攻防世界--crackme
测试文件:https://adworld.xctf.org.cn/media/task/attachments/088c3bd10de44fa988a3601dc5585da8.exe
1.准备
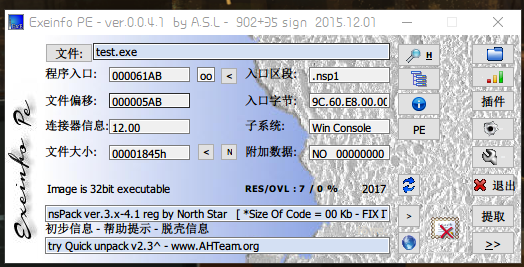
获取信息
- 32位文件
- 北斗压缩壳(nsPack)
1.脱壳
1.1 OD打开(esp定律法)


Word或者DWord都可以


点击确认就行。
这样我们的断点就下好了,直接F9运行到断点即可。
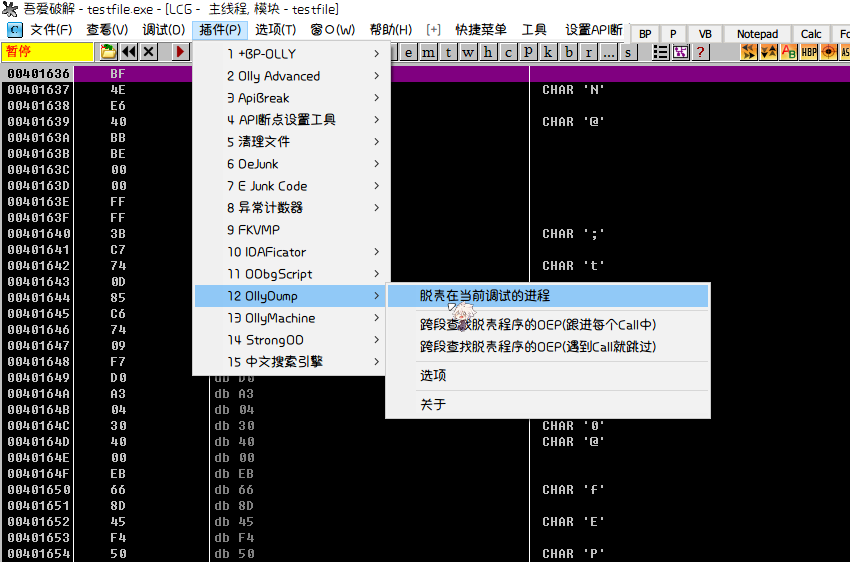
选择OllyDump插件进行脱壳。
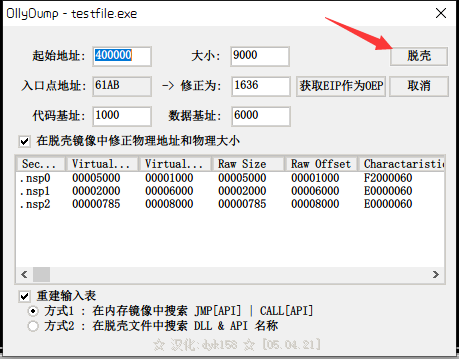
将文件重命名就可以了。
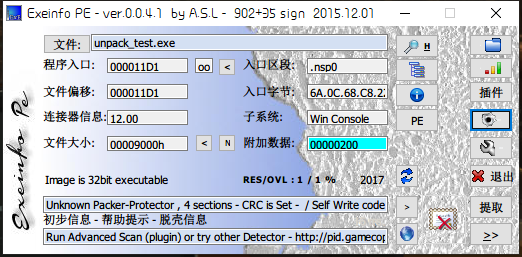
1.2 软件脱壳法
这个没什么讲究,拖进去脱壳就行
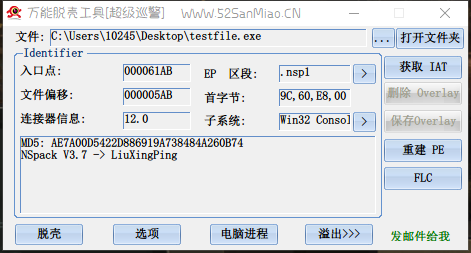
不过这个方法有个缺点是文件有损坏
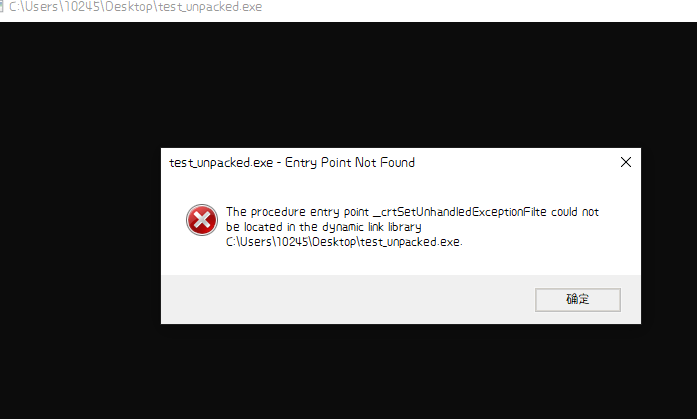
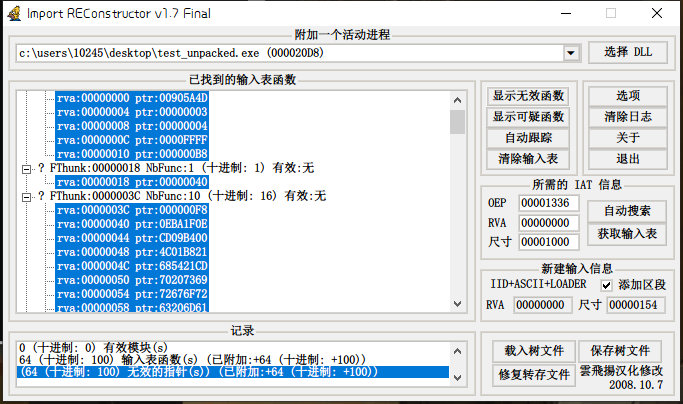
可以使用ImportREC进行修复
2.IDA打开
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // eax
int v4; // eax
char Buf; // [esp+4h] [ebp-38h]
char Dst; // [esp+5h] [ebp-37h] Buf = ;
memset(&Dst, , 0x31u);
printf("Please Input Flag:");
gets_s(&Buf, 0x2Cu);
if ( strlen(&Buf) == )
{
v4 = ;
while ( (*(&Buf + v4) ^ byte_402130[v4 % ]) == dword_402150[v4] )
{
if ( ++v4 >= )
{
printf("right!\n");
goto LABEL_8;
}
}
printf("error!\n");
LABEL_8:
result = ;
}
else
{
printf("error!\n");
result = -;
}
return result;
}
3.代码分析
通过第42行代码,可以了解到flag长度为42
通过第15行代码,我们知道输入的正确flag与byte_402130[v4 % 16]进行异或等于dword_402150[v4],这个v4就是一个数组下标,最大为41
