Keras 自适应Learning Rate (LearningRateScheduler)
When training deep neural networks, it is often useful to reduce learning rate as the training progresses. This can be done by using pre-defined learning rate schedules or adaptive learning rate methods. In this article, I train a convolutional neural network on CIFAR-10 using differing learning rate schedules and adaptive learning rate methods to compare their model performances.
Learning Rate Schedules
Learning rate schedules seek to adjust the learning rate during training by reducing the learning rate according to a pre-defined schedule. Common learning rate schedules include time-based decay, step decay and exponential decay. For illustrative purpose, I construct a convolutional neural network trained on CIFAR-10, using stochastic gradient descent (SGD) optimization algorithm with different learning rate schedules to compare the performances.
Constant Learning Rate
Constant learning rate is the default learning rate schedule in SGD optimizer in Keras. Momentum and decay rate are both set to zero by default. It is tricky to choose the right learning rate. By experimenting with range of learning rates in our example, lr=0.1 shows a relative good performance to start with. This can serve as a baseline for us to experiment with different learning rate strategies.
keras.optimizers.SGD(lr=0.1, momentum=0.0, decay=0.0, nesterov=False)
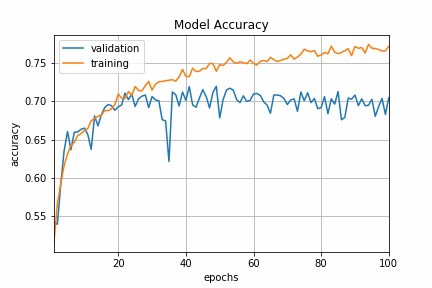
Fig 1 : Constant Learning Rate
Time-Based Decay
The mathematical form of time-based decay is lr = lr0/(1+kt) where lr, k are hyperparameters and t is the iteration number. Looking into the source code of Keras, the SGD optimizer takes decay and lr arguments and update the learning rate by a decreasing factor in each epoch.
lr *= (1. / (1. + self.decay * self.iterations))
Momentum is another argument in SGD optimizer which we could tweak to obtain faster convergence. Unlike classical SGD, momentum method helps the parameter vector to build up velocity in any direction with constant gradient descent so as to prevent oscillations. A typical choice of momentum is between 0.5 to 0.9.
SGD optimizer also has an argument called nesterov which is set to false by default. Nesterov momentum is a different version of the momentum method which has stronger theoretical converge guarantees for convex functions. In practice, it works slightly better than standard momentum.
In Keras, we can implement time-based decay by setting the initial learning rate, decay rate and momentum in the SGD optimizer.
learning_rate = 0.1
decay_rate = learning_rate / epochs
momentum = 0.8
sgd = SGD(lr=learning_rate, momentum=momentum, decay=decay_rate, nesterov=False)
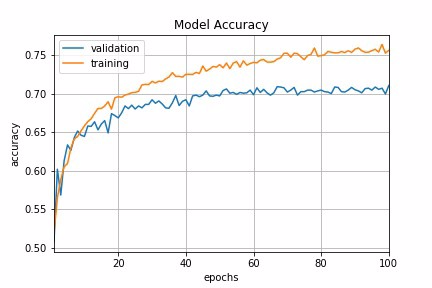
Fig 2 : Time-based Decay Schedule
Step Decay
Step decay schedule drops the learning rate by a factor every few epochs. The mathematical form of step decay is :
lr = lr0 * drop^floor(epoch / epochs_drop)
A typical way is to to drop the learning rate by half every 10 epochs. To implement this in Keras, we can define a step decay function and use LearningRateScheduler callback to take the step decay function as argument and return the updated learning rates for use in SGD optimizer.
def step_decay(epoch):
initial_lrate = 0.1
drop = 0.5
epochs_drop = 10.0
lrate = initial_lrate * math.pow(drop,
math.floor((1+epoch)/epochs_drop))
return lrate
lrate = LearningRateScheduler(step_decay)
As a digression, a callback is a set of functions to be applied at given stages of the training procedure. We can use callbacks to get a view on internal states and statistics of the model during training. In our example, we create a custom callback by extending the base class keras.callbacks.Callback to record loss history and learning rate during the training procedure.
