MapReduce Shuffle过程
MapReduce Shuffle 过程详解
一、MapReduce Shuffle过程
1、 Map
Shuffle过程
2、 Reduce
Shuffle过程

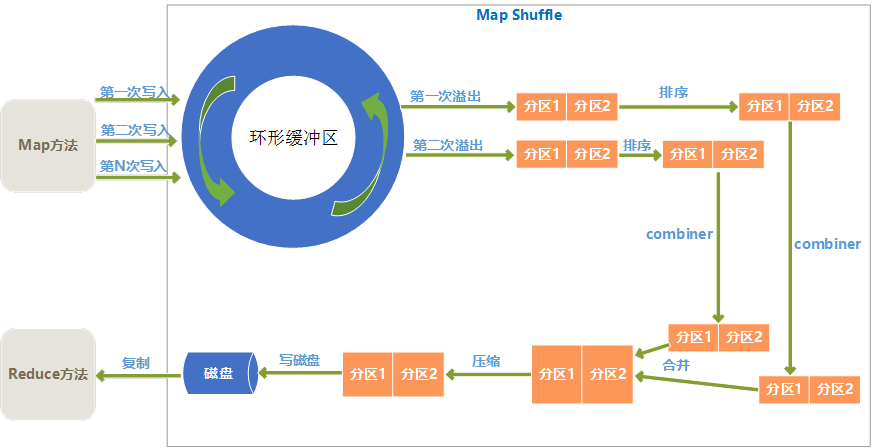
二、Map Shuffle过程
1、 环形缓冲区
Map输出结果是先放入内存中的一个环形缓冲区,这个环形缓冲区默认大小为100M(这个大小可以在io.sort.mb属性中设置),当环形缓冲区里的数据量达到阀值时(这个值可以在io.sort.spill.percent属性中设置)就会溢出写入到磁盘,环形缓冲区是遵循先进先出原则,Map输出一直不停地写入,一个后台进程不时地读取后写入磁盘,如果写入速度快于读取速度导致环形缓冲区里满了时,map输出会被阻塞直到写磁盘过程结束。
2、 分区
从环形缓冲区溢出到磁盘过程,是将数据写入mapred.local.dir属性指定目录下的特定子目录的过程。
但是在真正写入磁盘之前,要进行一系列的操作,首先就是对于每个键,根据规则计算出来将来要输出到哪个reduce,根据reduce不同分不同的区,分区是在内存里分的,分区的个数和将来的reduce个数是一致的。
3、 排序
在每个分区上,会根据键进行排序。
4、 combiner
combiner方法是对于map输出的结果按照业务逻辑预先进行处理,目的是对数据进行合并,减少map输出的数据量。
排序后,如果指定了conmbiner方法,就运行combiner方法使得map的结果更紧凑,从而减少写入磁盘和将来网络传输的数据量。
5、 合并溢出文件
环形缓冲区每次溢出,都会生成一个文件,所以在map任务全部完成之前,会进行合并成为一个溢出文件,每次溢出的各个文件都是按照分区进行排好序的,所以在合并文件过程中,也要进行分区和排序,最终形成一个已经分区和排好序的map输出文件。
在合并文件时,如果文件个数大于某个指定的数量(可以在min.num.spills.for.combine属性设置),就会进再次combiner操作,如果文件太少,效果和效率上,就不值得花时间再去执行combiner来减少数据量了。
6、 压缩
Map输出结果在进行了一系列的分区、排序、combiner合并、合并溢出文件后,得到一个map最终的结果后,就应该真正存储这个结果了,在存储之前,可以对最终结果数据进行压缩,一是可以节约磁盘空间,而是可以减少传递给reduce时的网络传输数据量。
默认是不进行压缩的,可以在mapred.compress.map.output属性设置为true就启用了压缩,而压缩的算法有很多,可以在mapred.map.output.compression.codec属性中指定采用的压缩算法,具体压缩详情,可以看本文的后面部分的介绍。
三、Reduce Shuffle过程
1、 复制数据
各个map完成时间肯定是不同的,只要有一个map执行完成,reduce就开始去从已完成的map节点上复制输出文件中属于它的分区中的数据,reduce端是多线程并行来复制各个map节点的输出文件的,线程数可以在mapred.reduce.parallel.copies属性中设置。
reduce将复制来的数据放入内存缓冲区(缓冲区大小可以在mapred.job.shuffle.input.buffer.percent属性中设置)。当内存缓冲区中数据达到阀值大小或者达到map输出阀值,就会溢写到磁盘。
写入磁盘之前,会对各个map节点来的数据进行合并排序,合并时如果指定了combiner,则会再次执行combiner以尽量减少写入磁盘的数据量。为了合并,如果map输出是压缩过的,要在内存中先解压缩后合并。
2、 合并排序
合并排序其实是和复制文件同时并行执行的,最终目的是将来自各个map节点的数据合并并排序后,形成一个文件。
3、 分组
分组是将相同key的键值对分为一组,一组是一个列表,列表中每一组在一次reduce方法中处理。
4、 执行Reduce方法
Reduce端的Shuffle完成后,就交由reduce方法来进行处理了。
四、MapReduce过程中的优化
1、 使用combiner减少数据量
2、 启用压缩
3、 合理配置reduce个数
五、MapRedue过程中的压缩设置
1、 压缩格式与算法
(1) 压缩格式
|
压缩格式 |
算法 |
文件扩展名 |
是否可以切分 |
|
DEFLATE |
DEFLATE |
.deflate |
否 |
|
Gzip |
DEFLATE |
.gz |
否 |
|
bzip2 |
bzip2 |
.gz |
是 |
|
LZO |
LZO |
.lzo |
否 |
|
LZ4 |
LZ4 |
.lz4 |
否 |
|
Snappy |
Snappy |
.snappy |
否 |
(2) Hadoop中压缩算法codec
|
压缩格式 |
Hadoop Codec |
|
DEFLATE |
org.apache.hadoop.io.compress.DefaultCodec |
|
gzip |
org.apache.hadoop.io.compress.GzipCodec |
|
bzip2 |
org.apache.hadoop.io.compress.BZip2Codec |
|
LZO |
org.apache.hadoop.io.lzo.LzopCodec |
|
LZ4 |
org.apache.hadoop.io.compress.Lz4Cdec |
|
Snappy |
org.apache.hadoop.io.compress.SnappyCodec |
2、 在*-site.xml文件中配置压缩
默认是不启用压缩的,如果对整个集群启用压缩,可以在mapred-site.xml中修改参数:
(1)
mapreduce.map.output.compress 是否对map任务输出进行压缩,默认是false。
