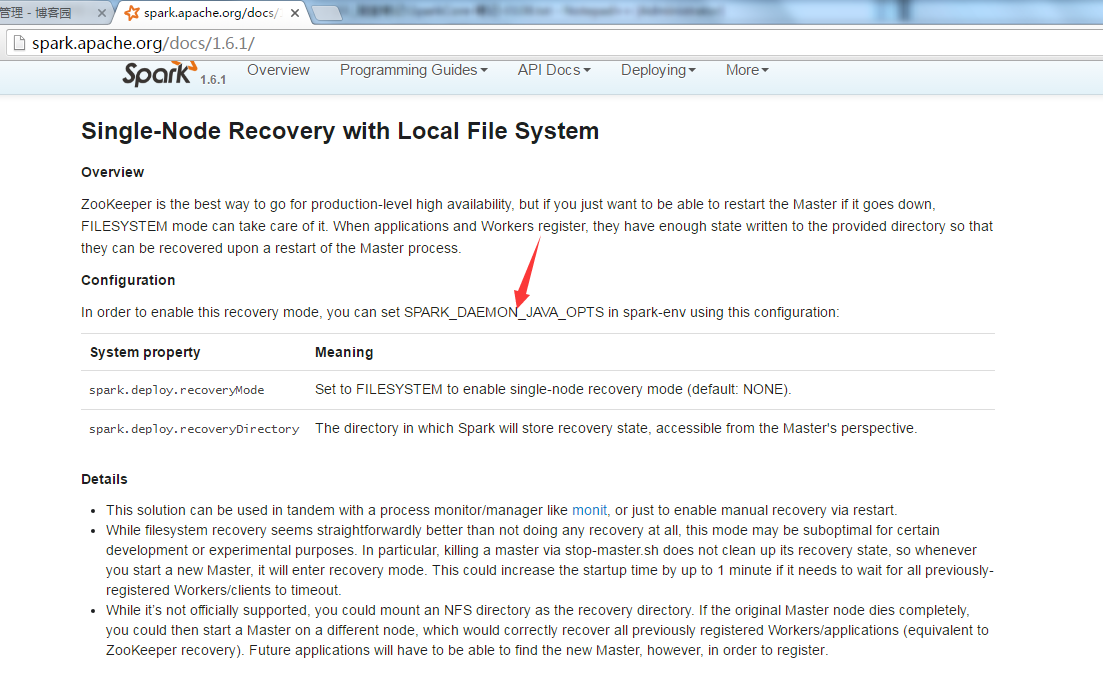
2. 给参数SPARK_DAEMON_JAVA_OPTS添加配置参数
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/tmp/xxxx"
一个参数是恢复模式,一个参数是恢复路劲
4.配置方式二(比较给力)
方式二:Standby Masters with ZooKeeper
类似于Hadoop2中的NameNode的HA机制,因此会自动转移
做法:
1. 修改conf/sparn-env.sh配置文件
2. 给参数SPARK_DAEMON_JAVA_OPTS添加配置参数
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop-senior01:2181,hadoop-senior02:2181,hadoop-senior03:2181 -Dspark.deploy.zookeeper.dir=/spark"

008 Spark中standalone模式的HA(了解,知道怎么配置即可)的更多相关文章
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
参考自:Spark部署三种方式介绍:YARN模式.Standalone模式.HA模式http://www.aboutyun.com/forum.php?mod=viewthread&tid=7 ...
- 【Spark篇】--Spark中Standalone的两种提交模式
一.前述 Spark中Standalone有两种提交模式,一个是Standalone-client模式,一个是Standalone-master模式. 二.具体 1.Standalon ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- 【Spark】Spark的Standalone模式安装部署
Spark执行模式 Spark 有非常多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则执行在集群中,眼下能非常好的执行在 Yarn和 Mesos 中.当然 Spark 还有自带的 St ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- 【Spark篇】---Spark中yarn模式两种提交任务方式
一.前述 Spark可以和Yarn整合,将Application提交到Yarn上运行,和StandAlone提交模式一样,Yarn也有两种提交任务的方式. 二.具体 1.yarn-clien ...
- Spark之standalone模式
standalone hdfs:namenode是主节点进程,datanode是从节点进程 yarn:resourcemanager是主节点进程,nodemanager是从节点进程 hdfs和yarn ...
- Spark在StandAlone模式下提交任务,spark.rpc.message.maxSize太小而出错
1.错误信息org.apache.spark.SparkException: Job aborted due to stage failure:Serialized task 32:5 was 172 ...
- Spark:Master High Availability(HA)高可用配置的2种实现
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题.如何解决这个单点故障的问题,Spar ...
随机推荐
- js 获取属性名称
$(function () { myfun(); }) function myfun() { var ...
- 第5月第7天 php slim
1. <?php require 'Slim/Slim.php'; require 'DBManagement.php'; \Slim\Slim::registerAutoloader(); $ ...
- 虚拟树研究-CheckBox初步判断只能在第一列
//虚拟树研究-CheckBox初步判断只能在第一列 procedure TWindowsXPForm.XPTreeInitNode(Sender: TBaseVirtualTree; ParentN ...
- python - 包装 和 授权
包装 # 包装(二次加工标准类型) # 继承 + 派生 的方式实现 定制功能 # 示例: # class list_customization(list): #重新定制append方法,判断添加的数据 ...
- EXT3.3.1在IE9 IE10click事件 失效怎么解决
各位Ext君有福了. var treePanel = new Ext.tree.TreePanel({ id:'treePanel_'+(menuIndex++),//让菜单id可控 title: t ...
- MR室内室外用户区分
mro_view_details_year中v3字段 1:室外用户 0:室内用户 主小区是室内站 主小区信号>-90dBm ==> 室内 主小区信号>-100dBm &&am ...
- Word打开默认显示缩略图,而不是文档结构图
So easy! 1.打开Word文档,点击缩略图右侧的"X",关闭缩略图: 2.打开菜单[视图],勾选"文档结构图": 3.关闭当前Word文档: 4.再次打 ...
- freeRTOS中文实用教程4--资源管理概述
1.前言 多任务系统中存在一种潜在的风险.当一个任务在使用某个资源的过程中,即还没有完全结束对资源的访问时,便被切出运行态,使得资源处于非一致,不完整的状态 2.并发抢占导致错误的场景 (1)访问外设 ...
- python操作haproxy.cfg文件
需求 1.查 输入:www.oldboy.org 获取当前backend下的所有记录 2.新建 输入: arg = { 'bakend': 'www.oldboy.org', 'record':{ ' ...
- [Android四大组件之二]——Service
Service是Android中四大组件之一,在Android开发中起到非常重要的作用,它运行在后台,不与用户进行交互. 1.Service的继承关系: java.lang.Object → andr ...