如何计算假设检验的功效(power)和效应量(effect size)?
做完一个假设检验之后,如果结果具有统计显著性,那么还需要继续计算其效应量,如果结果不具有统计显著性,并且还需要继续进行决策的话,那么需要计算功效。
功效(power):正确拒绝原假设的概率,记作1-β。
假设检验的功效受以下三个因素影响:
- 样本量 (n):其他条件保持不变,样本量越大,功效就越大。
- 显著性水平 (α): 其他条件保持不变,显著性水平越低,功效就越小。
- 两总体之间的差异:其他条件保持不变,总体参数的真实值和估计值之间的差异越大,功效就越大。也可以说,效应量(effect size)越大,功效就越大。
应用:根据显著性水平α,效应量和样本容量n,计算功效。
(可用G*Power或Statsmodels计算)
单样本t检验:statsmodels.stats.power.tt_solve_power(effect_size=None, nobs=None, alpha=None, power=None, alternative='two-sided')
独立样本t检验:statsmodels.stats.power.tt_ind_solve_power(effect_size=None, nobs1=None, alpha=None, power=None, ratio=1.0, alternative='two-sided')
卡方拟合优度检验:statsmodels.stats.power.GofChisquarePower.solve_power(effect_size=None, nobs=None, alpha=None, power=None, n_bins=2)
F检验:statsmodels.stats.power.FTestPower.solve_power(effect_size=None, df_num=None, df_denom=None, nobs=None, alpha=None, power=None, ncc=1)
方差分析:statsmodels.stats.power.FTestAnovaPower.solve_power(effect_size=None, nobs=None, alpha=None, power=None, k_groups=2)
效应量(effect size): 样本间差异或相关程度的量化指标。
效应量通常用三种方式来衡量:(1) 标准均差(standardized mean difference),(2) 几率(odd ratio),(3) 相关系数(correlation coefficient)。
这里说一下第一种:标准均差(standardized mean difference)。主要有以下几种指标:
Cohen’s d : 两总体均值之间的标准差异。适用于两组样本的样本量和方差相似的情况。
计算公式: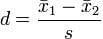
其中: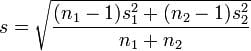


Hedges’ g: 是cohen的方法的改进,适用于两组样本的样本量不同的情况。
计算公式: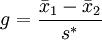
其中: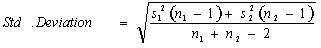
Glass’s Δ (delta): 和cohen的方法类似,但是只除以控制组的标准差。适用于两组样本的方差不同的情况。
计算公式: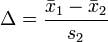

Cramer’s φ (Phi) or Cramer’s V: 用于测算类别型数据的效应量。当类别型变量包含2个类别时,使用Cramer’s phi,如果超过2个类别,那么使用Cramer’s V。

