KMP算法具体解释
这几天学习kmp算法,解决字符串的匹配问题。開始的时候都是用到BF算法,(BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比較S的第二个字符和
T的第二个字符;若不相等,则比較S的第二个字符和T的第一个字符,依次比較下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。
)尽管也能解决一些问题。可是这是常规思路,在内存大,数据量小。时间长的情况下。还能解决一些问题,可是假设遇到一些限制时间和内存的字符串问题,肯定会超时,这是我们就想到了kmp算法,(KMP算法是一种改进的字符串匹配算法,由D.E.Knuth与V.R.Pratt和J.H.Morris同一时候发现。因此人们称它为克努特--莫里斯--普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量降低模式串与主串的匹配次数以达到高速匹配的目的。
详细实现就是实现一个next()函数,函数本身包括了模式串的局部匹配信息。)kmp算法的难点是kmp中的next数组的了解和求法。上网查了非常多资料。发现參差不齐,研究了非常久,才认为豁然开朗,,借鉴网上资源以及自己的了解。现总结例如以下,存在非常多不足之处。希望大家能批评指正!!
一、模拟字符串比較步骤例如以下:
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符。进行比較。由于B与A不匹配,所以搜索词后移一位。
2.

由于B与A不匹配,搜索词再往后移。
3.

就这样。直到字符串有一个字符,与搜索词的第一个字符同样为止。
4.

接着比較字符串和搜索词的下一个字符,还是同样。
5.

直到字符串有一个字符,与搜索词相应的字符不同样为止。
6.

这时。最自然的反应是。将搜索词整个后移一位,再从头逐个比較。这样做尽管可行,可是效率非常差,由于你要把"搜索位置"移到已经比較过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你事实上知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比較过的位置。继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?能够针对搜索词。算出一张《部分匹配表》(Partial Match Table)。
这张表是怎样产生的。后面再介绍。这里仅仅要会用就能够了。
9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知。最后一个匹配字符B相应的"部分匹配值"为2。因此依照以下的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 相应的部分匹配值
由于 6 - 2 等于4。所以将搜索词向后移动4位。
10.

由于空格与C不匹配,搜索词还要继续往后移。
这时,已匹配的字符数为2("AB")。相应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2。于是将搜索词向后移2位。
11.

由于空格与A不匹配,继续后移一位。
12.

逐位比較。直到发现C与D不匹配。于是。移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比較。直到搜索词的最后一位,发现全然匹配,于是搜索完毕。假设还要继续搜索(即找出所有匹配)。移动位数 = 7 - 0,再将搜索词向后移动7位。这里就不再反复了。
14.

