Solution for automatic update of Chinese word segmentation full-text index in NEO4J
<p></p>
Solution for automatic update of Chinese word segmentation full-text index in NEO4J
- 1. Sample data
- 2. Differences between English and Chinese Full-Text Indexes
- 3. APOC has its own English full-text indexing process (indexing can be updated automatically)
- 4. Custom Chinese word segmentation full-text index plug-in (unsuccessful automatic index update)
- V. Label Cross-search
- 6. Custom Chinese Word Segmentation Plugin (Failed to Update Indexes Independently of Nodes)
- 1. Add Full-Text Index
- 2. Add Nodes and Attributes and Update Full-Text Index
- 3. Add 2 new nodes or updated attributes to the index
- 4. Retrieval
- 7. Resolve Transaction Submission Timeout
Failed to implement automatic updates using the NEO4J INDEX API, converting a way of thinking to solve this problem (synchronizing updates to the corresponding full-text index when updating a node or creating a new one.)
1. Sample data
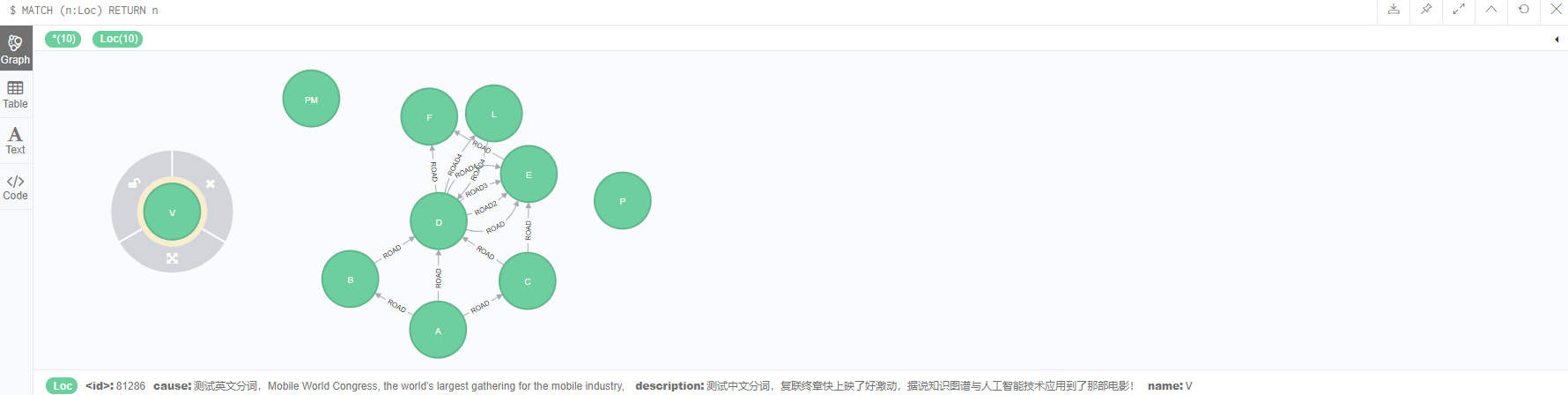
2. Differences between English and Chinese Full-Text Indexes
1. Create NEO4J default index
CALL apoc.index.addAllNodes('Loc', {Loc:["description","cause","year"]})
// The following retrieval was unsuccessful:
CALL apoc.index.search('Loc', 'Loc.description:Chinese~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:Chinese*') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:test~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:Test Chinese~') YIELD node RETURN node
2. Delete Index
CALL apoc.index.remove('Loc')
3. Create an index that supports Chinese words
CALL zdr.index.addChineseFulltextIndex('Loc', ["description","cause","year"], 'Loc') YIELD message RETURN message
// The following retrieval was successful:
CALL apoc.index.search('Loc', 'description:Chinese~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'description:Chinese*') YIELD node RETURN node
CALL apoc.index.search('Loc', 'description:test~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'description:Test Chinese~') YIELD node RETURN node
3. APOC has its own English full-text indexing process (indexing can be updated automatically)
1. Add Full-Text Index
CALL apoc.index.addAllNodes('Loc', {Loc:["description","cause","year"]},{autoUpdate:true})
2. New Nodes and Attributes
CREATE (n:Loc {name:'V'}) SET n.description='Testing Chinese word segmentation, the final chapter of the duplicate show was very exciting. It is said that knowledge mapping and artificial intelligence technology were applied to that movie!',n.cause='Test the English word breaker, Mobile World Congress, the world's largest gathering for the mobile industry, ' RETURN n
3. Retrieval
Indexes can be updated automatically, but they are not friendly to Chinese retrieval, such as the following tests:
// Retrieval failed:
CALL apoc.index.search('Loc', 'Loc.cause:Test English word breakers~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:Test Chinese word segmentation~') YIELD node RETURN node
// Retrieved successfully:
CALL apoc.index.search('Loc', 'Loc.cause:Test English word breakers*') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:Test Chinese word segmentation*') YIELD node RETURN node
4. Custom Chinese word segmentation full-text index plug-in (unsuccessful automatic index update)
The addChineseFulltextAutoIndex process succeeds in creating a full-text index to add a full-text indexing process that supports Chinese, but automatic updates are not supported for updating new attributes of nodes.