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
self.lr = [] def on_epoch_end(self, batch, logs={}):
self.losses.append(logs.get(‘loss’))
self.lr.append(step_decay(len(self.losses)))
Putting everything together, we can pass a callback list consisting of LearningRateScheduler callback and our custom callback to fit the model. We can then visualize the learning rate schedule and the loss history by accessing loss_history.lr and loss_history.losses.
loss_history = LossHistory()
lrate = LearningRateScheduler(step_decay)
callbacks_list = [loss_history, lrate]
history = model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=epochs,
batch_size=batch_size,
callbacks=callbacks_list,
verbose=2)
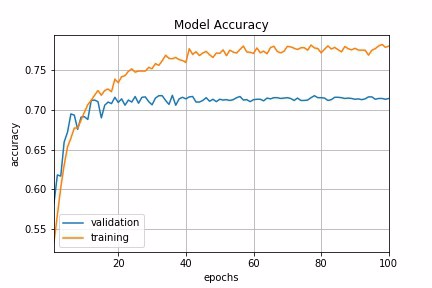
Fig 3a : Step Decay Schedule
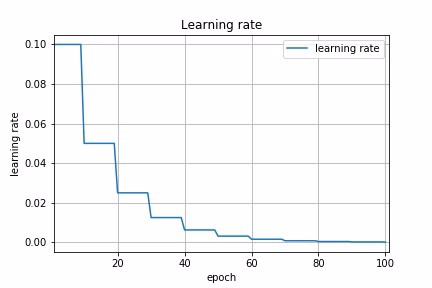
Fig 3b : Step Decay Schedule
Exponential Decay
Another common schedule is exponential decay. It has the mathematical form lr = lr0 * e^(−kt), where lr, k are hyperparameters and t is the iteration number. Similarly, we can implement this by defining exponential decay function and pass it to LearningRateScheduler. In fact, any custom decay schedule can be implemented in Keras using this approach. The only difference is to define a different custom decay function.
def exp_decay(epoch):
initial_lrate = 0.1
k = 0.1
lrate = initial_lrate * exp(-k*t)
return lrate
lrate = LearningRateScheduler(exp_decay)
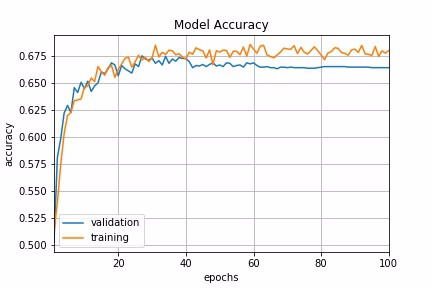
Fig 4a : Exponential Decay Schedule
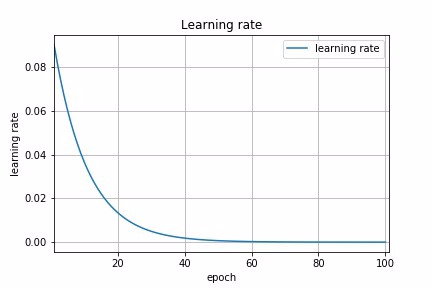
Fig 4b : Exponential Decay Schedule
Let us now compare the model accuracy using different learning rate schedules in our example.
