HDFS 上文件块的副本数设置
一、使用 setrep 命令来设置
# 设置 /javafx-src.zip 的文件块只存三份
hadoop fs -setrep /javafx-src.zip
二、文件块在磁盘上的路径
# 设置的 hdfs 目录为
/opt/hadoop-tmp/
# hdfs 文件块的路径为
/opt/hadoop-tmp/dfs/data/current/BP-362764591-192.168.8.136-1554970906073/current/finalized/subdir0/subdir0

三、文件的分割
文件大小 < 块设定值,文件不会被切割,直接存放到 hdfs 上,占用磁盘的空间就是文件大小
文件大小 > 块设定值,文件被切割为块大小的 N 份文件,最后一份不够块大小也上面一样,只占用本身大小的磁盘空间 下图可以看到该文件副本为 3 份,分别存放在 h140、h138 和 h136 三台机器上
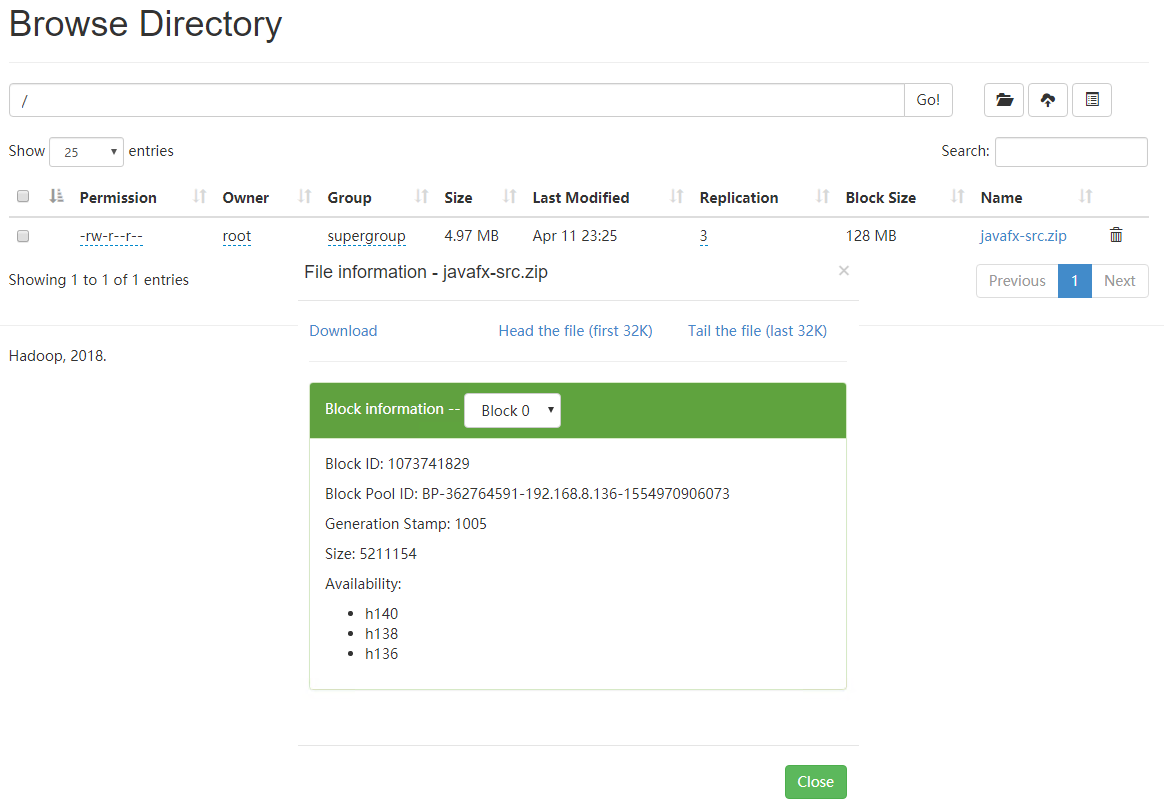
四、改变副本数后的文件的变化
# 减少,会随机删除一个机器上的文件块,这里是删除了 h136 上的
hadoop fs -setrep 2 /javafx-src.zip
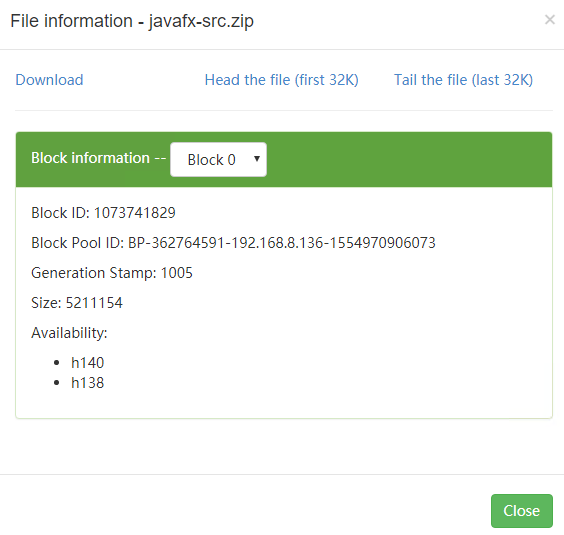
# 增加,由于只配置了三台机器无法截图
# 分两种情况:
# 机器数量 >= 副本数,会把所有文件块复制到新节点
# 机器数量 < 副本数,会等有新节点增加再执行复制操作,一直到达副本数为止
# 文件块的副本数储存在 NameNode 上
hadoop fs -setrep 5 /javafx-src.zip
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS 上文件块的副本数设置的更多相关文章
- impala删表,而hdfs上文件却还在异常处理
Impala/hive删除表,drop后,hdfs上文件却还在处理方法: 问题原因分析,如下如可以看出一个属组是hive,一个是impala,keberas账号登录hive用户无法删除impala用户 ...
