HBase命令终端测试
[root@CloudDeskTop ~]# su -l hadoop
[hadoop@CloudDeskTop ~]$ cd /software/hbase-1.2.6/bin/
[hadoop@CloudDeskTop bin]$ type hbase
hbase is /software/hbase-1.2.6/bin/hbase
[hadoop@CloudDeskTop bin]$ hbase shell

删除键:向左删除是ctrl+backspace、向右删除是backspace。
表空间:
hbase默认有两个表空间,它们是default和hbase
列出有多少个表空间
hbase(main):003:0> list_namespace
NAMESPACE
default (当未指定表空间时,数据存放在此处)
hbase(存放元数据的表空间)
查看default表空间下有哪些表:
>>list_namespace_tables 'default'
禁止创建表到hbase表空间下
>>list_namespace_tables 'hbase'
创建表空间:
>>create_namespace 'mmzs'
查看表空间信息:
>>describe_namespace 'mmzs'
删除表空间:
>>drop_namespace 'mmzs'
创建表tuser,该表中有两个列族baseinfo和extrainfo,baseinfo族中存储的每个值的最近时间版本数量为5,族参数 必须大写,如NAME和VERSION
>>create 'mmzs:tuser',{NAME=>'baseinfo',VERSIONS=>5},{NAME=>'extrainfo',VERSIONS=>3}
显示表结构:
>>describe 'mmzs:tuser'
#会先判断有没有,有就修改,没有就增加,修改是alter
修改表:修改表定义,修改列族baseinfo,将主版本数量改为3
>>alter 'mmzs:tuser',{NAME=>'baseinfo',VERSIONS=>3}
>>describe 'mmzs:tuser'
修改表:修改表定义,增加列族base
>>alter 'mmzs:tuser',{NAME=>'base',VERSIONS=>5}
>>describe 'mmzs:tuser'
修改表:修改表定义,删除列族baseinfo,低版本的HBase需要先disable而不是alter,再delete
>>alter 'mmzs:tuser',{NAME=>'baseinfo',METHOD=>'delete'}
>>describe 'mmzs:tuser'
判断是否存在某表:
>>exists 'mmzs:tuser'
#删除是drop
删除表:在删除表之前必须先disable禁用表然后再执行drop操作删除它
>>disable 'mmzs:tuser'
>>drop 'mmzs:tuser'
>>describe 'mmzs:tuser'
小结:大数据学习交流QQ群:217770236
创建表:
命名空间的DDL语法为:xxx_namespace 'namespace'
表的DDL操作语法:
>>xxx 'namespace:tablename',{NAME='yyyy',VERSION='number',METHOD='delete'}
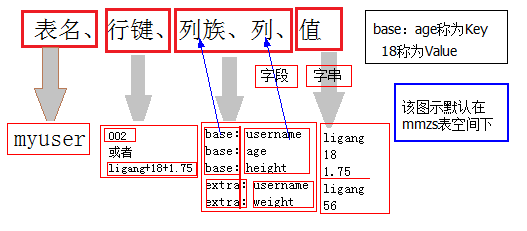
创建表:
>>create 'mmzs:tuser',{NAME=>'base',VERSIONS=>5},{NAME=>'extra',VERSIONS=>3}
增加键值对到表中:向mmzs表空间的tuser表中的base列族中添加name列,添加值为ligang
#'base:name'称为键
#'ligang'称为值
#修改和增加都是put,存在时是修改,不存在时是增加
>>put 'mmzs:tuser','001','base:name','ligang'
>>put 'mmzs:tuser','001','base:age',13
查询表中键对应的值:
>>get 'mmzs:tuser','001','base:name'
查询001行的所有键值对
>>get 'mmzs:tuser','001','base:name'
修改键值对:
>>put 'mmzs:tuser','001','base:name','zhangsan'
删除表中的键值对:
>>delete 'mmzs:tuser','001','base:name'
删除表中的所有数据并重置表的结构,实际上truncate属于DDL操作
>>truncate 'mmzs:tuser'
扫描表中的所有行的数据:
>>scan 'mmzs:tuser'
使用get_table预定义一个表对象的引用(ddl操作),
>>tuser=get_table 'mmzs:tuser'
>>tuser.scan
统计表中的行记录数:
>>count 'mmzs:tuser'
小结:
hbase表的增删改查操作语法:
>>copmmand 'namespace:tabname','rowkey','family:fieldkey','fieldvalue'
DDL数据检索与查询:
#get只能返回单行记录中的键值对
//Some examples:
hbase> get 'ns1:t1', 'r1'
hbase> get 't1', 'r1'
hbase> get 't1', 'r1', {TIMERANGE => [ts1, ts2]}
hbase> get 't1', 'r1', {COLUMN => 'c1'}
hbase> get 't1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMERANGE => [ts1, ts2], VERSIONS => 4}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1, VERSIONS => 4}