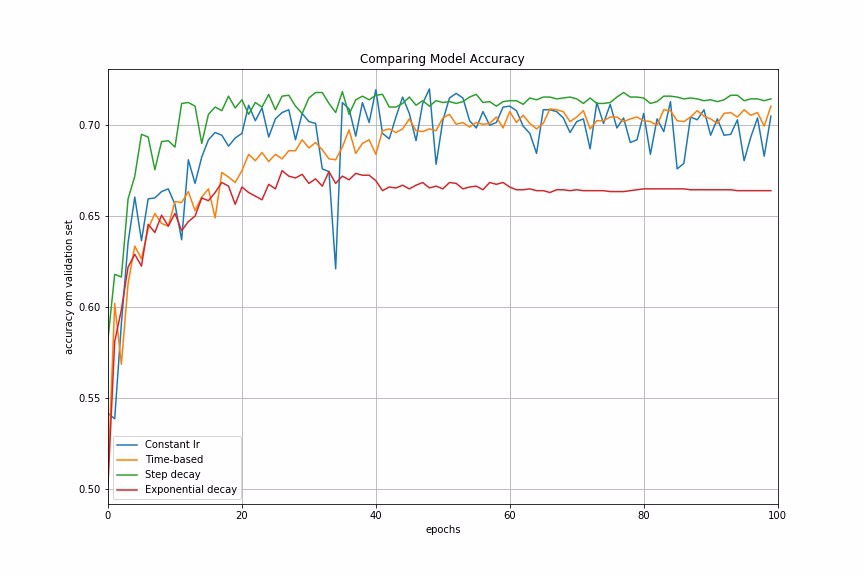
Fig 5 : Comparing Performances of Different Learning Rate Schedules
Adaptive Learning Rate Methods
The challenge of using learning rate schedules is that their hyperparameters have to be defined in advance and they depend heavily on the type of model and problem. Another problem is that the same learning rate is applied to all parameter updates. If we have sparse data, we may want to update the parameters in different extent instead.
Adaptive gradient descent algorithms such as Adagrad, Adadelta, RMSprop, Adam, provide an alternative to classical SGD. These per-parameter learning rate methods provide heuristic approach without requiring expensive work in tuning hyperparameters for the learning rate schedule manually.
In brief, Adagrad performs larger updates for more sparse parameters and smaller updates for less sparse parameter. It has good performance with sparse data and training large-scale neural network. However, its monotonic learning rate usually proves too aggressive and stops learning too early when training deep neural networks. Adadelta is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate. RMSprop adjusts the Adagrad method in a very simple way in an attempt to reduce its aggressive, monotonically decreasing learning rate. Adam is an update to the RMSProp optimizer which is like RMSprop with momentum.
In Keras, we can implement these adaptive learning algorithms easily using corresponding optimizers. It is usually recommended to leave the hyperparameters of these optimizers at their default values (except lrsometimes).
keras.optimizers.Adagrad(lr=0.01, epsilon=1e-08, decay=0.0)
keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=1e-08, decay=0.0)
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
Let us now look at the model performances using different adaptive learning rate methods. In our example, Adadelta gives the best model accuracy among other adaptive learning rate methods.
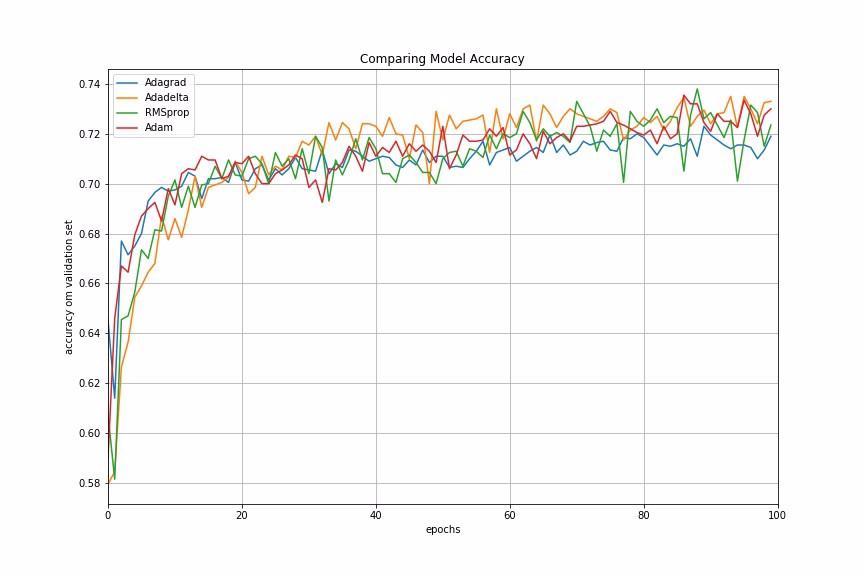
Fig 6 : Comparing Performances of Different Adaptive Learning Algorithms
Finally, we compare the performances of all the learning rate schedules and adaptive learning rate methods we have discussed.
