Python 实现 KNN(K-近邻)算法
一、概述
KNN(K-最近邻)算法是相对比较简单的机器学习算法之一,它主要用于对事物进行分类。用比较官方的话来说就是:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例, 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。为了更好地理解,通过一个简单的例子说明。
我们有一组自拟的关于电影中镜头的数据:
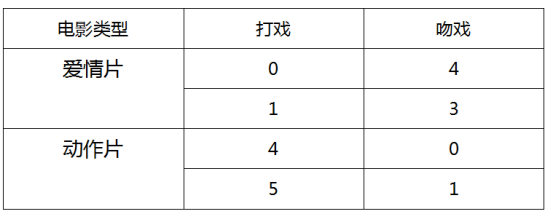
那么问题来了,如果有一部电影 X,它的打戏为 3,吻戏为 2。那么这部电影应该属于哪一类?
我们把所有数据通过图表显示出来(圆点代表的是自拟的数据,也称训练集;三角形代表的是 X 电影的数据,称为测试数据):

计算测试数据到训练数据之间的距离,假设 k 为 3,那么我们就找到距离中最小的三个点,假如 3 个点中有 2 个属于动作片,1 个属于爱情片,那么把该电影 X 分类为动作片。这种通过计算距离总结 k 个最邻近的类,按照”少数服从多数“原则分类的算法就为 KNN(K-近邻)算法。
二、算法介绍
还是以上面的数据为例,打戏数为 x,吻戏数为 y,通过欧式距离公式计算测试数据到训练数据的距离,我上中学那会儿不知道这个叫做欧式距离公式,一直用”两点间的距离公式“来称呼这个公式: 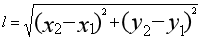 。但是现实中的很多数据都是多维的,即使如此,也还是按照这个思路进行计算,比如如果是三维的话,就在根号里面再加上 z 轴差的平方,即
。但是现实中的很多数据都是多维的,即使如此,也还是按照这个思路进行计算,比如如果是三维的话,就在根号里面再加上 z 轴差的平方,即 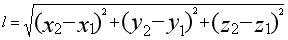 ,以此类推。
,以此类推。
知道了这个计算公式,就可以计算各个距离了。我们以到最上面的点的距离为例: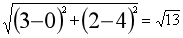 ,那么从上到下的距离分别是:
,那么从上到下的距离分别是: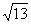 ,
,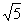 ,
,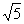 ,
,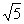 。现在我们把 k 定为 3,那么距离最近的就是后面三个数了,在这三个数中,有两个属于动作片,因此,电影 X 就分类为动作片。
。现在我们把 k 定为 3,那么距离最近的就是后面三个数了,在这三个数中,有两个属于动作片,因此,电影 X 就分类为动作片。
三、算法实现
知道了原理,那就可以用代码实现了,这里就不再赘述了,直接上带注释的 Python 代码:
'''
trainData - 训练集
testData - 测试集
labels - 分类
'''
def knn(trainData, testData, labels, k):
# 计算训练样本的行数
rowSize = trainData.shape[0]
# 计算训练样本和测试样本的差值
diff = np.tile(testData, (rowSize, 1)) - trainData
# 计算差值的平方和
sqrDiff = diff ** 2
sqrDiffSum = sqrDiff.sum(axis=1)
# 计算距离
distances = sqrDiffSum ** 0.5
# 对所得的距离从低到高进行排序
sortDistance = distances.argsort() count = {} for i in range(k):
vote = labels[sortDistance[i]]
count[vote] = count.get(vote, 0) + 1
# 对类别出现的频数从高到低进行排序
sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True) # 返回出现频数最高的类别
return sortCount[0][0]
ps:np.tile(testData, (rowSize, 1)) 是将 testData 这个数据扩展为 rowSize 列,这样能避免运算错误;
sorted(count.items(), key=operator.itemgetter(1), reverse=True) 排序函数,里面的参数 key=operator.itemgetter(1), reverse=True 表示按照 count 这个字典的值(value)从高到低排序,如果把 1 换成 0,则是按字典的键(key)从高到低排序。把 True 换成 False 则是从低到高排序。
