why’s kafka so fast
As we all know that Kafka is very fast, much faster than most of its competitors. So what’s the reason here?
Avoid Random Disk Access
Kafka writes everything onto the disk in order and consumers fetch data in order too. So disk access always works sequentially instead of randomly. For traditional hard disks(HDD), sequential access is much faster than random access. Here is a comparison:
| hardware | sequential writes | random writes |
|---|---|---|
| 6 * 7200rpm SATA RAID-5 | 300MB/s | 50KB/s |
Kafka Writes Everything Onto The Disk Instead of Memory
Yes, you read that right. Kafka writes everything onto the disk instead of memory. But wait a moment, isn’t memory supposed to be faster than disks? Typically it’s the case, for Random Disk Access. But for sequential access, the difference is much smaller. Here is a comparison taken from https://queue.acm.org/detail.cfm?id=1563874.

As you can see, it’s not that different. But still, sequential memory access is faster than Sequential Disk Access, why not choose memory? Because Kafka runs on top of JVM, which gives us two disadvantages.
1.The memory overhead of objects is very high, often doubling the size of the data stored(or even higher).
2.Garbage Collection happens every now and then, so creating objects in memory is very expensive as in-heap data increases because we will need more time to collect unused data(which is garbage).
So writing to file systems may be better than writing to memory. Even better, we can utilize MMAP(memory mapped files) to make it faster.
Memory Mapped Files(MMAP)
Basically, MMAP(Memory Mapped Files) can map the file contents from the disk into memory. And when we write something into the mapped memory, the OS will flush the change onto the disk sometime later. So everything is faster because we are using memory actually, but in an indirect way. So here comes the question. Why would we use MMAP to write data onto disks, which later will be mapped into memory? It seems to be a roundabout route. Why not just write data into memory directly? As we have learned previously, Kafka runs on top of JVM, if we wrote data into memory directly, the memory overhead would be high and GC would happen frequently. So we use MMAP here to avoid the issue.
Zero Copy
Suppose that we are fetching data from the memory and sending them to the Internet. What is happening in the process is usually twofold.
1.To fetch data from the memory, we need to copy those data from the Kernel Context into the Application Context.
2.To send those data to the Internet, we need to copy the data from the Application Context into the Kernel Context.
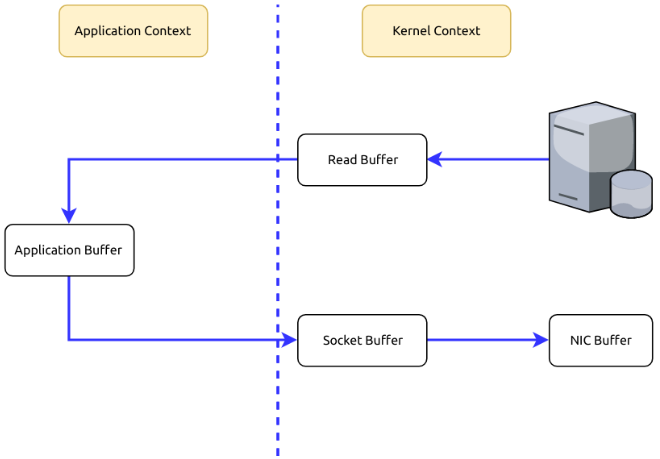
As you can see, it’s redundant to copy data between the Kernel Context and the Application Context. Can we avoid it? Yes, using Zero Copy we can copy data directly from the Kernel Context to the Kernel Context.

Batch Data
Kafka only sends data when batch.size is reached instead of one by one. Assuming the bandwidth is 10MB/s, sending 10MB data in one go is much faster than sending 10000 messages one by one(assuming each message takes 100 bytes).
"I would be fine and made no troubles."
why’s kafka so fast的更多相关文章
- Apache Kafka for Item Setup
At Walmart.com in the U.S. and at Walmart's 11 other websites around the world, we provide seamless ...
- Apache Kafka - Schema Registry
关于我们为什么需要Schema Registry? 参考, https://www.confluent.io/blog/how-i-learned-to-stop-worrying-and-love- ...
- Understanding, Operating and Monitoring Apache Kafka
Apache Kafka is an attractive service because it's conceptually simple and powerful. It's easy to un ...
- Build an ETL Pipeline With Kafka Connect via JDBC Connectors
This article is an in-depth tutorial for using Kafka to move data from PostgreSQL to Hadoop HDFS via ...
- How to choose the number of topics/partitions in a Kafka cluster?
This is a common question asked by many Kafka users. The goal of this post is to explain a few impor ...
- kafka producer源码
producer接口: /** * Licensed to the Apache Software Foundation (ASF) under one or more * contributor l ...
- Flume-ng+Kafka+storm的学习笔记
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- Apache Kafka: Next Generation Distributed Messaging System---reference
Introduction Apache Kafka is a distributed publish-subscribe messaging system. It was originally dev ...
- Exploring Message Brokers: RabbitMQ, Kafka, ActiveMQ, and Kestrel--reference
[This article was originally written by Yves Trudeau.] http://java.dzone.com/articles/exploring-mess ...
随机推荐
- 深入理解Java对象
深入理解Java对象(理清关系) 1.对象的创建过程: 所有创建过程如下所示: new 类名 根据new的参数在常量池中定位一个类的符号引用. 如果没有找到这个符号引用,说明类还没有被加载,则进行类的 ...
- python 树与二叉树的实现
1.树的基本概念 1.树的定义 树的定义是递归的,树是一种递归的数据结构. 1)树的根结点没有前驱结点,除根结点之外所有结点有且只有一个前驱结点 2)树中所有结点可以有零个或多个后继结点 2.树的术语 ...
- java引用的强制转型
在java的面向对象的特性里,父类的引用可以指向子类的实例对象.但是,如果一个引用b(b本身指向了一个对象)想赋值给引用a,b不是a的类型且不是a的子类类型,那么就需要强制转换,并有失败的可能性,这个 ...
- jquery实现checkbox列表的全选不选
html代码 <th><input type="checkbox" onclick="selectAll(this);" />全选/取消 ...
- conan使用(三)--打包只有头文件的库
参考:https://docs.conan.io/en/latest/howtos/header_only.html?highlight=header%20only 对于只含头文件的库打包非常简单,以 ...
- 201871010101-陈来弟《面向对象程序设计(java)》第七周学习总结
201871010101-陈来弟<面向对象程序设计(java)>第七周学习总结 项目 内容 <面向对象程序设计(java)> https://www.cnblogs.com/n ...
- Linux下的SVN服务器搭建(八)
1. 通过yum命令安装svnserve yum -y install subversion #查看svn安装位置 rpm -ql subversion 2. 创建版本库目录(此仅为目录,为后面创建版 ...
- CBV和FBV用户认证装饰器
FBV装饰器用户验证 CBV装饰器用户验证 装饰器位置 或 或
- LG5200 「USACO2019JAN」Sleepy Cow Sorting 树状数组
\(\mathrm{Sleepy Cow Sorting}\) 问题描述 LG5200 题解 树状数组. 设\(c[i]\)代表\([1,i]\)中归位数. 显然最终的目的是将整个序列排序为一个上升序 ...
- UML系列
UML类图:https://www.cnblogs.com/shindo/p/5579191.html UML用例图:https://www.jianshu.com/p/3cde67aed8e9 UM ...