【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看
先分析网站内容,红色部分即是网站文章内容div,可以看到,每一页有15篇文章

随便打开一个div来看,可以看到,蓝色部分除了一个文章标题以外没有什么有用的信息,而注意红色部分我勾画出的地方,可以知道,它是指向文章的地址的超链接,那么爬虫只要捕捉到这个地址就可以了。

接下来在一个问题就是翻页问题,可以看到,这和大多数网站不同,底部没有页数标签,而是查看更多,这里让我当时突然有点无从下手。
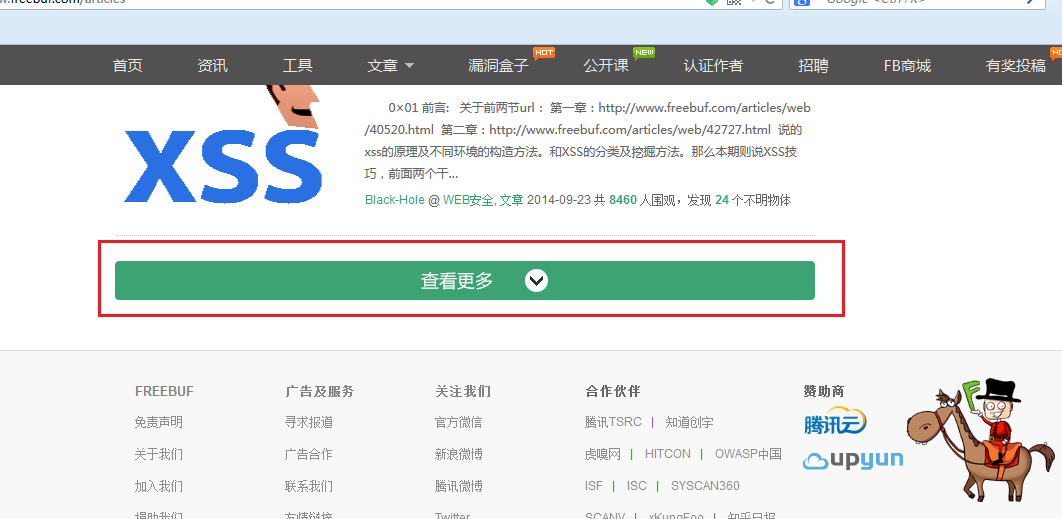
不过在查看源文件时我发现了如下图所示的一个超链接,经测试它指向下一页,那么通过改变其最后的数值,就可以定位到相应的页数上。
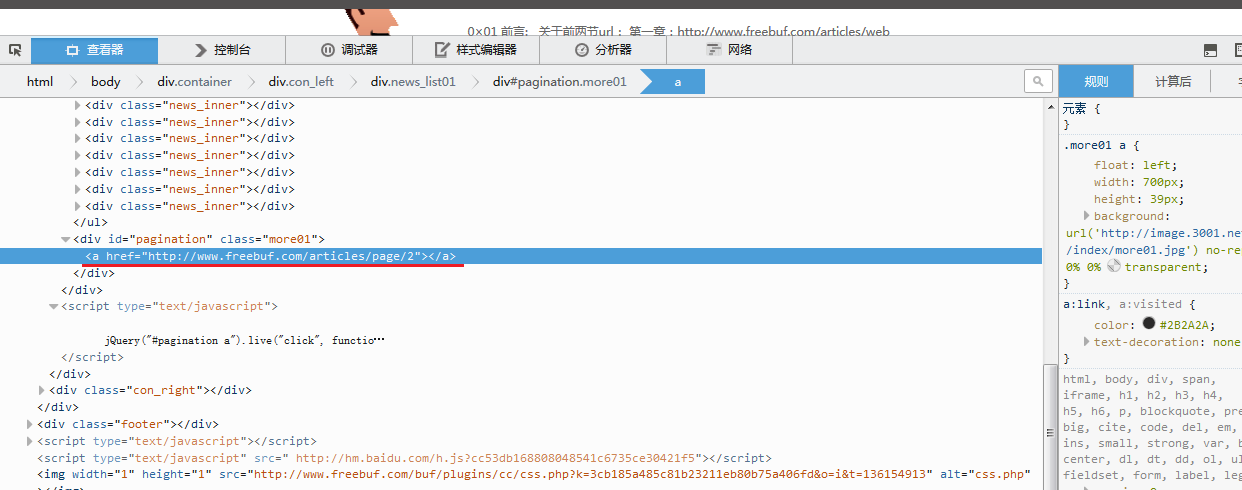
那么由以上信息,就可以对爬虫的步骤有一个相应的解决方案
1.抓取每一页上的所有文章的位置
2.捕捉每一页文章的URL
3.处理捕捉到的URL
那么问题又来了,我该如何定位每一篇文章在其源代码中的位置呢?