.nsp0: byte_402130 db 't' ; DATA XREF: _main:loc_40107F↑r
.nsp0: aHisIsNotFlag db 'his_is_not_flag',
实际上就是"this_is_not_flag"
.nsp0: dword_402150 dd 12h ; DATA XREF: _main+8D↑r
.nsp0: dd , , 14h, 24h, 5Ch, 4Ah, 3Dh, 56h, 0Ah, 10h, 67h,
.nsp0: dd 41h,
.nsp0:0040218C dd , 46h, 5Ah, 44h, 42h, 6Eh, 0Ch, 44h, 72h, 0Ch, 0Dh
.nsp0:0040218C dd 40h, 3Eh, 4Bh, 5Fh, , , 4Ch, 5Eh, 5Bh, 17h, 6Eh, 0Ch
.nsp0:0040218C dd 16h, 68h, 5Bh, 12h, dup()
.nsp0: dd 48h, 0Eh dup()
.nsp0:0040223C dd offset dword_403000
.nsp0: dd offset dword_4022B0
.nsp0: dd , 53445352h, 41D713B4h, 4CDD5318h, 12DCFFBAh, 0D5AF8709h
.nsp0: dd
这段数字实际上就需要42个。
3.脚本获取
byte_402130 = "this_is_not_flag"
dword_402150 = [ 0x12, 4, 8, 0x14, 0x24, 0x5C, 0x4A, 0x3D, 0x56, 0x0A, 0x10, 0x67,
0, 0x41, 0, 1, 0x46, 0x5A, 0x44, 0x42, 0x6E, 0x0C, 0x44, 0x72, 0x0C, 0x0D,
0x40, 0x3E, 0x4B, 0x5F, 2, 1, 0x4C, 0x5E, 0x5B, 0x17, 0x6E, 0x0C, 0x16, 0x68,
0x5B, 0x12, 0, 0, 0x48 ] x = '' for i in range(0,42):
x += chr(dword_402150[i]^ord(byte_402130[i%16])) print(x)

4.get flag!
flag{59b8ed8f-af22-11e7-bb4a-3cf862d1ee75}
攻防世界--crackme的更多相关文章
- xctf攻防世界——crackme writeup
感谢xctf提供学习平台 https://adworld.xctf.org.cn crackme有壳,脱壳部分见文章: https://www.cnblogs.com/hongren/p/126332 ...
