hadoop集群篇--从0到1搭建hadoop集群
一。前述
本来有套好好的集群,可是不知道为什么虚拟机镜像文件损坏,结果导致集群不能用。所以不得不重新搭套集群,借此机会顺便再重新搭套吧,顺便提醒一句大家,自己虚拟机的集群一定要及时做好快照,最好装完每个东西后记得拍摄快照。要不搞工具真的很浪费时间,时间一定要用在刀刃上。废话不多说,开始准备环境搭建,本集群搭建完全基于企业思想,所以生产集群亦可以参照此搭建。
二。集群规划
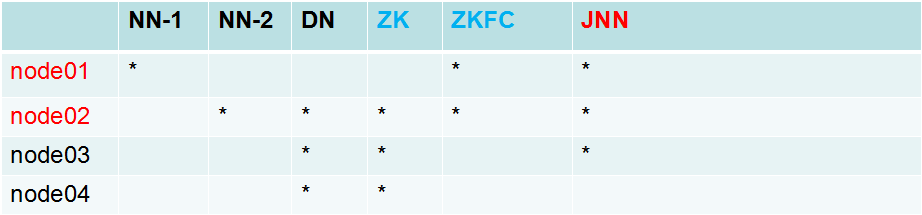
三。配置
1.配置集群节点之间免密操作。
因为在node01(namenode)节点要启动datanode节点,所以需要配置node01到三台datanode节点的免密操作
因为两个namenode之间需要互相切换降低对方的级别所以node01,node02之间需要进行免密操作。
具体步骤如下:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp id_dsa.pub root@node04:`pwd`/node01.pub
cat node01.pub >> ~/.ssh/authorized_keys
2.上传hadoop安装包到某一节点上,进行配置
假设配置在此目录下

第一步:配置hadoop-env.sh
使用命令echo $JAVA_HOME 确定jd目录。

配置java环境。
export JAVA_HOME=/usr/java/jdk1.7.0_67
第二步:配置hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>//配置集群的别名,所以当企业中多套集群时,可以使用此别名分开
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>//配置两个namenode的逻辑名称
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>//配置两个namenode的真正物理节点和rpc通信端口
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>//配置两个namenode的真正物理节点rpc通信端口
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>//配置两个namenode的真正物理节点http通信端口
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>//配置两个namenode的真正物理节点http通信端口
<value>node02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>//配置三个journalnode的物理地址
</property>
<property>
<name>dfs.journalnode.edits.dir</name>//配置journalnode共享edits的目录
<value>/var/sxt/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>//配置zkfc实现的真正类
</property>
<property>
<name>dfs.ha.fencing.methods</name>//配置zkfc隔离机制
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>//配置zkfc切换对方namenode时所使用的方式
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>/配置是否自动开启zkfc切换
<value>true</value>
</property>
第三步:配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>//配置集群的别名
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>//配置和zookeep通信地址和端口
</property>
<property>
<name>hadoop.tmp.dir</name>//配置hadoop元数据的存放目录
<value>/var/sxt/hadoop-2.6/ha</value>
</property>
第四步:配置slaves
即datanode节点
对应datanode节点的host或者ip
第五步:分发配置到其他节点相同目录
scp -r hadoop-2.6.5 root@node04:`pwd`
第六步:配置zookeeeer集群
同样上传到某一节点 然后配置
1.cp zoo_sample.cfg zoo.cfg先改名 zookeeper集群识别zoo.cfg文件
2.配置conf/zoo.cfg
dataDir=/var/sxt/zk
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
3.配置集群节点识别
mkdir -p /var/sxt/zk
echo 1 > myid //数字根据节点规划
4.配置全局环境变量
export ZOOKEEPER=/opt/soft/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER/bin
5.启动集群
分别启动三台节点,然后查看状态
zkServer.sh start
zkServer.sh statu