hbase> get 't1', 'r1', {FILTER => "ValueFilter(=, 'binary:abc')"}
hbase> get 't1', 'r1', 'c1'
hbase> get 't1', 'r1', 'c1', 'c2'
hbase> get 't1', 'r1', ['c1', 'c2']
hbase> get 't1', 'r1', {COLUMN => 'c1', ATTRIBUTES => {'mykey'=>'myvalue'}}
hbase> get 't1', 'r1', {COLUMN => 'c1', AUTHORIZATIONS => ['PRIVATE','SECRET']}
hbase> get 't1', 'r1', {CONSISTENCY => 'TIMELINE'}
hbase> get 't1', 'r1', {CONSISTENCY => 'TIMELINE', REGION_REPLICA_ID => 1}
根据行键检索对应记录中所有列族下的所有键值对:
根据行键和列族检索对应列族中的所有键值对:
根据行键、列族和字段键检索对应键值:
根据行键检索对应记录中所有列族下的所有键值对:
>>get 'mmzs:tuser','001','base'
>>get 'mmzs:tuser','001','base','extra'
>>get 'mmzs:tuser','001','base:name','base:age'
>>get 'mmzs:tuser','001',{COLUMN=>['base:name','base:age']}
>>get 'mmzs:tuser','001',{COLUMN=>['base:name','base:age'],VERSION=>3}
>>get 'mmzs:tuser','ligang+13','baseinfo','extra'
#匹配含liubei的value值
>>get 'mmzs:tuser','002',{FILTER=>"ValueFilter(=,'substring:liubei')"}
#匹配含name字段的字段值
>>get 'mmzs:tuser','002',{FILTER=>"QualifierFilter(=,'substring:name')"}
#scan扫描多行记录:
//Some examples:
hbase> scan 'hbase:meta'
hbase> scan 'hbase:meta', {COLUMNS => 'info:regioninfo'}
hbase> scan 'ns1:t1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => 'c1', TIMERANGE => [1303668804, 1303668904]}
hbase> scan 't1', {REVERSED => true}
hbase> scan 't1', {ALL_METRICS => true}
hbase> scan 't1', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED']}
hbase> scan 't1', {ROWPREFIXFILTER => 'row2', FILTER => "
(QualifierFilter (>=, 'binary:xyz')) AND (TimestampsFilter ( 123, 456))"}
hbase> scan 't1', {FILTER =>
org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)}
hbase> scan 't1', {CONSISTENCY => 'TIMELINE'}
For setting the Operation Attributes
hbase> scan 't1', { COLUMNS => ['c1', 'c2'], ATTRIBUTES => {'mykey' => 'myvalue'}}
hbase> scan 't1', { COLUMNS => ['c1', 'c2'], AUTHORIZATIONS => ['PRIVATE','SECRET']}
根据列族检索所有键值对:
>>scan 'mmzs:tuser',{COLUMNS=>'base'}
>>scan 'mmzs:tuser',{COLUMNS=>['base:name','extra:name']}
#根据Key部分字段匹配:
>>scan 'mmzs:tuser',{COLUMNS=>['base','extra'],FILTER=>"QualifierFilter(=,'substring:age')"}
#根据Value部分字段匹配:
>>scan 'mmzs:tuser',{COLUMNS=>['base','extra'],FILTER=>"ValueFilter(=,'substring:liubei')"}
#查询指定行到指定行
>>scan 'mmzs:tuser',{COLUMNS=>['base','extra'],STARTROW=>'002',ENDROW=>'004'}
#根据行键进行过滤,秒级速度
>>put 'mmzs:tuser','ligang+20171205+chengdu','base:name','ligang'
>>scan 'mmzs:tuser',{ROWPREFIXFILTER=>'ligang'}
#扫描过滤后并用limit进行分页处理,从第二行开始,显示3行
>>scan 'mmzs:tuser',{COLUMN=>['base','extra'],STARTROW=>'002',LIMIT=>3}
HBase命令终端测试的更多相关文章
- Hadoop 之Hbase命令
一.常用命令:(hbase shell 进入终端) 1.创建表: create 'users','user_id','address','info' 表users,有三个列族user_id,addre ...