- 逆向-攻防世界-crackme
查壳,nSpack壳,直接用软件脱壳,IDA载入程序. 很明显,就是将402130的数据和输入的数据进行异或,判断是否等于402150处的数据.dwrd占4字节. 这道题主要记录一下刚学到的,直接在I ...
- CTF--web 攻防世界web题 robots backup
攻防世界web题 robots https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=506 ...
- CTF--web 攻防世界web题 get_post
攻防世界web题 get_post https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=5 ...
- 攻防世界 web进阶练习 NewsCenter
攻防世界 web进阶练习 NewsCenter 题目是NewsCenter,没有提示信息.打开题目,有一处搜索框,搜索新闻.考虑xss或sql注入,随便输入一个abc,没有任何搜索结果,页面也没有 ...
- 【攻防世界】高手进阶 pwn200 WP
题目链接 PWN200 题目和JarvisOJ level4很像 检查保护 利用checksec --file pwn200可以看到开启了NX防护 静态反编译结构 Main函数反编译结果如下 int ...
- XCTF攻防世界Web之WriteUp
XCTF攻防世界Web之WriteUp 0x00 准备 [内容] 在xctf官网注册账号,即可食用. [目录] 目录 0x01 view-source2 0x02 get post3 0x03 rob ...
- 攻防世界 | CAT
来自攻防世界官方WP | darkless师傅版本 题目描述 抓住那只猫 思路 打开页面,有个输入框输入域名,输入baidu.com进行测试 发现无任何回显,输入127.0.0.1进行测试. 发现已经 ...
- 攻防世界 robots题
来自攻防世界 robots [原理] robots.txt是搜索引擎中访问网站的时候要查看的第一个文件.当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在, ...
随机推荐
- Memcache--02 源码安装nginx,php
目录 一.session共享问题介绍 二.环境准备 一.session共享问题介绍 session主要用于服务端存储用户会话信息,cookie用于浏览器存储用户会话信息. 单系统服务session都存 ...
- [Tvvj1391]走廊泼水节(最小生成树)
[Tvvj1391]走廊泼水节 Description 给定一棵N个节点的树,要求增加若干条边,把这棵树扩充为完全图,并满足图的唯一最小生成树仍然是这棵树.求增加的边的权值总和最小是多少. 完全图:完 ...
- idea hibernate console 执行hql报错
报错信息 hql> select a from GDXMZD a[2019-08-29 13:45:01] org.hibernate.service.spi.ServiceException: ...
- CSP2019初赛训练
[解释执行语言] C,C++,Pascal都是编译执行的语言,Python是解释执行. 扩展:JS.PHP也是解释运行语言.解释性灵活但是效率较低.一些解释性语言也有了也能在一定程度上编译,或者使用虚 ...
- 学习旧岛小程序 (1) flex 布局
css : view 相当于 div 块级元素 display 默认设置 block display:inline 设置后 设置宽度高度是无效的 要设置宽度高度 又要设置为行内元素 我们设置: (1) ...
- loadrunner 使用
loadrunner给我的感觉很强势吧,第一次接触被安装包吓到了,当时用的是win10安装11版本的,各种安装失败,印象很深刻,那时候全班二三十号人,搞环境搞了两天,后来无奈,重做系统换成win7的了 ...
- hdu 5212 : Code【莫比乌斯】
题目链接 题给代码可以转化为下面的公式 然后用F[n]记录公约数为n的(a[i],a[j])对数,用f[n]记录最大公约数为n的(a[i],a[j])对数 之后枚举最大公约数d 至于求F[n],可以先 ...
- iOS多媒体总结&进入后台播放音乐
1. 播放mp3需要导入框架,AVFoundation支持音频文件(.caf..aif..wav..wmv和.mp3)的播放. #import <AVFoundation/AVFoundatio ...
- Linux内核设计与实现 总结笔记(第五章)系统调用
系统调用 内核提供了用户进程和内核交互的接口,使得应用程序可以受限制的访问硬件设备. 提供这些接口主要是为了保证系统稳定可靠,避免应用程序恣意妄行. 一.内核通信 系统调用在用户空间进程和硬件设备之间 ...
- 数字类别生成onehot
对应行的列#原始标签 my_label = np.array([3,4,2,4,6,1]) #类别数量 num_class = 6 #样本数量 num = my_label.shape[0] #生成o ...