【学习笔记】sklearn数据集与估计器
数据集划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 20%, 75%: 25%
sklearn数据集划分API:
sklearn.model_selection.train_test_split
常用参数:
- 特征值和目标值
- test_size:测试数据的大小,默认为0.25
返回值:训练数据特征值,测试数据特征值,训练数据目标值,测试数据目标值的元组
scikit-learn数据集API
自己准备数据集耗时耗力,而且不一定真实,scikit-learn提供了非常方便的获取数据集的API。
sklearn.datasets:加载获取流行数据集
- datasets.load_*():获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None):获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
- datasets.make_*():本地生成数据集
load*和 fetch* 函数返回的数据类型是 datasets.base.Bunch,本质上是一个 dict,它的键值对可用通过对象的属性方式访问。主要包含以下属性:
- data:特征数据数组,是 n_samples * n_features 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名
- target_names:标签名
数据集目录可以通过datasets.get_data_home()获取,clear_data_home(data_home=None)删除所有下载数据
datasets.get_data_home(data_home=None):返回scikit学习数据目录的路径。这个文件夹被一些大的数据集装载器使用,以避免下载数据。默认情况下,数据目录设置为用户主文件夹中名为“scikit_learn_data”的文件夹。或者,可以通过“SCIKIT_LEARN_DATA”环境变量或通过给出显式的文件夹路径以编程方式设置它。'〜'符号扩展到用户主文件夹。如果文件夹不存在,则会自动创建。
sklearn.datasets.clear_data_home(data_home=None):删除存储目录中的数据
加载小批量数据:
加载并返回鸢尾花数据集,并对其进行划分:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
li = load_iris()
# print("获取特征值")
# print(li.data)
# print("获取目标值")
# print(li.target)
# print(li.DESCR)
x_train, x_test, y_train, y_test = train_test_split(
li.data, li.target, test_size=0.25)
print("训练集特征值和目标值", x_train, y_train)
print("测试集特征值和目标值", x_test, y_test)
加载大批量的数据:
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset: 'train'或者'test','all',可选,选择要加载的数据集.训练集的“训练”,测试集的“测试”,两者的“全部
from sklearn.datasets import load_iris, fetch_20newsgroups
news = fetch_20newsgroups()
print(news.data)
print(news.target)
加载波士顿房价
from sklearn.datasets import load_boston
lb = load_boston()
print("获取特征值")
print(lb.data)
print("获取目标值")
print(lb.target)
print(lb.DESCR)
sklearn机器学习算法的实现-估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API。
- fit方法用于从训练集中学习模型参数
- transform用学习到的参数转换数据
1、用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
2、用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
估计器的工作流程:
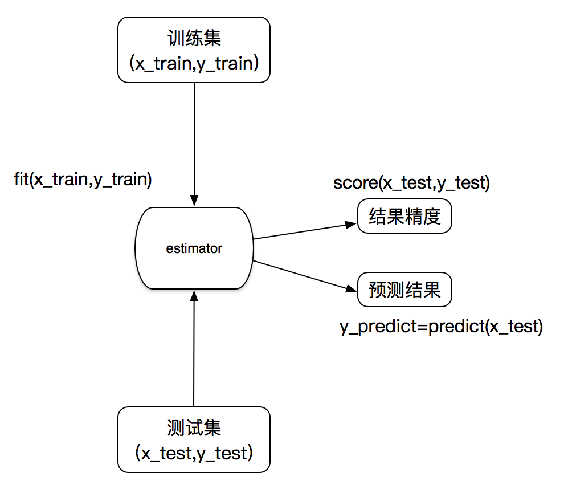
【学习笔记】sklearn数据集与估计器的更多相关文章
- 人脸检测学习笔记(数据集-DLIB人脸检测原理-DLIB&OpenCV人脸检测方法及对比)
1.Easily Create High Quality Object Detectors with Deep Learning 2016/10/11 http://blog.dlib.net/201 ...
- mORMot学习笔记3 数据集转Json
usesSynCommons, SynDB, SynOleDB; procedure TForm1.DataToJsonClick(Sender: TObject); var Conn: TOleDB ...
- 机器学习笔记(四)--sklearn数据集
sklearn数据集 (一)机器学习的一般数据集会划分为两个部分 训练数据:用于训练,构建模型. 测试数据:在模型检验时使用,用于评估模型是否有效. 划分数据的API:sklearn.model_se ...
