LRU(最近最少使用淘汰算法)基本实现
LRU(Least Recently Used)
出发点:在页式存储管理中,如果一页很长时间未被访问,则它在最近一段时间内也不会被访问,即时间局部性,那我们就把它调出(置换出)内存,相反的,如果一个数据刚刚被访问过,那么该数据很大概率会在未来一段时间内访问。
可以使用栈、队列、链表来简单实现,在InnoDB中,使用适应性hash,来实现热点页的查找(因为快速)。
1. 用栈(数组模拟)简单实现访页逻辑:
#include <iostream>
using namespace std; void conduct(int Size, int Num, int A[]);//处理函数
void print(int a[], int num);//输出函数 int main()
{
int stack_size, num, i, acess[];
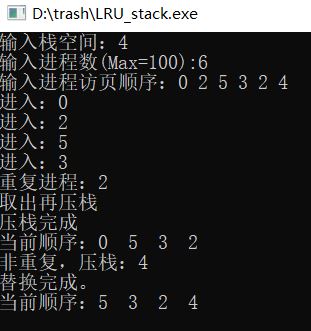
cout << "输入栈空间:" ;
cin >> stack_size;
cout << "输入进程数(Max=100):" ;
cin >> num; cout << "输入进程访页顺序:" ;
for(i=; i<num; i++)
{
cin >> acess[i];
} conduct(stack_size, num, acess); return ;
} void conduct(int Size, int Num, int A[])
{
int j, k, Stack[Size];
for(j=; j<Size; j++)
{
cout << "进入:" << A[j] <<endl;
Stack[j]=A[j];//先处理前几个元素
}
int locate;bool flag;
for(j=Size; j<Num; j++)
{
flag=false;
for(k=; k<Size; k++)
{
if(Stack[k]==A[j])
{
flag=true;
locate=k;
}
}
if(flag==true)//有重复
{
cout << "重复进程:" << A[j] <<endl;
cout << "取出再压栈" <<endl;
int tempp;
for(k=locate; k<Size; k++)
{
Stack[k]=Stack[k+];
}
Stack[Size-]=A[j];
cout << "压栈完成" <<endl;
cout << "当前顺序:"; print(Stack, Size);
}
else
{
cout << "非重复,压栈:" << A[j] <<endl;
for(k=; k<Size-; k++)
{
Stack[k]=Stack[k+];
}
Stack[Size-]=A[j];
cout << "置换完成。" <<endl;
cout << "当前顺序:";
print(Stack, Size);
}
}
} void print(int a[], int num)
{
int k;
for(k=; k<num; k++)
{
cout << a[k] << " ";
}
cout << endl;
}
Code::Blocks 17.12 运行通过!
结果:
2. 使用lis容器实现LRU逻辑
#include <iostream>
#include <list>
#include <vector>
using namespace std; class LRU
{
public:
LRU();
~LRU();
void insret(int x);
void printQ();
private:
list<int> lst;
int count;//当前页数
int max_size = ;//最大容纳页数
}; LRU::LRU()
{
this->count = ;
} LRU::~LRU()
{
} //插入算法,先查找,找到先删除再插入;未找到,直接插入
void LRU::insret(int x)
{
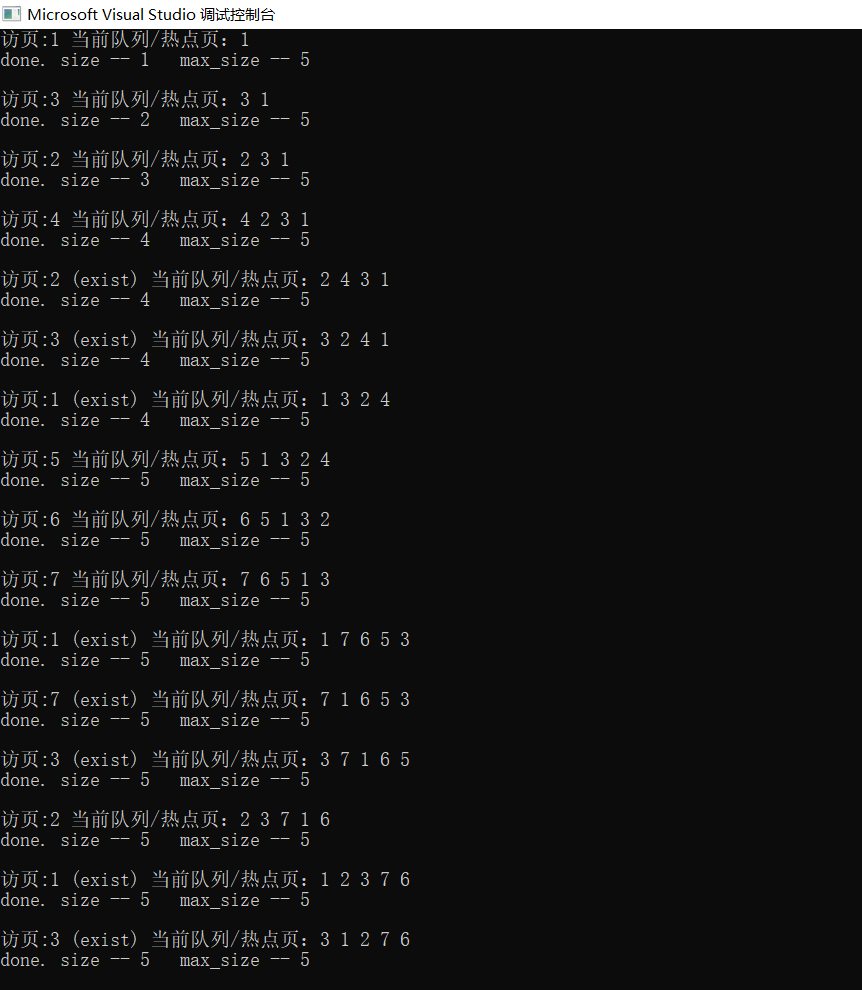
cout << "访页:" << x << " ";
auto res = find(lst.begin(), lst.end(), x);
if (res != lst.end())
{
cout << "(exist)" << " ";
lst.erase(res);
lst.push_front(x);
}
else
{
lst.push_front(x);
this->count++;
}
if (this->count > this->max_size)
{
lst.pop_back();
this->count--;
} printQ();
} //打印list
void LRU::printQ()
{
list<int>::iterator it = this->lst.begin();
cout << "当前队列/热点页:";
for (; it != lst.end(); it++)
{
cout << *it << " ";
}