Cohen’s f2: 用于测算方差分析,多元回归之类的效应量。
计算公式: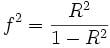
应用:根据显著性水平α,功效和样本容量n,计算效应量。
(可用G*Power或Statsmodels计算)
单样本t检验:statsmodels.stats.power.tt_solve_power(effect_size=None, nobs=None, alpha=None, power=None, alternative='two-sided')
独立样本t检验:statsmodels.stats.power.tt_ind_solve_power(effect_size=None, nobs1=None, alpha=None, power=None, ratio=1.0, alternative='two-sided')
卡方拟合优度检验:statsmodels.stats.power.GofChisquarePower.solve_power(effect_size=None, nobs=None, alpha=None, power=None, n_bins=2)
F方差齐性检验:statsmodels.stats.power.FTestPower.solve_power(effect_size=None, df_num=None, df_denom=None, nobs=None, alpha=None, power=None, ncc=1)
方差分析:statsmodels.stats.power.FTestAnovaPower.solve_power(effect_size=None, nobs=None, alpha=None, power=None, k_groups=2)
以上两种应用都属于事后检验(post hoc)。除此之外,还有一个应用就是:根据显著性水平α,功效和效应量,计算样本容量n。这属于事前检验(prior)。具体请见:《如何确定假设检验的样本量?》。
参考:
https://wenku.baidu.com/view/d78a82ecb9d528ea80c7792c.html
https://www.statisticssolutions.com/statistical-analyses-effect-size/
如何计算假设检验的功效(power)和效应量(effect size)?的更多相关文章
- 效应量Effect Size
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&am ...
- 去他的效应(what-the-hell effect)与自我放纵
去他的 效应(what-the-hell effect)与自我放纵 为什么写这篇文章: 对于我来说,但我感到疲惫——"无意拿起"手机,对自己说"随便看看"——但 ...
- 查看数据库表的数据量和SIZE大小的脚本修正
在使用桦仔的分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)的脚本时,遇到下面一些错误 这个是因为这些表的Schema是Maint,而不是默认的dbo,造成下面这段SQ ...
- 如何确定假设检验的样本量(sample size)?
在<如何计算假设检验的功效(power)和效应量(effect size)?>一文中,我们讲述了如何根据显著性水平α,效应量和样本容量n,计算功效,以及如何根据显著性水平α,功效和样本容量 ...
- 二型错误和功效(Type II Errors and Test Power)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&am ...
- R in action读书笔记(13)第十章 功效分析
功效分析 功效分析可以帮助在给定置信度的情况下,判断检测到给定效应值时所需的样本量.反过来,它也可以帮助你在给定置信度水平情况下,计算在某样本量内能检测到给定效应值的概率.如果概率低得难以接受,修改或 ...
- R笔记 单样本t检验 功效分析
R data analysis examples 功效分析 power analysis for one-sample t-test单样本t检验 例1.一批电灯泡,标准寿命850小时,标准偏差50,4 ...
- Power BI与Tableau基于Google搜索上的比较
在数据分析领域里,不少的数据爱好者都会关心什么数据分析产品最好用?最重要的是,很多的企业也特别希望员工能真正知道如何使用这些BI平台以确保公司的投资是值得.同类的文章,小悦也曾发布过,可参考最近< ...
- zookeeper分布式锁避免羊群效应(Herd Effect)
本文(转自:http://jm-blog.aliapp.com/?p=2554)主要讲述在使用ZooKeeper进行分布式锁的实现过程中,如何有效的避免“羊群效应( herd effect)”的出现. ...
随机推荐
- mysql性能的检查和优化方法
这个命令可以看到当前正在执行的sql语句,它会告知执行的sql.数据库名.执行的状态.来自的客户端ip.所使用的帐号.运行时间等信息 mysql在遇到严重性能问题时,一般都有这么几种可能:1.索引没有 ...
- why’s kafka so fast
As we all know that Kafka is very fast, much faster than most of its competitors. So what’s the reas ...
- FastDFS与hadoop的HDFS区别
主要是定位和应用场合不一样 HDFS: 要解决并行计算中分布式存储数据的问题.其单个数据文件通常很大,采用了分块(切分)存储的方式. FastDFS: 主要用于大中网站,为文件上传和下载提供在线服务. ...
- Windows怎么安装配置Elasticsearch
进入Elasticsearch官网,点击Download,Elasticsearch默认端口9200 然后进入下图:有各种版本,我选择windows版本 下载之后,解压得到Elasticsearch文 ...
- 使用GitHub/码云/Git个性化设置
参考链接:https://www.liaoxuefeng.com/wiki/896043488029600/900937935629664 这似乎很可笑,我还从来没有想过为一个网站的使用方法写一篇来记 ...
- Java中的集合类(List,Set.Map)
1.List 1.1 Arraylist 与 LinkedList 区别 是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全: 底层数据结构: Arr ...
- Bloom’S Taxonomy
引用:https://www.learning-theories.com/blooms-taxonomy-bloom.html Bloom's Taxonomy is a model that is ...
- MYSQL中IN,INSTR,FIND_IN_SET函数效率比较(转)
今天写代码时前台传过来类似‘1,2,3,4,5,6’的字符串,这种情况直接用IN是无效的,需要把字符串分割成数组或者组装成列表,然后再利用mabatis的foreach函数 <select id ...
- mybatis中集成sharing-jdbc采坑
1. mybatis中集成sharing-jdbc采坑 1.1. 错误信息 Caused by: org.apache.ibatis.binding.BindingException: Invalid ...
- 记录下vue keep-alive IOS下无法保存滚动scroll位置的问题
最近 做的项目,遇到了一点小麻烦,就是我一个页面A页面是加载 列表数据 ,B页面是展示详细信息的.A进去B时,缓存A页面. 效果 做出来 后,缓存是缓存数据 了,但是当我A页面的列表数据 好多,要滚动 ...