- Hbase总结(一)-hbase命令,hbase安装,与Hive的区别,与传统数据库的区别,Hbase数据模型
Hbase总结(一)-hbase命令 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令表达式 创建表 create '表名称', ...
- Hbase的安装测试工作
Hbase的安装测试工作: 安装:http://www.cnblogs.com/neverwinter/archive/2013/03/28/2985798.html 测试:http://www.cn ...
- hbase命令备忘
http://www.cnblogs.com/linjiqin/archive/2013/03/08/2949339.html HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase ...
- [HBase_3] HBase 命令
0. 说明 1. HBase 命令 1.1 HBase 与 SQL 的区别 1.2 合并 HBase 中的小文件 major_compact 'test:t1' 1.3 删除数据的区别 HBase 在 ...
- Win7命令终端基础配色指南
微软对控制台字体的元数据有严格的限制,https://support.microsoft.com/zh-cn/help/247815/necessary-criteria-for-fonts-to-b ...
- ab命令压力测试
网站性能压力测试是服务器网站性能调优过程中必不可缺少的一环.只有让服务器处在高压情况下,才能真正体现出软件.硬件等各种设置不当所暴露出的问题. 性能测试工具目前最常见的有以下几种:ab.http_lo ...
- centos LB负载均衡集群 三种模式区别 LVS/NAT 配置 LVS/DR 配置 LVS/DR + keepalived配置 nginx ip_hash 实现长连接 LVS是四层LB 注意down掉网卡的方法 nginx效率没有LVS高 ipvsadm命令集 测试LVS方法 第三十三节课
centos LB负载均衡集群 三种模式区别 LVS/NAT 配置 LVS/DR 配置 LVS/DR + keepalived配置 nginx ip_hash 实现长连接 LVS是四层LB ...
- Linux命令行测试网速speedtest.net
Linux命令行测试网速speedtest.net 当发现上网速度变慢时,人们通常会先首先测试自己的电脑到网络服务提供商(通常被称为"最后一公里")的网络连接速度.在可用于测试宽带 ...
随机推荐
- 关于字符的C++函数
toupper(), tolower()不会改变原来的字符; 如果输入不是字母, 返回值跟原字符相同. isupper(), islower()..
- How to setup Visual Studio without pain
Visual Studio (VS) can be very hard to install. If you are lucky, one whole day may be enough to ins ...
- js实现上传图片回显功能
用到h5技术 <img id="headimg" src="<%=path%>/resources/images/icon4.png" sty ...
- 正确理解python中的赋值语句:a, b = b, a + b
赋值语句: a, b = b, a + b 相当于: t = (b, a + b) # t是一个tuple a = t[0] b = t[1] 但不必显式写出临时变量t就可以赋值.
- 可遇不可求的Question之MySqlClient的Guid 类型的映射篇
关于 Guid 类型的映射 MySql 没有原生的 Guid 类型,一般使用 binary(16) 或者 char(36) 这两个类型.早期版本的 Connector/Net 将 binary(16) ...
- java(一) 基础部分
1.11.简单讲一下java的跨平台原理 Java通过不同的系统.不同版本.不同位数的java虚拟机(jvm),来屏蔽不同的系统指令集差异而对外体统统一的接口(java API),对于我们普通的jav ...
- Py福利,基于uiautomatorviewer 的Python 自动化代码自动生成工具分享(jar已发布GitHub,欢迎Star)
前言做UI自动化无论你用SDK自带的uiautomatorviewer还是Macaca还是Appium自动的inspector,代码最多的就是那些繁琐重复的找元素后点击,输入,长按.....等.现在偷 ...
- unity shader 常用函数列表
此篇博客转自csdn的一位大牛. 中间排版出了一些问题 Intrinsic Functions (DirectX HLSL) The following table lists the intrins ...
- ASP.NET Core 微服务初探[2]:熔断降级之Polly
当我们从单体架构迁移到微服务模式时,其中一个比较大的变化就是模块(业务,服务等)间的调用方式.在以前,一个业务流程的执行在一个进程中就完成了,但是在微服务模式下可能会分散到2到10个,甚至更多的机器( ...
- 通过Weeman+Ettercap配合拿下路由器管理权限
通过Weeman+Ettercap配合拿下路由器管理权限 本文转自>>>i春秋学院 本篇文章主要介绍如何在接入无线网络后如何拿到路由器的管理权限,至于如何得到路由器连接密码可以参考 ...