2. 执行Spark SQL查询
2.1 命令行查询流程
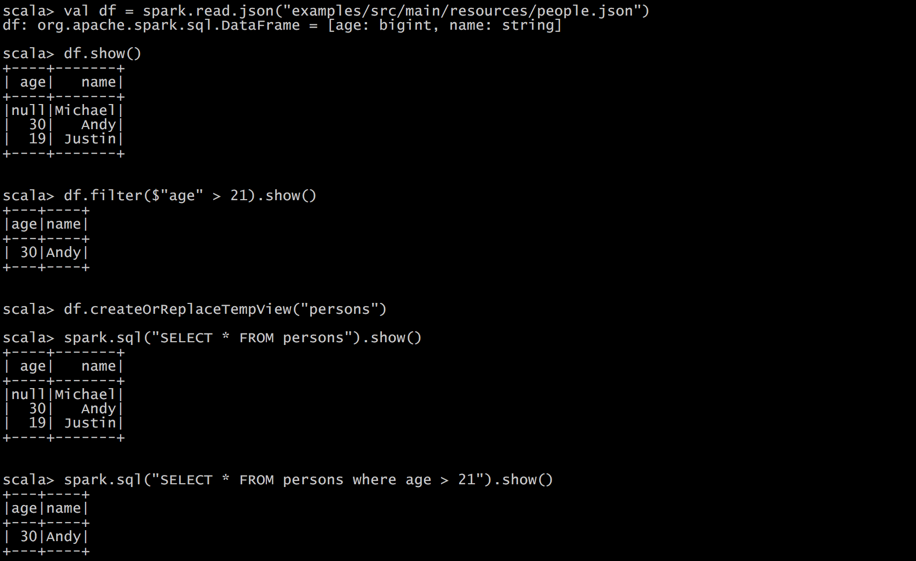
打开Spark shell
例子:查询大于21岁的用户
创建如下JSON文件,注意JSON的格式:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2.2 IDEA创建Spark SQL程序
IDEA中程序的打包和运行方式都和SparkCore类似,Maven依赖中需要添加新的依赖项:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
程序如下:
package com.c.sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
/**
* Created by huicheng on 15/07/2019.
*/
object HelloWorld { val logger = LoggerFactory.getLogger(HelloWorld.getClass)
def main(args: Array[String]) {
//创建 SparkConf()并设置App名称
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
df.filter($"age" > 21).show()
df.createOrReplaceTempView("persons")
spark.sql("SELECT * FROM persons where age > 21").show()
spark.stop()
}
}
2. 执行Spark SQL查询的更多相关文章
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- SQL Server-聚焦sp_executesql执行动态SQL查询性能真的比exec好?
前言 之前我们已经讨论过动态SQL查询呢?这里为何再来探讨一番呢?因为其中还是存在一定问题,如标题所言,很多面试题也好或者有些博客也好都在说在执行动态SQL查询时sp_executesql的性能比ex ...
- Django文档阅读之执行原始SQL查询
Django提供了两种执行原始SQL查询的方法:可以使用Manager.raw()来执行原始查询并返回模型实例,或者可以完全避免模型层直接执行自定义SQL. 每次编写原始SQL时都要关注防止SQL注入 ...
- 在sql server中怎样获得正在执行的Sql查询
方法1:使用DBCC inputbuffer(spid) 使用SP_WHO获得SPID,然后再执行上面的DBCC command,参见下图 执行一段sql语句 打开另一个query窗口并执行SP_WH ...
- spark sql 查询hive表并写入到PG中
import java.sql.DriverManager import java.util.Properties import com.zhaopin.tools.{DateUtils, TextU ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- Spark SQL基本概念与基本用法
1. Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为 ...
- 自适应查询执行:在运行时提升Spark SQL执行性能
前言 Catalyst是Spark SQL核心优化器,早期主要基于规则的优化器RBO,后期又引入基于代价进行优化的CBO.但是在这些版本中,Spark SQL执行计划一旦确定就不会改变.由于缺乏或者不 ...
- C# EF使用SqlQuery直接操作SQL查询语句或者执行过程
Entity Framework是微软出品的高级ORM框架,大多数.NET开发者对这个ORM框架应该不会陌生.本文主要罗列在.NET(ASP.NET/WINFORM)应用程序开发中使用Entity F ...
随机推荐
- 如何学习uni-app?
uni-app 是一个使用 Vue.js 开发跨平台应用的前端框架. 开发者通过编写 Vue.js 代码,uni-app 将其编译到iOS.Android.微信小程序.H5等多个平台,保证其正确运行并 ...
- javascript轮询请求服务器
抛出问题:web浏览器如何与服务保持通信? 方法一:Ajax轮询 方法二:EventSource轮询 方法三:websocket保持长连接 下面的解决方案是,Ajax轮询与EventSource轮询的 ...
- 【洛谷】P1449 后缀表达式
P1449 后缀表达式 分析: 简单的模拟题. 熟练容器stack的话很容易解决. stack,栈,有先进后出的特性. 比如你有一个箱子,你每放进第一个数时,就往箱底放,放第二个数时就在第一个数的上面 ...
- Dubbo+zookeeper实现单表的增删改查
1.数据库准备 建表语句 CREATE TABLE `tb_brand` ( `id` ) NOT NULL AUTO_INCREMENT, `name` ) DEFAULT NULL COMMENT ...
- 怎么在浏览器设置cookie
document.cookie="jwt=xxxxxx" 遇到了一个bug 开了代理没有办法做图片上传
- 因在缓存对象中增加字段,而导致Redis中取出缓存转化成Java对象时出现反序列化失败的问题
背景描述 因为业务需求的需要,我们需要在原来项目中的一个DTO类中新增两个字段(我们项目使用的是dubbo架构,这个DTO在A项目/服务的domain包中,会被其他的项目如B.C.D引用到).但是这个 ...
- IE安全限制
在安全级别下面设置置进行如下调整: A.ActiveX控件自动提示:启用 B.对标记为可安全执行脚本的ActiveX控件执行脚本:启用 C.对未标记为可安全执行脚本的ActiveX控件初始化并执行脚本 ...
- Cesium学习笔记(六):几何和外观(Geometry and Appearances)【转】
https://blog.csdn.net/UmGsoil/article/details/74912638 我们先直接来看一个例子 var viewer = new Cesium.Viewer('c ...
- Research Guide for Neural Architecture Search
Research Guide for Neural Architecture Search 2019-09-19 09:29:04 This blog is from: https://heartbe ...
- Cache busting
Cache busting https://www.keycdn.com/support/what-is-cache-busting https://curtistimson.co.uk/post/f ...