以下介绍《部分匹配表》是怎样产生的。
首先,要了解两个概念:"前缀"和"后缀"。
"前缀"指除了最后一个字符以外,一个字符串的所有头部组合;"后缀"指除了第一个字符以外,一个字符串的所有尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共同拥有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共同拥有元素的长度为0。
- "AB"的前缀为[A],后缀为[B],共同拥有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C]。共同拥有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC]。后缀为[BCD, CD, D]。共同拥有元素的长度为0。
- "ABCDA"的前缀为[A, AB, ABC, ABCD]。后缀为[BCDA, CDA, DA, A],共同拥有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA]。后缀为[BCDAB, CDAB, DAB, AB, B],共同拥有元素为"AB"。长度为2。
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB]。后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共同拥有元素的长度为0。
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有反复。比方,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候。第一个"AB"向后移动4位(字符串长度-部分匹配值),就能够来到第二个"AB"的位置。
二、next数组实现的代码:
代码:
<span style="font-size:18px;">void makeNext(const char P[],int next[])
{
int q,k;//q:模版字符串下标;k:最大前后缀长度
int m = strlen(P);//模版字符串长度
next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0
for (q = 1,k = 0; q < m; ++q)//for循环,从第二个字符開始,依次计算每个字符相应的next值
{
while(k > 0 && P[q] != P[k])//递归的求出P[0]···P[q]的最大的同样的前后缀长度k
k = next[k-1]; //不理解没关系看以下的分析,这个while循环是整段代码的精髓所在,确实不好理解
if (P[q] == P[k])//假设相等,那么最大同样前后缀长度加1
{
k++;
}
next[q] = k;
}
}</span>
如今我着重解说一下while循环所做的工作:
- 已知前一步计算时最大同样的前后缀长度为k(k>0)。即P[0]···P[k-1];
- 此时比較第k项P[k]与P[q],如图1所看到的
- 假设P[K]等于P[q],那么非常easy跳出while循环;
- 关键!关键有木有!
关键假设不等呢???那么我们应该利用已经得到的next[0]···next[k-1]来求P[0]···P[k-1]这个子串中最大同样前后缀,可能有同学要问了——为什么要求P[0]···P[k-1]的最大同样前后缀呢???是啊!
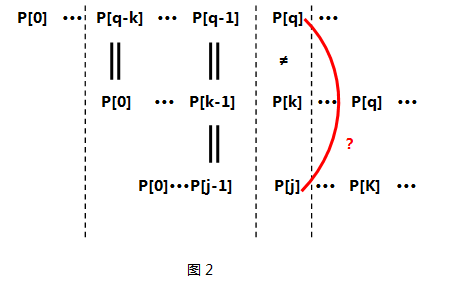
为什么呢? 原因在于P[k]已经和P[q]失配了,并且P[q-k]
··· P[q-1]又与P[0] ···P[k-1]相同,看来P[0]···P[k-1]这么长的子串是用不了了。那么我要找个相同也是P[0]打头、P[k-1]结尾的子串即P[0]···P[j-1](j==next[k-1]),看看它的下一项P[j]能否和P[q]匹配。如图2所看到的