1. Add Full-Text Index
CALL zdr.index.addChineseFulltextAutoIndex('IKAnalyzer',["description","cause","year"],'Loc',{autoUpdate:'true'}) YIELD message RETURN message
2. New Nodes and Attributes
CREATE (n:Loc {name:'V'}) SET n.description='Testing Chinese word segmentation, the final chapter of the duplicate show was very exciting. It is said that knowledge mapping and artificial intelligence technology were applied to that movie!',n.cause='Test the English word breaker, Mobile World Congress, the world's largest gathering for the mobile industry, ' RETURN n
3. Retrieval
After adding a full-text search, you can retrieve:
CALL zdr.index.chineseFulltextIndexSearch('IKAnalyzer', 'description:Acridyl Aminomethane Sulfonymethoxyaniline', 100) YIELD node RETURN node
Re-index before retrieving:
CALL zdr.index.chineseFulltextIndexSearch('IKAnalyzer', 'description:test~', 100) YIELD node RETURN node
V. Label Cross-search
Add ChineseFulltextAutoIndex/addChineseFulltextIndex supports multiple tags while retrieving, using the same index name when building the index.
Tag: Loc
CALL zdr.index.addChineseFulltextAutoIndex('Loc',["description","cause","name"],'Loc',{autoUpdate:'true'}) YIELD message RETURN message
Tag: LocProvince'
CALL zdr.index.addChineseFulltextAutoIndex('Loc',["description","cause","name"],'LocProvince',{autoUpdate:'true'}) YIELD message RETURN message
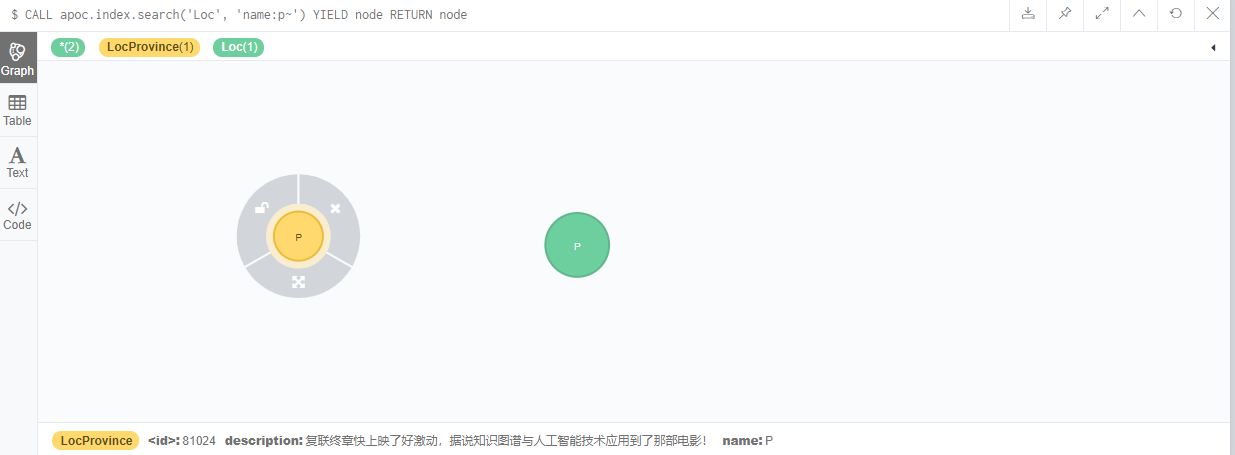
Retrieve node:
CALL apoc.index.search('Loc', 'name:p~') YIELD node RETURN node
6. Custom Chinese Word Segmentation Plugin (Failed to Update Indexes Independently of Nodes)
To support single-node index updates, develop the following process.(The automatic update scheme described in the third section fails, and updates to the corresponding full-text index synchronously when updating or creating a new node.)