(2)
mapreduce.map.output.compress.codec 设置map输出所用的压缩codec,默认是org.apache.hadoop.io.compress.DefaultCodec。
3、 在程序中配置压缩
Configuration configuration = new Configuration();
configuration.set("mapreduce.map.output.compress.","true");
configuration.setClass("mapreduce.map.output.compress.codec",
SnappyCodec.class, CompressionCodec.class);
附件列表
MapReduce Shuffle过程的更多相关文章
- 彻底理解MapReduce shuffle过程原理
彻底理解MapReduce shuffle过程原理 MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapR ...
- MapReduce:Shuffle过程的流程
Shuffle过程是MapReduce的核心,Shuffle描述着数据从map task输出到reduce task输入的这段过程. 1.map端
- MapReduce shuffle过程剖析及调优
MapReduce简介 在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的.数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问 ...
- 2.27 MapReduce Shuffle过程如何在Job中进行设置
一.shuffle过程 总的来说: *分区 partitioner *排序 sort *copy (用户无法干涉) 拷贝 *分组 group 可设置 *压缩 compress *combiner ma ...
- MapReduce:详解Shuffle过程(转)
/** * author : 冶秀刚 * mail : dennyy99@gmail.com */ Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapRedu ...
- MapReduce:详解Shuffle过程
Shuffle过程,也称Copy阶段.reduce task从各个map task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定的阀值,则写到磁盘上,否则直接放到内存中. 官方的Shuffl ...
- MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
- [转]MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
随机推荐
- Get-FilewithExtension
1: <# 2: 用途: 3: 根据指定的路径和文件类型查找出文件,显示其完整路径以及大小 4: 使用方法: 5: Get-FilewithExtension -path path1,path2 ...
- norm函数的作用,matlab
格式:n=norm(A,p)功能:norm函数可计算几种不同类型的返回A中最大一列和,即max(sum(abs(A))) 2 返回A的最大奇异值,和n=norm(A)用法一样 inf 返回A中最大一行 ...
- DM 多路径存储
DM多路径存储 系统环境:RHEL5.4 small install selinux and iptables disabled主机规划:主机网卡软件station133eth0: 192.168. ...
- Android中SQLite数据库小计
2016-03-16 Android数据库支持 本文节选并翻译<Enterprise Android - Programing Android Database Applications for ...
- 【腾讯Bugly干货分享】微信mars 的高性能日志模块 xlog
本文来自于腾讯bugly开发者社区,未经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/581c2c46bef1702a2db3ae53 Dev Club 是一个交流移动 ...
- Redis分布式锁服务(八)
阅读目录: 概述 分布式锁 多实例分布式锁 总结 概述 在多线程环境下,通常会使用锁来保证有且只有一个线程来操作共享资源.比如: object obj = new object(); lock (ob ...
- [Unity3D]自己动手重制坦克舰队ArmadaTank(2)从碰撞说起
[Unity3D]自己动手重制坦克舰队ArmadaTank(2)从碰撞说起 在上一篇里我给出了重制的坦克舰队效果图和试玩程序.本篇介绍一下玩家坦克和敌方坦克碰撞问题. +BIT祝威+悄悄在此留下版了个 ...
- Linux下MongoDB服务安装
Linux下MongoDB服务安装 MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案.MongoDB是一个介于关系数据库和非关系数据 ...
- Redis 发布订阅用法
一.发布订阅模型发布订阅其作用是为了减少依赖关系,通常也叫观察者模式.主要是把耦合点单独抽离出来作为第三方,隔离易变化的发送方和接收方. 发送方:只负责向第三方发送消息.(杂志社把读者杂志交给邮局)接 ...
- 操作数据库mysql
显示表结构 desc 表 显示数据库信息 show create database 数据库名 show create table 表名