- shell脚本监控Flume输出到HDFS上文件合法性
在使用flume中发现由于网络.HDFS等其它原因,使得经过Flume收集到HDFS上得日志有一些异常,表现为: 1.有未关闭的文件:以tmp(默认)结尾的文件.加入存到HDFS上得文件应该是gz压缩 ...
- MapReduce读取hdfs上文件,建立词频的倒排索引到Hbase
Hdfs上的数据文件为T0,T1,T2(无后缀): T0: What has come into being in him was life, and the life was the light o ...
- 通过spark sql 将 hdfs上文件导入到mongodb
功能:通过spark sql 将hdfs 中文件导入到mongdo 所需jar包有:mongo-spark-connector_2.11-2.1.2.jar.mongo-java-driver-3.8 ...
- SparkHiveContext和直接Spark读取hdfs上文件然后再分析效果区别
最近用spark在集群上验证一个算法的问题,数据量大概是一天P级的,使用hiveContext查询之后再调用算法进行读取效果很慢,大概需要二十多个小时,一个查询将近半个小时,代码大概如下: try: ...
- 如何修改HDFS上文件
如果只想append操作: . echo "<Text to append>" | hdfs dfs -appendToFile - yourHdfsPath/test ...
- hadoop修改MR的提交的代码程序的副本数
hadoop修改MR的提交的代码程序的副本数 Under-Replicated Blocks的数量很多,有7万多个.hadoop fsck -blocks 检查发现有很多replica missing ...
- hdfs fsck命令查看HDFS文件对应的文件块信息(Block)和位置信息(Locations)
关键字:hdfs fsck.block.locations 在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态.获取文件的block信息和位置信息等. fsck命令必须由HDFS ...
- ES的副本数量、插入大批量数据前,副本数应该设置为0
多副本可以提升检索的能力,但是如果副本数量太多,插入数据的时候容易出现卡顿现象: 因为主分片要把数据同步给所有的副本,所以建议副本数量最好是1-2个: ---- Es在索引数据的时候,如果存在副本,那 ...
随机推荐
- BZOJ2342[Shoi2011]双倍回文——回文自动机
题目描述 输入 输入分为两行,第一行为一个整数,表示字符串的长度,第二行有个连续的小写的英文字符,表示字符串的内容. 输出 输出文件只有一行,即:输入数据中字符串的最长双倍回文子串的长度,如果双倍回文 ...
- Codeforces Round #445 Div. 1
A:每次看是否有能走回去的房间,显然最多只会存在一个,如果有走过去即可,否则开辟新房间并记录访问时间. #include<iostream> #include<cstdio> ...
- #186 path(容斥原理+状压dp+NTT)
首先只有一份图时显然可以状压dp,即f[S][i]表示S子集的哈密顿路以i为终点的方案数,枚举下个点转移. 考虑容斥,我们枚举至少有多少条原图中存在的边(即不合法边)被选进了哈密顿路,统计出这个情况下 ...
- HDU2710-Max Factor-分解质因子
给出N个MAXN以内的不同的数,求出素因子最大的数. 使用朴素的方法分解素因子即可.时间复杂度为N*log(MAXN) #include <cstdio> #include <alg ...
- 洛谷P1063能量项链题解
$题目$ 不得不说,最近我特别爱刷这种区间DP题,因为这个跟其他的DP有些不一样的地方,主要是有一定的套路,就是通过小区间的状态更新大区间,从而得到原题给定区间的最优解. $但是$ 这个题应该跟$石子 ...
- Spring模块介绍
GroupId ArtifactId 说明 org.springframework spring-beans Beans 支持,包含 Groovy org.springframework spring ...
- Spring点滴五:Spring中的后置处理器BeanPostProcessor讲解
BeanPostProcessor接口作用: 如果我们想在Spring容器中完成bean实例化.配置以及其他初始化方法前后要添加一些自己逻辑处理.我们需要定义一个或多个BeanPostProcesso ...
- 【BZOJ2324】[ZJOI2011]营救皮卡丘(网络流,费用流)
[BZOJ2324][ZJOI2011]营救皮卡丘(网络流,费用流) 题面 BZOJ 洛谷 题解 如果考虑每个人走的路径,就会很麻烦. 转过来考虑每个人破坏的点集,这样子每个人可以得到一个上升的序列. ...
- [luogu3620][APIO/CTSC 2007]数据备份【贪心+堆+链表】
题目描述 你在一家 IT 公司为大型写字楼或办公楼(offices)的计算机数据做备份.然而数据备份的工作是枯燥乏味的,因此你想设计一个系统让不同的办公楼彼此之间互相备份,而你则坐在家中尽享计算机游戏 ...
- Balanced Sequence HDU - 6299(杭电多校1 B)
题目说要n个字符串串内随意组合以后将这些串放在一起,然后求最长的括号匹配的长度,并不要求是连续的 因为不需要是连续的,所以可以先把已经匹配好的括号加入到答案里面去,先把这些删掉,以为并不影响结果,然后 ...