四、测试与总结
用 Python 实现了算法之后,我们用上面的数据进行测试,看一下结果是否和我们预测的一样为动作片:
trainData = np.array([[5, 1], [4, 0], [1, 3], [0, 4]])
labels = ['动作片', '动作片', '爱情片', '爱情片']
testData = [3, 2]
X = knn(trainData, testData, labels, 3)
print(X)
执行这段代码后输出的结果为:动作片 。和预测的一样。当然通过这个算法分类的正确率不可能为 100%,可以通过增加修改数据测试,如果有大量多维的数据就更好了。
Python 实现 KNN(K-近邻)算法的更多相关文章
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- KNN K~近邻算法笔记
K~近邻算法是最简单的机器学习算法.工作原理就是:将新数据的每一个特征与样本集中数据相应的特征进行比較.然后算法提取样本集中特征最相似的数据的分类标签.一般来说.仅仅提取样本数据集中前K个最相似的数据 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
- kNN(k近邻)算法代码实现
目标:预测未知数据(或测试数据)X的分类y 批量kNN算法 1.输入一个待预测的X(一维或多维)给训练数据集,计算出训练集X_train中的每一个样本与其的距离 2.找到前k个距离该数据最近的样本-- ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
- 数据挖掘算法(一)--K近邻算法 (KNN)
数据挖掘算法学习笔记汇总 数据挖掘算法(一)–K近邻算法 (KNN) 数据挖掘算法(二)–决策树 数据挖掘算法(三)–logistic回归 算法简介 KNN算法的训练样本是多维特征空间向量,其中每个训 ...
随机推荐
- Nginx服务器中配置非80端口的端口转发方法详解
这篇文章主要介绍了Nginx服务器中配置非80端口的端口转发方法详解,文中使用到了Nginx中的proxy_pass配置项,需要的朋友可以参考下 nginx可以很方便的配置成反向代理服务器: 1 2 ...
- istio实现对外暴露服务
1.确认istio-ingressgateway是否有对外的IP kubectl get service istio-ingressgateway -n istio-system 如果 EXTERNA ...
- s6-4 TCP 数据段
传输控制协议 TCP (Transmission Control Protocol) 是专门为了在不可靠的互联网络上提供可靠的端到端字节流而设计的 TCP必须动态地适应不同的拓扑.带宽.延迟. ...
- Chrome扩展插件流程
一.浏览器插件基础步骤: 1.文件最基础的配置 : 一个manifest文件.一个或多个html文件.可选的一个或多个javascript文件.可选的任何需要的其他文件,例如图片:在开发应用(扩展)时 ...
- 避免docker异常重启容器挂掉的解决方法
Docker 升级或者重启容器不会被停掉然后重启的解决方法 在/etc/systemd/system/multi-user.target.wants/docker.service文件下添加配置 注意: ...
- HDU - 1241 Oil Deposits 经典dfs 格子
最水的一道石油竟然改了一个小时,好菜好菜. x<=r y<=c x<=r y<=c x<=r y<=c x<=r y<=c #include ...
- gitlab 之 升级、迁移
-----故事背景- 公司服务器用vm装的虚拟机,由于公司服务器经常无故重启,且找不到原因,所以公司准备将vm迁移至Hyper-V,Hyper-V可以自启动虚拟机且免费. -----升级.迁移- 首先 ...
- homekit2mqtt on DietPi
Followed official install instruction and got: dns_sd.DNSServiceRegister(self.serviceRef, flags, ifa ...
- spark入门
这一两年Spark技术很火,自己也凑热闹,反复的试验.研究,有痛苦万分也有欣喜若狂,抽空把这些整理成文章共享给大家.这个系列基本上围绕了Spark生态圈进行介绍,从Spark的简介.编译.部署,再到编 ...
- 解决jenkins控制台中文乱码问题
1,进入[系统管理]->[系统设置]->全局属性:KEY: LANG; VALUE:zh.CH.UTF-8 2,修改Jenkins.xml文件 在Jenkins安装目录下找到jenkins ...