047 SparkSQL自定义UDF函数
一:程序部分
1.需求
Double数据类型格式化,可以给定小数点位数
2.程序
package com.scala.it
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.hive.HiveContext import scala.math.BigDecimal.RoundingMode
object SparkSQLUDFDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("udf")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // ==================================
// 写一个Double数据格式化的自定义函数(给定保留多少位小数部分)
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
}) sqlContext.sql(
"""
|SELECT
| deptno,
| doubleValueFormat(AVG(sal), 2) AS avg_sal
|FROM hadoop09.emp
|GROUP BY deptno
""".stripMargin).show() }
}
3.结果

二:知识点解释
1.udf
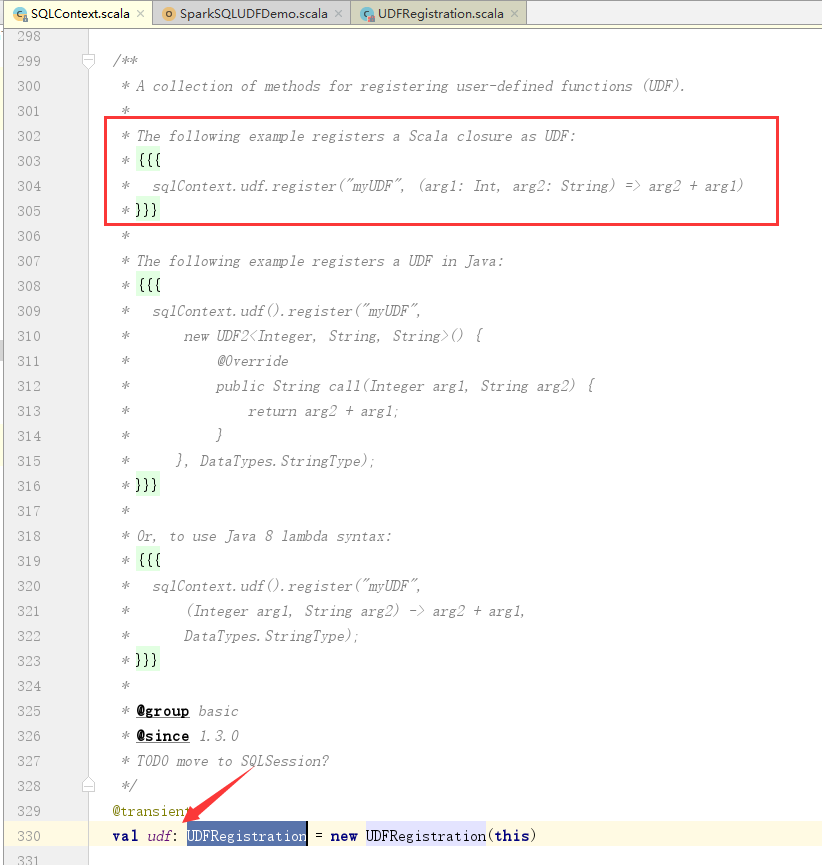
2.refister

047 SparkSQL自定义UDF函数的更多相关文章
- 自定义UDF函数应用异常
自定义UDF函数应用异常 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 ...
- sparksql 自定义用户函数(UDF)
自定义用户函数有两种方式,区别:是否使用强类型,参考demo:https://github.com/asker124143222/spark-demo 1.不使用强类型,继承UserDefinedAg ...
- Spark(十三)【SparkSQL自定义UDF/UDAF函数】
目录 一.UDF(一进一出) 二.UDAF(多近一出) spark2.X 实现方式 案例 ①继承UserDefinedAggregateFunction,实现其中的方法 ②创建函数对象,注册函数,在s ...
- 【Spark篇】---SparkSql之UDF函数和UDAF函数
一.前述 SparkSql中自定义函数包括UDF和UDAF UDF:一进一出 UDAF:多进一出 (联想Sum函数) 二.UDF函数 UDF:用户自定义函数,user defined functio ...
- 如何给Apache Pig自定义UDF函数?
近日由于工作所需,需要使用到Pig来分析线上的搜索日志数据,散仙本打算使用hive来分析的,但由于种种原因,没有用成,而Pig(pig0.12-cdh)散仙一直没有接触过,所以只能临阵磨枪了,花了两天 ...
- 048 SparkSQL自定义UDAF函数
一:程序 1.需求 实现一个求平均值的UDAF. 这里保留Double格式化,在完成求平均值后与系统的AVG进行对比,观察正确性. 2.SparkSQLUDFDemo程序 package com.sc ...
- Hive与MapReduce相关排序及自定义UDF函数
原文链接: https://www.toutiao.com/i6770870821809291788/ Hive和mapreduce相关的排序和运行的参数 1.设置每个reduce处理的数据量(单位是 ...
- Spark注册UDF函数,用于DataFrame DSL or SQL
import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions._ object Test2 { def ...
- 自定义udf添加一列
//创建得分窗口字典 var dict= new mutable.HashMap[Double, Int]() ){ dict.put(result_Score(i),i) } //自定义Udf函数 ...
随机推荐
- 连接mysql(建表和删表)
from sqlalchemy.ext.declarative import declarative_base##拿到父类from sqlalchemy import Column##拿到字段from ...
- Sql语句分页,有待优化
封装成存储过程,但是有点小问题,如果有弄好了的朋友可留言,谢谢了,我只提供了一个模版哈(也是我想实现的功能) create procedure paging_procedure ( @pageInde ...
- 04 if条件判断 流程控制
条件判断 if 语法一: if 条件: # 条件成立时执行的子代码块 代码1 代码2 代码3 示例: sex='female' age=18 is_beautiful=True if sex == ' ...
- Confluence 6 避免和清理垃圾
如果你的 Confluence 是允许公众访问的话,你可能会遇到垃圾内容的骚扰. 阻止垃圾发布者 希望阻止垃圾发布者: 启用验证码(Captcha),请参考页面 Configuring Captcha ...
- day03 变量 运算符 基本数据类型 输出功能 格式化输出
变量补充 变量的命名 1变量名的命名的大前提:应该能够反映出变量值所记录的状态 具体的1.变量名由字母数字下划线组成 2.不能以数字开头 3.不能使用关键字命名为变量名 两种写法 1.驼峰体(由字母组 ...
- 【linux】复制文件夹中文件,排除部分文件
如下 cp `ls|grep -v -E '*json|out'|xargs` /home/data/ 用grep -v 表示排除, -E 表示正则 ls|grep -v -E '*json|out ...
- jQuery之导航菜单(点击该父节点时子节点显示,同时子节点的同级隐藏,但是同级的父节点始终显示)
注:对于同一个对象不超过3个操作的,可直接写成一行,超 过3个操作的建议每行写一个操作.这样可读性较强,可提高代码的可读性和可维护性 核心代码: $(".has_children" ...
- Mysql 查看连接数,状态 最大并发数
show status like '%max_connections%'; ##mysql最大连接数set global max_connections=1000 ##重新设置show variabl ...
- AI-DRF权限、频率
权限 权限逻辑 权限逻辑 权限组件可以设置在三个地方:写在每个类下边表示,访问这个类的数据时,没有权限就不能访问:写在全局,表示访问每个字段的数据都需要权限:还有默认已经也写好了. 写在每个类中:写一 ...
- ubuntu 下配置munin
环境: "Ubuntu 13.10" 安装: apt-get install munin munin-nodeapt-get install apache2 配置: 1. vim ...