2. 执行Spark SQL查询
2.1 命令行查询流程
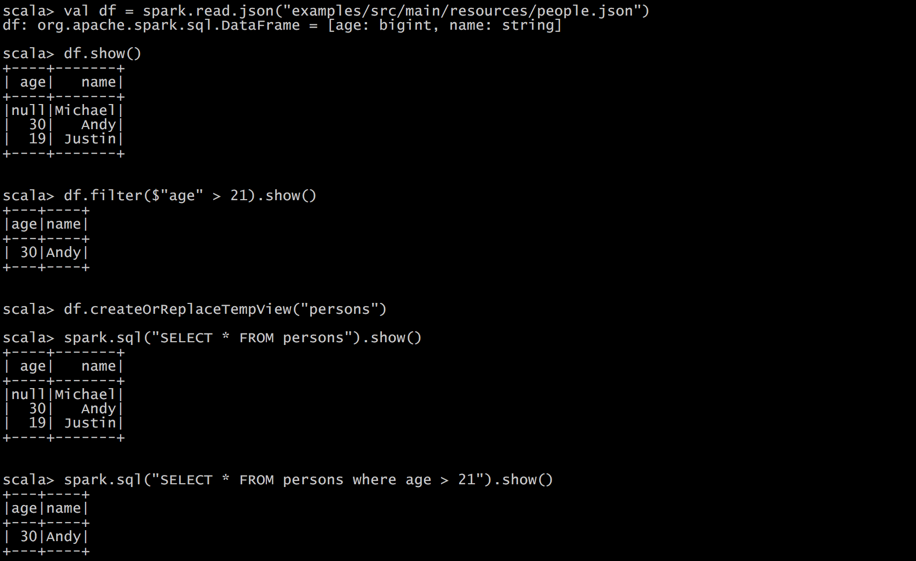
打开Spark shell
例子:查询大于21岁的用户
创建如下JSON文件,注意JSON的格式:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2.2 IDEA创建Spark SQL程序
IDEA中程序的打包和运行方式都和SparkCore类似,Maven依赖中需要添加新的依赖项:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
程序如下:
package com.c.sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
/**
* Created by huicheng on 15/07/2019.
*/
object HelloWorld { val logger = LoggerFactory.getLogger(HelloWorld.getClass)
def main(args: Array[String]) {
//创建 SparkConf()并设置App名称
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
df.filter($"age" > 21).show()
df.createOrReplaceTempView("persons")
spark.sql("SELECT * FROM persons where age > 21").show()
spark.stop()
}
}
2. 执行Spark SQL查询的更多相关文章
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- SQL Server-聚焦sp_executesql执行动态SQL查询性能真的比exec好?
前言 之前我们已经讨论过动态SQL查询呢?这里为何再来探讨一番呢?因为其中还是存在一定问题,如标题所言,很多面试题也好或者有些博客也好都在说在执行动态SQL查询时sp_executesql的性能比ex ...
- Django文档阅读之执行原始SQL查询
Django提供了两种执行原始SQL查询的方法:可以使用Manager.raw()来执行原始查询并返回模型实例,或者可以完全避免模型层直接执行自定义SQL. 每次编写原始SQL时都要关注防止SQL注入 ...
- 在sql server中怎样获得正在执行的Sql查询
方法1:使用DBCC inputbuffer(spid) 使用SP_WHO获得SPID,然后再执行上面的DBCC command,参见下图 执行一段sql语句 打开另一个query窗口并执行SP_WH ...
- spark sql 查询hive表并写入到PG中
import java.sql.DriverManager import java.util.Properties import com.zhaopin.tools.{DateUtils, TextU ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- Spark SQL基本概念与基本用法
1. Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为 ...
- 自适应查询执行:在运行时提升Spark SQL执行性能
前言 Catalyst是Spark SQL核心优化器,早期主要基于规则的优化器RBO,后期又引入基于代价进行优化的CBO.但是在这些版本中,Spark SQL执行计划一旦确定就不会改变.由于缺乏或者不 ...
- C# EF使用SqlQuery直接操作SQL查询语句或者执行过程
Entity Framework是微软出品的高级ORM框架,大多数.NET开发者对这个ORM框架应该不会陌生.本文主要罗列在.NET(ASP.NET/WINFORM)应用程序开发中使用Entity F ...
随机推荐
- HAVING 搜索条件在进行分组操作之后应用
HAVING 搜索条件在进行分组操作之后应用: 如:查询帖子访问量大于15的用户id: select t.user_id,u.name,sum(count_view) from t_topic t l ...
- 括号匹配(POJ2955)题解
原题地址:http://poj.org/problem?id=2955 题目大意:给出一串括号,求其中的最大匹配数. 我这么一说题目大意估计很多人就蒙了,其实我看到最开始的时候也是很蒙的.这里就来解释 ...
- Hash算法解决冲突的四种方法
Hash算法解决冲突的方法一般有以下几种常用的解决方法 1, 开放定址法: 所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入 公式为 ...
- 2019_软工实践_Beta(1/5)
队名:955 组长博客:点这里! 作业博客:点这里! 组员情况 组员1(组长):庄锡荣 过去两天完成了哪些任务 文字/口头描述 检测网站不合理的地方,给组员定下相应时间进度的安排 展示GitHub当 ...
- CentOS7安装JDK1.8图文教程
https://blog.csdn.net/weixin_42266606/article/details/80863781 1.下载 jdk 的 tar 包 网址:http://www.oracle ...
- 微信小程序上传单张或多张图片
-- chooseImage: function () { let that = this; let worksImgs = that.data.worksImgs; let len = that.d ...
- pg执行计划分析小笔记
开发同事问,为什么一个标量子查询,放在where子句后进行大小判断,比不放在where子句后进行判断大小运行的更快?按道理加了一次判断,不是应该变慢么? 把语句拿过来,看了一下两个语句的执行计划: 语 ...
- git如何查找已经被删除文件的历史修改记录?
答: 使用以下命令即可: git log --all --full-history -- <path-to-file>
- ARM USB 通信(转)
ARM USB 通信 采用ZLG的动态链接库,动态装载. ARM是Context-M3-1343. 在C++ Builder 6 中开发的上位机通信软件. USB通信代码如下: //--------- ...
- JetBrainsIDEA-structure结构继承的图标说明
图标3表示重写继承类中方法 图标2表示实现继承类抽象方法或接口中的方法 图标1表示未使用继承类中的方法 类中方法并非只统计显示继承类或实现接口中方法,而是对该类中所有方法进行分类,有可能某些方法是继承 ...