- tensorflow中使用mnist数据集训练全连接神经网络-学习笔记
tensorflow中使用mnist数据集训练全连接神经网络 ——学习曹健老师“人工智能实践:tensorflow笔记”的学习笔记, 感谢曹老师 前期准备:mnist数据集下载,并存入data目录: ...
- SAS学习笔记之《SAS编程与数据挖掘商业案例》(3)变量操作、观测值操作、SAS数据集管理
SAS学习笔记之<SAS编程与数据挖掘商业案例>(3)变量操作.观测值操作.SAS数据集管理 1. SAS变量操作的常用语句 ASSIGNMENT 创建或修改变量 SUM 累加变量或表达式 ...
- SAS学习笔记之《SAS编程与数据挖掘商业案例》(2)数据获取与数据集操作
SAS学习笔记之<SAS编程与数据挖掘商业案例>(2)数据获取与数据集操作 1. SET/SET效率高,建立的主表和建表索引的查询表一般不排序, 2. BY语句,DATA步中,BY语句规定 ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
- 学习笔记之机器学习(Machine Learning)
机器学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 机器学习是人工智能的一个分 ...
- Deep learning with Python 学习笔记(9)
神经网络模型的优化 使用 Keras 回调函数 使用 model.fit()或 model.fit_generator() 在一个大型数据集上启动数十轮的训练,有点类似于扔一架纸飞机,一开始给它一点推 ...
随机推荐
- Icehouse 创建Instance代码分析
1. nova-api接收到request 在/etc/nova/api-paste.ini中,是这样配置nova v2的 [app:osapi_compute_app_v2] paste.app_f ...
- ElasticSearch写入数据的工作原理是什么?
面试题 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗? 面试官心理分析 问这个,其实面试官就是要看看你了解不了解 es 的一些基 ...
- 微信小程序中如何使用WebSocket实现长连接(含完整源码)
本文由腾讯云技术团队原创,感谢作者的分享. 1.前言 微信小程序提供了一套在微信上运行小程序的解决方案,有比较完整的框架.组件以及 API,在这个平台上面的想象空间很大.腾讯云研究了一番之后,发现 ...
- 吴恩达机器学习笔记39-误差分析与类偏斜的误差度量(Error Analysis and Error Metrics for Skewed Classes)
如果你准备研究机器学习的东西,或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统,拥有多么复杂的变量:而是构建一个简单的算法,这样你可以很快地实现它. 构建一个学习算法的推荐方法为:1 ...
- C 线性表的顺序存储实现及插入、删除等操作示例
一.线性表的定义 线性表(Linear List)是由同一类型元素构成的有序序列的线性结构.线性表中元素的个数称为线性表的长度:线性表内没有元素(长度为0)时,称为空表:表的起始位置称为表头,表的结束 ...
- mouseover和mouseenter,mouseout和mouseleave的区别-引发的探索
相信小伙伴们都用过鼠标事件,比如mouseover和mouseout,mouseenter和mouseleave.它们都分别表示鼠标移入移出. 在使用的过程中,其实一直有个小疑问——它们之间究竟有什么 ...
- 【MySQL】sql_mode引起的一个问题和总结
[背景] 之前项目中,项目组计划将现场的MySQL5.5升级到5.7,以提升主从同步性能.使用半同步复制,以及解决一些现场问题等.安排测试组进行验证,测试同事反馈实验室环境中发现有入库失败,我查看了e ...
- python通过手机抓取微信公众号
使用 Fiddler 抓包分析公众号 打开微信随便选择一个公众号,查看公众号的所有历史文章列表 在 Fiddler 上已经能看到有请求进来了,说明公众号的文章走的都是HTTPS协议,这些请求就是微信客 ...
- vis.js没有中文文档,个人在项目中总结的一些中文配置
##vis.js var options = { nodes:{//节点配置 borderWidth: 1,//节点边框的宽度,单位为px borderWidthSelected: 2,节点被选中时边 ...
- [P5172] Sum
"类欧几里得算法"第一题 sum [题意] 给入\(n,r\),求\(\sum_{d=1}^n(-1)^{\lfloor d\sqrt r \rfloor}\). [分析] 只需要 ...