三、next数组的优化代码:
<span style="font-size:18px;">void get_next()
{
int i=0,j=-1;
next[0]=-1;
while(i<len2)
{
if(j==-1||s2[i]==s2[j])
{
i++;
j++;
next[i]=j;
}
else
{
j=next[j];
}
}
} </span>
附件:kmp算法完整代码:
<span style="font-size:18px;">#include<stdio.h>
#include<string.h>
#define N 100005
char s[2*N];
char s1[N];
char s2[N];
int next[N];
int len1,len2,len;
void get_next()
{
int i=0,j=-1;
next[0]=-1;
while(i<len2)
{
if(j==-1||s2[i]==s2[j])
{
i++;
j++;
next[i]=j;
}
else
{
j=next[j];
}
}
}
void KMP()
{
int i=0;
int j=0;
get_next();
while(i<len&&j<len2)
{
if(j==-1||s[i]==s2[j])
{
i++;
j++;
}
else
{
j=next[j];
}
}
if(j==len2)
{
printf("yes\n");
return ;
}
else
{
printf("no\n");
return ;
}
}
int main(void)
{
while(scanf("%s%s",s1,s2)!=EOF)
{
len1=strlen(s1);
len2=strlen(s2);
if(len1<len2)
{
printf("no\n");
continue;
}
strcpy(s,s1);
strcat(s,s1);
len=2*len1;
memset(next,-1,sizeof(next));
KMP();
}
return 0;
}</span>
KMP算法具体解释的更多相关文章
- KMP算法具体解释(贴链接)
---------------------------------------------------------------------------------------------------- ...
- KMP算法具体解释(转)
作者:July. 出处:http://blog.csdn.net/v_JULY_v/. 引记 此前一天,一位MS的朋友邀我一起去与他讨论高速排序,红黑树,字典树,B树.后缀树,包含KMP算法,只有在解 ...
- KMP 算法简单解释
讲KMP算法,离不开BF,实际上,KMP就是BF升级版,主要流程和BF一样 不同是在匹配失败时能利用子串的特征减少回溯,利用根据子串特征生成的Next数组来减少 <( ̄︶ ̄)↗[GO!] ...
- 字符串匹配KMP算法的C语言实现
字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD" ...
- 字符串匹配(KMP 算法 含代码)
主要是针对字符串的匹配算法进行解说 有关字符串的基本知识 传统的串匹配法 模式匹配的一种改进算法KMP算法 网上一比較易懂的解说 小样例 1计算next 2计算nextval 代码 有关字符串的基本知 ...
- (收藏)KMP算法的前缀next数组最通俗的解释
我们在一个母字符串中查找一个子字符串有很多方法.KMP是一种最常见的改进算法,它可以在匹配过程中失配的情况下,有效地多往后面跳几个字符,加快匹配速度. 当然我们可以看到这个算法针对的是子串有对称属性, ...
- KMP算法的next[]数组通俗解释
原文:https://blog.csdn.net/yearn520/article/details/6729426 我们在一个母字符串中查找一个子字符串有很多方法.KMP是一种最常见的改进算法,它可以 ...
- KMP算法的详细解释及实现
这是我自己学习算法时有关KMP的学习笔记,代码注释的十分的详细,分享给大家,希望对大家有所帮助 在介绍KMP算法之前, 先来介绍一下朴素模式匹配算法: 朴素模式匹配算法: 假设要从主串S=”goodg ...
- kmp算法中的nextval实例解释
求nextval数组值有两种方法,一种是不依赖next数组值直接用观察法求得,一种方法是根据next数组值进行推理,两种方法均可使用,视更喜欢哪种方法而定. 本文主要分析nextval数组值的第二种方 ...
随机推荐
- 使用 Go-Ethereum 1.7.2搭建以太坊私有链
目录 [toc] 1.什么是Ethereum(以太坊) 以太坊(Ethereum)并不是一个机构,而是一款能够在区块链上实现智能合约.开源的底层系统,以太坊从诞生到2017年5月,短短3年半时间,全球 ...
- 8. 理解ZooKeeper的内部工作原理
到目前为止,我们已经讨论了ZooKeeper服务的基础知识,并详细了解了数据模型及其属性. 我们也熟悉了ZooKeeper 监视(watch)的概念,监视就是在ZooKeeper命名空间中的znode ...
- Duilib XML嵌套
duilib使用嵌套xml可以简化代码的书写,有利于模块化的页面布局分解,duilib库的xml嵌套主要有两种方式 方式一.以创建控件的方式嵌套xml 在CreateControl(LPCTSTR p ...
- [转载] Mahout
转载自http://hadoop.readthedocs.org/en/latest/Hadoop-Mahout.html# Mahout 12.1 简介 Mahout为推荐引擎提供了一些可扩展的机器 ...
- [O]SQL SERVER下有序GUID和无序GUID作为主键&聚集索引的性能表现
背景 前段时间学习<Microsoft SQL Server 2008技术内幕:T-SQL查询>时,看到里面关于无序GUID作为主键与聚集索引的建议,无序GUID作为主键以及作为聚集索引 ...
- Caused by: org.xml.sax.SAXParseException; lineNumber: 4; columnNumber: 49; 前言中不允许有内容。
今天刚开始学习mybatis时,自己去尝试使用mybatis链接数据库,操作数据局时,报了一个下面的错误 Caused by: org.xml.sax.SAXParseException; lineN ...
- shiro入门示例
一.pom引入maven依赖 <dependencies> <dependency> <groupId>junit</groupId> <arti ...
- 极光推送_总结_01_Java实现极光推送
一.代码实现 1.配置类—Env.java package com.ray.jpush.config; /**@desc : 极光推送接入配置 * * @author: shirayner * @da ...
- 理解OC“属性”这一概念
1.定义一个属性,编译器会自动编写相关的存取方法和实例变量,如果不想使用系统默认的实例变量,可以使用@synthesize(合成)语法来指实例变量的名字,如果不想编译器自动合成存取方法,则可以自己实现 ...
- JavaWeb框架_Struts2_(六)----->Struts2的输入校验
1. 输入校验章节目录 输入校验概述 客户端校验 服务器端校验 手动编程校验 重写validate方法 重写validateXxx()方法 输入校验流程 校验框架校验 Struts2 内置的校验器 常 ...