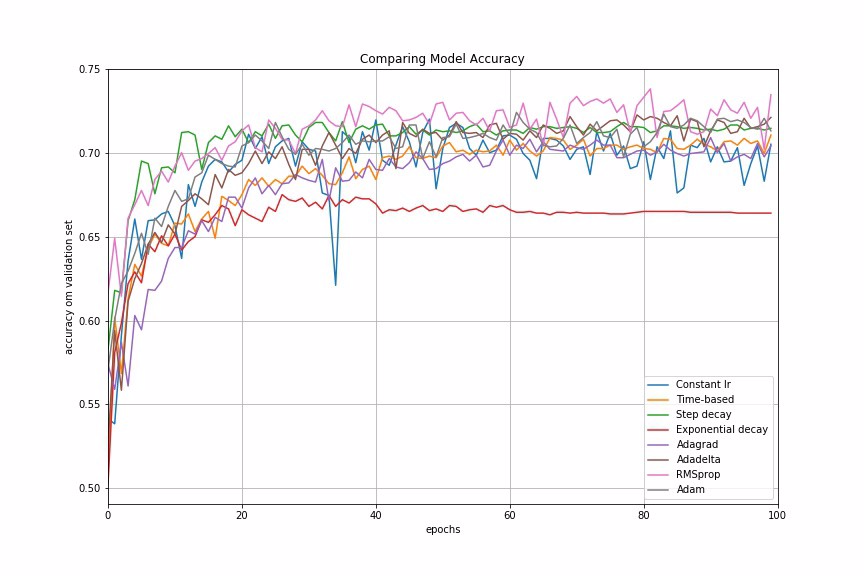
Fig 7: Comparing Performances of Different Learning Rate Schedules and Adaptive Learning Algorithms
Conclusion
In many examples I have worked on, adaptive learning rate methods demonstrate better performance than learning rate schedules, and they require much less effort in hyperparamater settings. We can also use LearningRateScheduler in Keras to create custom learning rate schedules which is specific to our data problem.
For further reading, Yoshua Bengio’s paper provides very good practical recommendations for tuning learning rate for deep learning, such as how to set initial learning rate, mini-batch size, number of epochs and use of early stopping and momentum.
References:
keras.callbacks.LearningRateScheduler(schedule)
该回调函数是用于动态设置学习率
参数:
● schedule:函数,该函数以epoch号为参数(从0算起的整数),返回一个新学习率(浮点数)
示例:
from keras.callbacks import LearningRateScheduler
lr_base = 0.001
epochs = 250
lr_power = 0.9
def lr_scheduler(epoch, mode='power_decay'):
'''if lr_dict.has_key(epoch):
lr = lr_dict[epoch]
print 'lr: %f' % lr''' if mode is 'power_decay':
# original lr scheduler
lr = lr_base * ((1 - float(epoch) / epochs) ** lr_power)
if mode is 'exp_decay':
# exponential decay
lr = (float(lr_base) ** float(lr_power)) ** float(epoch + 1)
# adam default lr
if mode is 'adam':
lr = 0.001 if mode is 'progressive_drops':
# drops as progression proceeds, good for sgd
if epoch > 0.9 * epochs:
lr = 0.0001
elif epoch > 0.75 * epochs:
lr = 0.001
elif epoch > 0.5 * epochs:
lr = 0.01
else:
lr = 0.1 print('lr: %f' % lr)
return lr # 学习率调度器
scheduler = LearningRateScheduler(lr_scheduler)
Keras 自适应Learning Rate (LearningRateScheduler)的更多相关文章
- Deep Learning 32: 自己写的keras的一个callbacks函数,解决keras中不能在每个epoch实时显示学习速率learning rate的问题
一.问题: keras中不能在每个epoch实时显示学习速率learning rate,从而方便调试,实际上也是为了调试解决这个问题:Deep Learning 31: 不同版本的keras,对同样的 ...
- Dynamic learning rate in training - 培训中的动态学习率
I'm using keras 2.1.* and want to change the learning rate during training. I know about the schedul ...
- mxnet设置动态学习率(learning rate)
https://blog.csdn.net/xiaotao_1/article/details/78874336 如果learning rate很大,算法会在局部最优点附近来回跳动,不会收敛: 如果l ...