启动成功!!!
第七步:启动集群顺序(重要!!!)
1.先启动journalnode
hadoop-daemon.sh start journalnode
2.在两个namenode节点创建/var/sxt/hadoop-2.6/ha 即hadoop.tmp.dir的目录存放元数据(默认会创建,不过最好还是手工创建吧,并且里面一定是干净目录,无任何东西)
3.在其中一台namenode节点格式化
hdfs namenode -format
4.然后启动namenode!!!注意这个一定要先启动,然后再在另一台namenode同步,为了是让里面有数据
hadoop-daemon.sh start namenode
5.然后在另一台namenode节点执行同步hdfs namenode -bootstrapStandby
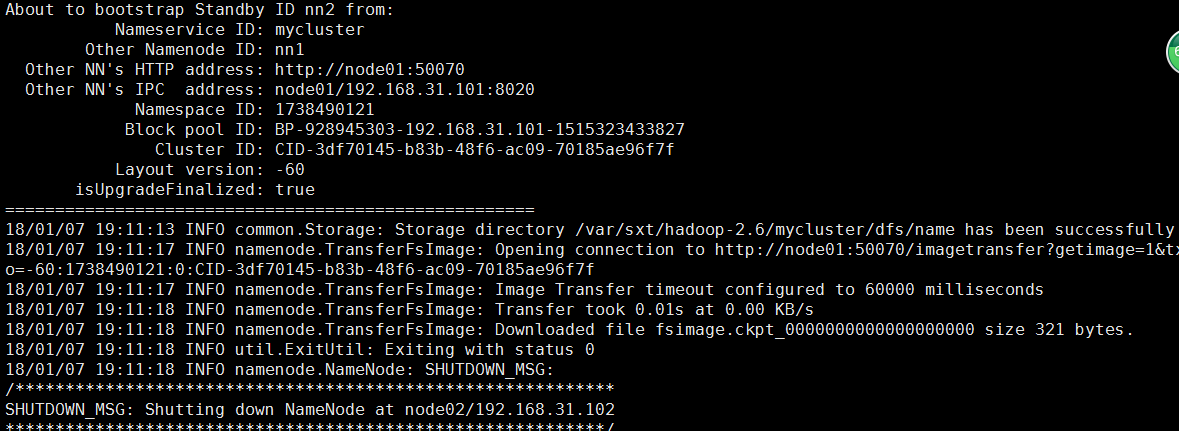
6.在主节点启动集群
start-dfs.sh
7.向zookeeper注册active节点
hdfs zkfc -formatZK
8.启动zkFC负责切换
hadoop-daemon.sh start zkfc
至此,集群启动成功启动成功!!

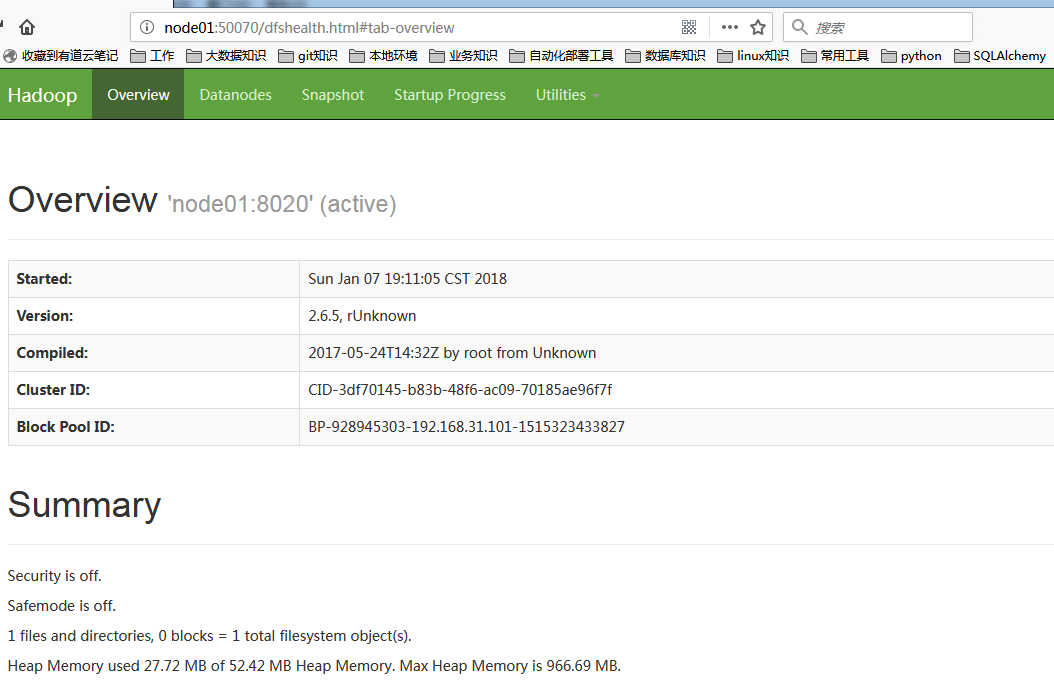
9.web-ui验证
10.下一次启动时,只需要先启动zookeper,然后在namenode的管理节点启动start-dfs.sh即可 !!!
最后,别忘拍摄快照哦!!
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