cout << "\ndone. size -- " << this->count << " " << " max_size -- " << this->max_size << endl << endl;
} int main()
{
LRU lru;
vector<int> test = {, , , , , , , , , , , , , , , };
for (int i : test)
lru.insret(i);
return ;
}
结果:
LRU(最近最少使用淘汰算法)基本实现的更多相关文章
- Golang 随机淘汰算法缓存实现
缓存如果写满, 它必须淘汰旧值以容纳新值, 最近最少使用淘汰算法 (LRU) 是一个不错的选择, 因为你如果最近使用过某些值, 这些值更可能被保留. 你如果构造一个比缓存限制还长的循环, 当循环最后的 ...
- 缓存淘汰算法--LRU算法
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也 ...
- 缓存淘汰算法---LRU
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- 【转】缓存淘汰算法系列之1——LRU类
原文地址:http://www.360doc.com/content/13/0805/15/13247663_304901967.shtml 参考地址(一系列关于缓存的,后面几篇也都在这里有):htt ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 缓存淘汰算法---LRU转
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- LRU算法---缓存淘汰算法
计算机中的缓存大小是有限的,如果对所有数据都缓存,肯定是不现实的,所以需要有一种淘汰机制,用于将一些暂时没有用的数据给淘汰掉,以换入新鲜的数据进来,这样可以提高缓存的命中率,减少磁盘访问的次数. LR ...
- 淘汰算法 LRU、LFU和FIFO
含义: FIFO:First In First Out,先进先出LRU:Least Recently Used,最近最少使用 LFU:Least Frequently Used,最不经常使用 以上三者 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
随机推荐
- python元组和字典的简单学习
元组(tuple) 用圆括号()标识,定义元组后,元组元素不可修改.如果想修改元组只能重新定义元组. 因为元组不可更改,所以也没有增删改等用法,主要语法就是访问元组元素,遍历元组. 访问元组元素: t ...
- Go语言之Interface(二)
使用指针接收器和值接收器实现接口 type Describer interface { Describe() } type Person struct { name string age int } ...
- 在Mac上安装MongoDB,配置全局路径
1.访问MongoDB官方下载地址 http://www.mongodb.org/downloads 2.点击“DOWNLOAD(tgz)”按钮: 3.将下载的文件压缩包解压后剪切到你的Mac中某个位 ...
- Python编程Day4——if判断、while循环、for循环
一.if判断 语法一: if条件: 代码块1 代码块2 代码块3 示例: sex='female' age=18 is_beautiful=True if sex =='female'and age& ...
- Java核心技术及面试指南 异常部分的面试题归纳以及答案
4.2.4.1 throw和throws有什么差别?异常(Exception)和错误(Error)有什么差别? throw语句表示抛出异常,由方法体内的语句处理.throws语句用在方法声明后面,表示 ...
- linux设置打开文件句柄数
介绍 在Linux下有时会遇到Socket/File : Can't open so many files的问题.其实Linux是有文件句柄限制的,而且Linux默认一般都是1024(阿里云主机默认是 ...
- 全能系统监控工具dstat
一.什么是dstat? 通过man帮助,可以看到官方对dstat的定义为:多功能系统资源统计生成工具( versatile tool for generating system resource st ...
- IDEA添加Git项目
1.进入主页面IntelliJ IDEA (如果不知道如何进入主页面,在加载项目是点击“Cancel”按钮 ) 2.点击“Check out from Version Control” ,选择“Git ...
- DynamicProxy系列目录
C# 1.基于Emit实现动态代理 2.Microsoft.CodeAnalysis动态生成代理类 3.castle dynamicproxy + AutoFac 4.DispatchProxy .R ...
- QT 设置有效绘图区域
void QPainter::setClipRect(int x, int y, int width, int height, Qt::ClipOperation operation = Qt::Re ...