- 学习率(Learning rate)的理解以及如何调整学习率
1. 什么是学习率(Learning rate)? 学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值.合适的学习率 ...
- 跟我学算法-吴恩达老师(mini-batchsize,指数加权平均,Momentum 梯度下降法,RMS prop, Adam 优化算法, Learning rate decay)
1.mini-batch size 表示每次都只筛选一部分作为训练的样本,进行训练,遍历一次样本的次数为(样本数/单次样本数目) 当mini-batch size 的数量通常介于1,m 之间 当 ...
- learning rate warmup实现
def noam_scheme(global_step, num_warmup_steps, num_train_steps, init_lr, warmup=True): ""& ...
- pytorch learning rate decay
关于learning rate decay的问题,pytorch 0.2以上的版本已经提供了torch.optim.lr_scheduler的一些函数来解决这个问题. 我在迭代的时候使用的是下面的方法 ...
- machine learning (5)---learning rate
degugging:make sure gradient descent is working correctly cost function(J(θ)) of Number of iteration ...
- 深度学习: 学习率 (learning rate)
Introduction 学习率 (learning rate),控制 模型的 学习进度 : lr 即 stride (步长) ,即反向传播算法中的 ηη : ωn←ωn−η∂L∂ωnωn←ωn−η∂ ...
随机推荐
- 使用sqlyog将sql server 迁移到mysql
使用软件工具sqlyog(64位) sqlyog 迁移步骤 1.使用sqlyog连接目标数据库 连接目标数据库 2.选择目标数据库(需要先把表结构建好,从SQL Server同步表结构也可以使用工具, ...
- Java NIO学习与记录(六): NIO线程模型
NIO线程模型 上一篇说的是基于操作系统的IO处理模型,那么这一篇来介绍下服务器端基于IO模型和自身线程的处理方式. 一.传统阻塞IO模型下的线程处理模式 这种处理模型是基于阻塞IO进行的,上一篇讲过 ...
- 关于ubuntu环境下gcc使用的几点说明
sudo apt-get build-dep gcc //安装gcc编译器 /* 假设已经创建hello.c文件 */ //方法一 $gcc hello.c //将源文件直接编译成文件名为a.out的 ...
- HihoCoder - 1445 后缀自动机 试水题
题意:求子串个数 SAM中每个子串包含于某一个状态中 对于不同的状态\(u,v\),\(sub(u)∩sub(v)=NULL\) 因此答案就是对于所有的状态\(st\),\(ans=\sum_{st} ...
- java翻译到mono C#实现系列(1) 重写返回键按下的事件
今天看到群里的朋友问怎么按下返回键的时候提示信息,百度了下,就参考网上一个java版示例做了.没啥技术含量,就权当丰富下mono for android的小代码. 直接在mono新建的APP上修改的. ...
- 关于Java 下 Snappy压缩存文件
坑点: 压缩后的byte 数组中会有元素是负数,如果转化成String 存入文件,然后再读取解压缩还原,无法得到原来的结果,甚至是无法解压缩. 原因分析: String 底层是由char 数组构成的, ...
- 定时删除elasticsearch索引
从去年搭建了日志系统后,就没有去管它了,最近发现大半年各种日志的index也蛮多的,就想着写个脚本定时清理一下,把一些太久的日志清理掉. 脚本思路:通过获取index的尾部时间与我们设定的过期时间进行 ...
- uvm_config_db在UVM验证环境中的应用
如何在有效的使用uvm_config_db来搭建uvm验证环境对于许多验证团队来说仍然是一个挑战.一些验证团队完全避免使用它,这样就不能够有效利用它带来的好处:另一些验证团队却过多的使用它,这让验证环 ...
- 图解ARP协议(五)免费ARP:地址冲突了肿么办?
一.免费ARP概述 网络世界纷繁复杂,除了各种黑客攻击行为对网络能造成实际破坏之外,还有一类安全问题或泛安全问题,看上去问题不大,但其实仍然可以造成极大的杀伤力.今天跟大家探讨的,也是技术原理比较简单 ...
- rails学习笔记: rake db 相关命令
rails学习笔记: rake db 命令行 rake db:*****script/generate model task name:string priority:integer script/g ...