hadoop集群篇--从0到1搭建hadoop集群的更多相关文章
- 从0到1搭建spark集群---企业集群搭建
今天分享一篇从0到1搭建Spark集群的步骤,企业中大家亦可以参照次集群搭建自己的Spark集群. 一.下载Spark安装包 可以从官网下载,本集群选择的版本是spark-1.6.0-bin-hado ...
- 用C、python手写redis客户端,兼容redis集群 (-MOVED和-ASK),快速搭建redis集群
想没想过,自己写一个redis客户端,是不是很难呢? 其实,并不是特别难. 首先,要知道redis服务端用的通信协议,建议直接去官网看,博客啥的其实也是从官网摘抄的,或者从其他博客抄的(忽略). 协议 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- 从0到1搭建k8s集群系列1:安装虚拟机及docker
前言 本系列文章记录了本人学习k8s集群搭建的过程,从k8s基本组件的安装.到部署mysql服务到k8s集群.部署web项目到k8s集群以及安装可视化界面管理工具kuboard. 因为k8s的组件安装 ...
- QQ群技术:0成本创建2000人QQ群技巧
群人数,直接关系群权重;于排名,意义非凡;此法靠谱,笔者亲测. 就说这张图,这类关键词,要是没2000人群,不管你多流弊,你是做不上去滴. 于QQ群霸屏,笔者有太多的笔墨,各种排名技巧,阿力推推早前明 ...
- 在本机eclipse中创建maven项目,查看linux中hadoop下的文件、在本机搭建hadoop环境
注意 第一次建立maven项目时需要在联网情况下,因为他会自动下载一些东西,不然突然终止 需要手动删除断网前建立的文件 在eclipse里新建maven项目步骤 直接新建maven项目出了错 ...
- 3.环境搭建-Hadoop(CDH)集群搭建
目录 目录 实验环境 安装 Hadoop 配置文件 在另外两台虚拟机上搭建hadoop 启动hdfs集群 启动yarn集群 本文主要是在上节CentOS集群基础上搭建Hadoop集群. 实验环境 Ha ...
- 通过docker搭建ELK集群
单机ELK,另外两台服务器分别有一个elasticsearch节点,这样形成一个3节点的ES集群. 可以先尝试单独搭建es集群或单机ELK https://www.cnblogs.com/lz0925 ...
- 手把手教你搭建FastDFS集群(中)
手把手教你搭建FastDFS集群(中) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/u0 ...
随机推荐
- Struts2学习笔记整理(一)
最近在学习框架,很多人建议我直接学SSM,SSM看了一段时间后发现很多东西虽然可以用了,但是并不是很了解,所以我打算重新来过.从SSH开始学习,前面已经大致的学习了Hibernate,对于Hibern ...
- mvc 中Range中max和min值晚绑定
对于Attribute : Range(min,max)的min和max必须在用的时候给,但是需求有时须要把这两个值存db.动态取出的.这时就须要razor帮忙了: @Html.TextBoxFor( ...
- python模块 - re模块使用演示样例
http://blog.csdn.net/pipisorry/article/details/46619179 re模块匹配规则见:http://blog.csdn.net/pipisorry/art ...
- C++ Primer高速入门之三:几种常见的控制语句
语句总是顺序运行的:第一条语句运行完了接着是第二条,第三条等等.这是最简单的情况,为了更好的控制语句的运行.程序设计语言提供了多种控制结构支持更为复杂的语句运行.我们就来看看C++ 提供的控制方式. ...
- 迪杰斯特拉/dijkstra 算法模板(具体凝视)
#include <iostream> #include <malloc.h> #include <cstring> #include <stack> ...
- IIS中遇到无法预览的问题(HTTP 错误 401.3 - Unauthorized 因为 Web server上此资源的訪问控制列表(ACL)配置或加密设置,您无权查看此文件夹或页面。)
在IIS中 依次运行例如以下操作: 站点--编辑权限--共享(为了方便能够直接将分享对象设置为everyone)--安全(直接勾选 everyone )--应用--确定.
- 使用javascript正则表达式实现遍历html字符串
最近在尝试实现一个js模板引擎,其中涉及到使用js解析html字符串的功能.由于我实现的这个模板不止是要能替换参数输出html字符串,还要可以解析出每个dom元素的名称及参数啥的. 网上找到了一个叫做 ...
- Liunx的常用命令
常用指令 ls 显示文件或目录 -l 列出文件详细信息l(list) -a 列出当前目录下所有文件及目录,包括隐藏的a(all) mkdir 创建目录 -p 创建目录,若无父目录,则创建p(paren ...
- Tencent社会招聘scrapy爬虫 --- 已经解决
1.用 scrapy 新建一个 tencent 项目 2.在 items.py 中确定要爬去的内容 # -*- coding: utf- -*- # Define here the models fo ...
- java 单例模式学习笔记
1.单例模式概述 单例模式就是确保类在内存中只有一个对象,该实例必须自动创建,并且对外提供. 2.优缺点 优点:在系统内存中只存在一个对象,因此可以节约系统资源,对于一些需要频繁创建和销毁的对象单例模 ...