1. Add Full-Text Index
CALL apoc.index.remove('Loc')
CALL zdr.index.addChineseFulltextIndex('Loc',["description","cause","year"],'Loc') YIELD message RETURN message
2. Add Nodes and Attributes and Update Full-Text Index
CREATE (n:Loc {name:'V'}) SET n.description='Testing Chinese word segmentation, the final chapter of the duplicate show was very exciting. It is said that knowledge mapping and artificial intelligence technology were applied to that movie!',n.cause='Test the English word breaker, Mobile World Congress, the world's largest gathering for the mobile industry, ' RETURN n
3. Add 2 new nodes or updated attributes to the index
MATCH (n) WHERE n.name='V' WITH n CALL zdr.index.addNodeChineseFulltextIndex(n, ['description']) RETURN *
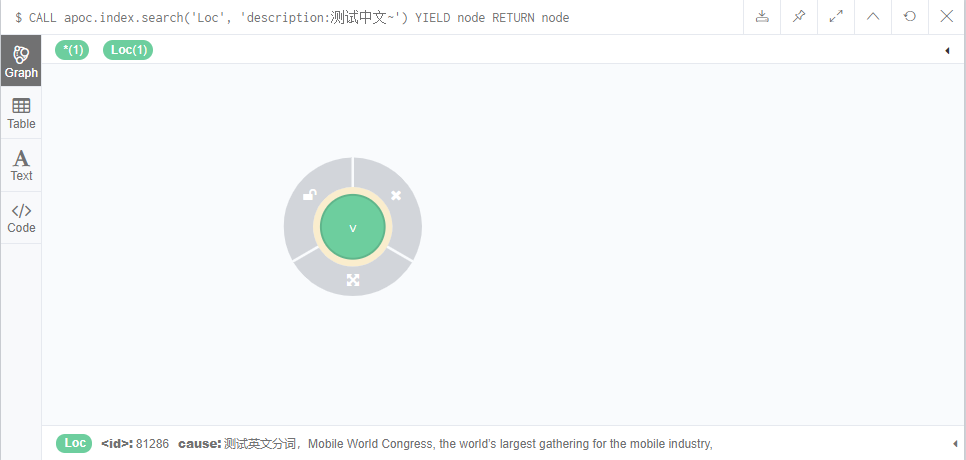
4. Retrieval
CALL zdr.index.chineseFulltextIndexSearch('Loc', 'description:Test Chinese~') YIELD node RETURN node
7. Resolve Transaction Submission Timeout
If the transaction commit timeout setting is configured, Cancel when building the index.
#********************************************************************
### Neo4j transcation timeout
###******************************************************************
#dbms.transaction.timeout=180s
Use a background script to execute the indexer:
# index.sh
#!/usr/bin/env bash
nohup /neo4j-community-3.4.9/bin/neo4j-shell -file build.cql >>indexGraph.log 2>&1 &
// build.cql
CALL zdr.index.addChineseFulltextIndex('IKAnalyzer', ['description','fullname','name','lnkurl'], 'LinkedinID') YIELD message RETURN message;
All of the above references to the NEO4J custom process
原文地址:https://programmer.ink/think/5cd0160be03d2.html
Solution for automatic update of Chinese word segmentation full-text index in NEO4J的更多相关文章
- 长短时间记忆的中文分词 (LSTM for Chinese Word Segmentation)
翻译学长的一片论文:Long Short-Term Memory Neural Networks for Chinese Word Segmentation 传统的neural Model for C ...