以第一篇文章为例,在源代码中查询”<dt><a href=”这个字符串,为什么要查询这个字符串呢?因为每一篇文章的url都以它开头,那么我只要找到这个字符串就定位了每一篇文章的开始位置,定位到文章的开始位置后,还必须定位文章的结束位置,才能提取出中间的url,如下图所示

代码:
import urllib
import string
#定义要抓取的页面
url = 'http://www.freebuf.com/articles'
#读取要抓取的页面
globalcontent = urllib.urlopen(url).read()
#捕捉文章列表
#这里在源码中查询"<dt><a href="这个字符串
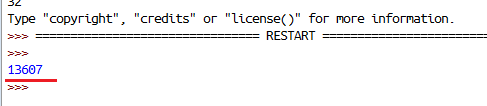
new_inner01_h = globalcontent.find('<dt>a href=')
print news_inner01_h运行结果:可以看到,查到第一篇文章的字符串位置在整个源代码中的第13607个字符,接下来继续查找该文章的url尾部
代码:
import urllib
import string
#定义要抓取的页面
url = 'http://www.freebuf.com/articles'
#读取要抓取的页面
globalcontent = urllib.urlopen(url).read()
#捕捉文章列表
#这里在源码中查询"<dt><a href="这个字符串
new_inner01_h = globalcontent.find('<dt>a href=')
print news_inner01_h
#这里在源码中查询".html"这个字符串
new_inner01_l = globalcontent.find('.html')
print news_inner01_l运行结果:可以看到,url的结尾位置在第13661个字符上,那么接下来就可以把我想要的真实的文章url地址提取出来

代码:
import urllib
import string
#定义要抓取的页面
url = 'http://www.freebuf.com/articles'
#读取要抓取的页面
globalcontent = urllib.urlopen(url).read()
#捕捉文章列表
#这里在源码中查询"<dt><a href="这个字符串
new_inner01_h = globalcontent.find('<dt>a href=')
print news_inner01_h
#这里在源码中查询".html"这个字符串
new_inner01_l = globalcontent.find('.html')
print news_inner01_l
#这里对文档流进行分片,从查找到的第一篇文章的头部开始,到尾部结束给提取出来
#注意,头部我进行加13,尾部加5,那是因为查找到的指针处于该字符串的开始,如果不做处理那么结果就不是我想要的数据,所以要把指针向前移动
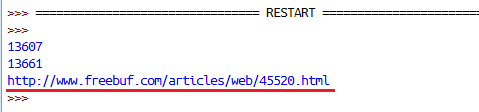
news_inner01 = globalcontent[news_inner01_h+13:news_inner01_l+5]
print news_inner01运行结果:
如下图所示,到这里成功提取出了第一篇文章的url地址,那么后面的事情就好办了,我只需要循环对文档流进行如上操作,得出每一篇文章的地址即可,最后对每一篇文章做处理就行了
以下代码之所以进行异常捕捉,是我发现如果不对异常进行处理,那么,url返回值会多一个空白行,导致不能对抓取到的文章进行处理,所以这里进行异常捕捉,忽略捕捉到的异常
至 此,一个最基本功能的网络爬虫就实现了,当然还可以自己加更多功能,我这里因为我只是写来玩玩,毕竟很晚了,太困了,实在不想写了,想睡觉了,所以就写这 么多了,这里只是一个思路而已,还可以添加很多功能,我这里没有用到面向对象的知识,如果利用面向对象的知识,那么这个爬虫还可以更完善。
import urllib
import string
url = 'http://www.freebuf.com/articles'
globalcontent = urllib.urlopen(url).read()
news_start = globlacontent
cout = 1
while count <= 16:
try:
news_inner_head = news_start.find('<dt><a href=')
news_inner_tail = news_start.find('.html')
news_inner_url = new_start[news_inner_head+13:news_inner_tail+5]
print news_inner_url
news_start = news_start[news_inner_tail+5:]
filename = news_inner_url[-10:]
urllib.urlretrieve(news_inner_url,filename)
count += 1
except:
print 'Download Success!'
finally:
if count == 16:
break好了,不多说 了,上两张效果图,睡觉了!