- zpar使用方法之Chinese Word Segmentation
第一步在这里: http://people.sutd.edu.sg/~yue_zhang/doc/doc/qs.html 你可以找到这句话, 所以在命令行中分别敲入 make zpar make zp ...
- 论文阅读及复现 | Effective Neural Solution for Multi-Criteria Word Segmentation
主要思想 这篇文章主要是利用多个标准进行中文分词,和之前复旦的那篇文章比,它的方法更简洁,不需要复杂的结构,但比之前的方法更有效. 方法 堆叠的LSTM,最上层是CRF. 最底层是字符集的Bi-LST ...
- The solution for apt-get update Err 404
最近在ubuntu 12.10上执行sudo apt-get update 命令后出现了如下错误: Ign http://extras.ubuntu.com natty/main Translatio ...
- Chinese word segment based on character representation learning 论文笔记
论文名和编号 摘要/引言 相关背景和工作 论文方法/模型 实验(数据集)及 分析(一些具体数据) 未来工作/不足 是否有源码 问题 原因 解决思路 优势 基于表示学习的中文分词 编号:1001-908 ...
- LIST OF NOSQL DATABASES [currently 150]
http://nosql-database.org Core NoSQL Systems: [Mostly originated out of a Web 2.0 need] Wide Column ...
- Pyhton开源框架(加强版)
info:Djangourl:https://www.oschina.net/p/djangodetail: Django 是 Python 编程语言驱动的一个开源模型-视图-控制器(MVC)风格的 ...
- Python开源框架
info:更多Django信息url:https://www.oschina.net/p/djangodetail: Django 是 Python 编程语言驱动的一个开源模型-视图-控制器(MVC) ...
- 【DeepLearning】一些资料
记录下,有空研究. http://nlp.stanford.edu/projects/DeepLearningInNaturalLanguageProcessing.shtml http://nlp. ...
随机推荐
- ZeroMQ+QT 字符串收发
结合 Zeromq API函数 与 Qt 字符串QString QByteArray 实现字串收发: 发送端: zmq_msg_t msg; QString strT = “ABC汉字123”: QB ...
- MySql中根据一列状态值查询状态的个数
最近搞报表的项目,要写数据库sql语句,根据状态值查询状态的个数,这个开始难为到我了,不过已经有解决办法了. 在数据库表中有一个字段是状态(zt),这里面有1-7这7个状态,现在查询每个状态的数量,并 ...
- C++入门经典-例4.4-循环嵌套之求n的阶乘
1:代码如下: // 4.4.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> using ...
- 使用hash拆分文件
package readImgUrl; import java.io.BufferedInputStream; import java.io.BufferedReader; import java.i ...
- JPA访问数据库的几种方式
JPA访问数据库的几种方式 本文为原创,转载请注明出处:https://www.cnblogs.com/supiaopiao/p/10901793.html 1. Repository 1.1. 通过 ...
- ffmpeg 视频过度滤镜 gltransition
ffmpeg 视频过度滤镜 gltransition 上次随笔中提到的 ffmpeg-concat 可以处理视频过度,但是缺点是临时文件超大. 经过查找 ffmpeg 还有 gltransition ...
- Idea创建项目后,提交项目到码云的问题
1.创建git仓库:vcs->import int version control->Create git repository 2.在项目头点击右键->git->add 3. ...
- C#学习笔记一(概念,对象与类型,继承)
一.基础 1.CLR为公共语言运行库,类似于JVM 2..NET Framwork是一个独立发布的程序包,其包含了CLR,类库及相关的语言编辑器等工具,类似于JDK,除了C#,还有其他几种语言在CLR ...
- js中dom选择器
document,getElementById("demo"); //通过id查询节点 . document.getElementsByTagName("div&q ...
- GitLab使用小结
对Git和GitLab的使用作一个小结 GitLab基于Git,可以作为团队开发项目使用,因此通常会有一个主分支master和其他分支,因此项目成员中任意一人不能随意push到主分支中,容易引起混乱: ...