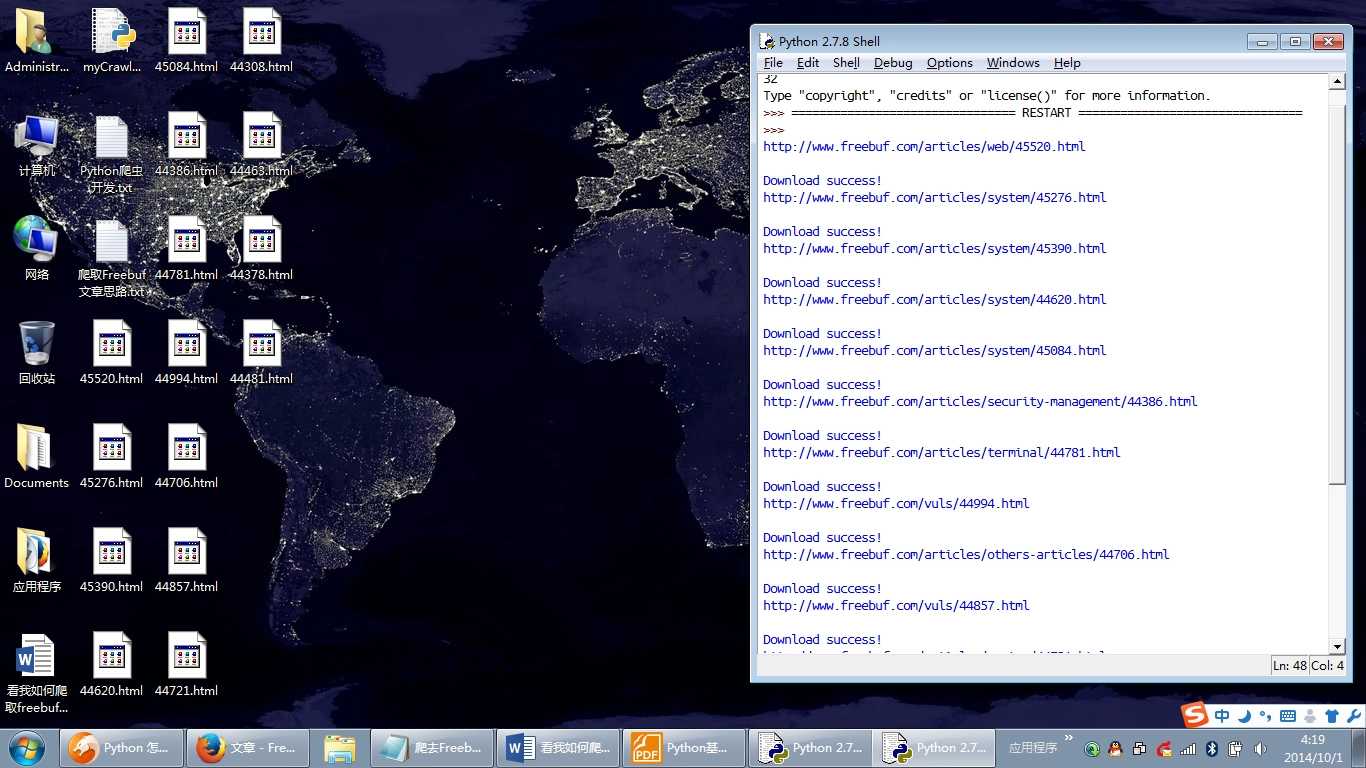

【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫的更多相关文章
- 【神经网络与深度学习】【python开发】caffe-windows使能python接口使用draw_net.py绘制网络结构图过程
[神经网络与深度学习][python开发]caffe-windows使能python接口使用draw_net.py绘制网络结构图过程 标签:[神经网络与深度学习] [python开发] 主要是想用py ...
- 【神经网络与深度学习】【Python开发】Caffe配置 windows下怎么安装protobuf for python
首先从google上下载protobuf-2.5.0.zip和protoc-2.5.0-win32.zip,然后把protoc-2.5.0-win32.zip里的protoc.exe放到protobu ...
- 【神经网络与深度学习】【Matlab开发】caffe-windows使能Matlab2015b接口
[神经网络与深度学习][Matlab开发]caffe-windows使能Matlab2015b接口 标签:[神经网络与深度学习] [Matlab开发] 主要是想全部来一次,所以使能了Matlab的接口 ...
- MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网络训练实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前两篇文章MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网 ...
- 【神经网络与深度学习】【CUDA开发】caffe-windows win32下的编译尝试
[神经网络与深度学习][CUDA开发]caffe-windows win32下的编译尝试 标签:[神经网络与深度学习] [CUDA开发] 主要是在开发Qt的应用程序时,需要的是有一个使用的库文件也只是 ...
- 【神经网络与深度学习】【Qt开发】【VS开发】从caffe-windows-visual studio2013到Qt5.7使用caffemodel进行分类的移植过程
[神经网络与深度学习][CUDA开发][VS开发]Caffe+VS2013+CUDA7.5+cuDNN配置成功后的第一次训练过程记录<二> 标签:[神经网络与深度学习] [CUDA开发] ...
- 【神经网络与深度学习】【CUDA开发】【VS开发】Caffe+VS2013+CUDA7.5+cuDNN配置过程说明
[神经网络与深度学习][CUDA开发][VS开发]Caffe+VS2013+CUDA7.5+cuDNN配置过程说明 标签:[Qt开发] 说明:这个工具在Windows上的配置真的是让我纠结万分,大部分 ...
- Python机器学习库和深度学习库总结
我们在Github上的贡献者和提交者之中检查了用Python语言进行机器学习的开源项目,并挑选出最受欢迎和最活跃的项目. 1. Scikit-learn(重点推荐) www.github.com/sc ...
- 【神经网络与深度学习】chainer边运行边定义的方法使构建深度学习网络变的灵活简单
Chainer是一个专门为高效研究和开发深度学习算法而设计的开源框架. 这篇博文会通过一些例子简要地介绍一下Chainer,同时把它与其他一些框架做比较,比如Caffe.Theano.Torch和Te ...
随机推荐
- python进阶ing——创建第一个Tornado应用
python进阶ing——创建第一个Tornado应用 分类: Python2013-06-02 23:02 1725人阅读 评论(2) 收藏 举报 pythonTornado 每天在群里跟很多群友讨 ...
- Newsgroups数据集研究
1.数据集介绍 20newsgroups数据集是用于文本分类.文本挖据和信息检索研究的国际标准数据集之一. 数据集收集了大约20,000左右的新闻组文档,均匀分为20个不同主题的新闻组集合. 一些新闻 ...
- Python中self的用法详解,或者总是提示:TypeError: add() missing 1 required positional argument: 'self'的问题解决
https://blog.csdn.net/songlh1234/article/details/83587086 下面总结一下self的用法详解,大家可以访问,可以针对平时踩过的坑更深入的了解下. ...
- Python入门提示
Python入门提示——行与缩进,常量定义 在初学Python时,除了学习一些标准的语法外,会遇到一些其他困难,列举如下. 一.python http://www.xuanhe.net/的行与缩进 P ...
- OpenCV笔记(5)(定位票据并规范化、调库扫描文本)
一.定位和变换票据 定位照片中的不规范票据或矩形文本,并将其变换为正规矩形,以供OCR识别. # -*- coding:utf-8 -*- __author__ = 'Leo.Z' import cv ...
- mysql报错:Cause: java.sql.SQLException: sql injection violation, syntax error: ERROR. pos 39, line 2, column 24, token CLOSE
因为close是mysql关键字 -- ::, DEBUG (BaseJdbcLogger.java:)- ==> Preparing: , -- ::, INFO (XmlBeanDefini ...
- Java内存区域与Java内存模型
Java内存区域 Java虚拟机在运行程序时会把其自动管理的内存划分为以上几个区域,每个区域都有其用途以及创建销毁的时机,其中蓝色部分代表的是所有线程共享的数据区域,而绿色部分代表的是每个线程的私有 ...
- Word:表格前添加新行 + 删除表格后的空行
本文适用于Word 2007 + Windows 7,造冰箱的大熊猫@cnblogs 2018/8/3 近日新学(百度到)两条新Word操作,记录下来以备查询 1.在表格前添加新行 场景:有没有遇到过 ...
- Travis CI Could not find or load main class org.gradle.wrapper.GradleWrapperMain 错误
问题 在 Travis CI 编译的时候出现 Error: Could not find or load main class org.gradle.wrapper.GradleWrapperMain ...
- select和FD_SET等
转自:http://blog.csdn.net/cstarbl/article/details/7645298 select函数用于在非阻塞中,当一个套接字或一组套接字有信号时通知你,系统提供sele ...