python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1、问题描述:
爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表
2、思路分析:
发送请求--获取数据--解析数据--存储数据
1、目标网址:https://sz.lianjia.com/ershoufang/
2、利用requests.get()方法向链家深圳二手房首页发送请求,获取首页的HTML源代码
#目标网址
targetUrl = "https://sz.lianjia.com/ershoufang/"
#发送请求,获取响应
response = requests.get(targetUrl).text
3、利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice
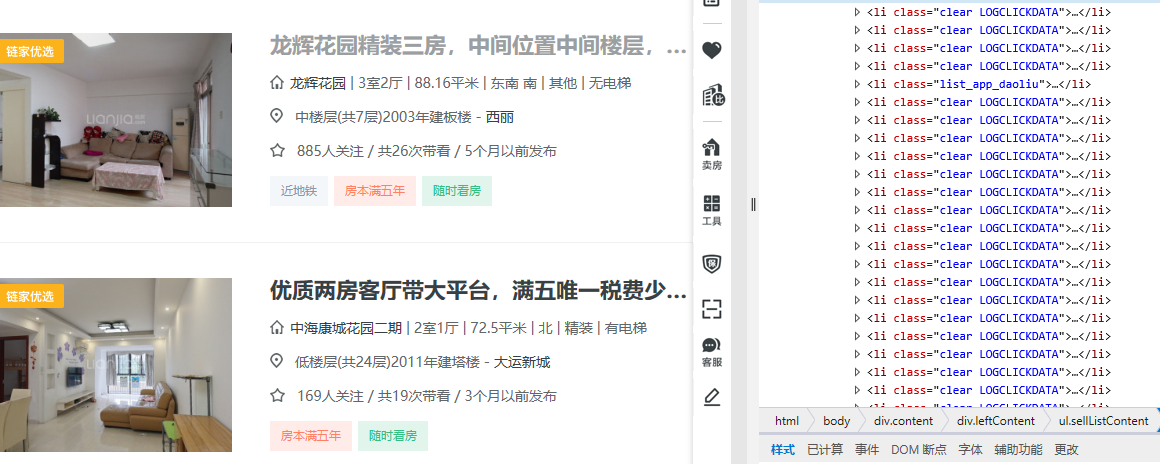
(1)首先看一下链家深圳二手房网页的结构,可以很容易发现链家的规则,每个二手房的详细信息都在<li class="clear LOGCLICKDATA">中,所以我们只需要解析出这个class中包含的详细信息即可。

'''利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice'''
soup = BeautifulSoup(response, "html.parser")
houseInfo = soup.find_all("div", class_ = "houseInfo")
priceInfo = soup.find_all("div", class_ = "priceInfo")
floodInfo = soup.find_all("div", class_ = "flood")
name = [house.text.split("|")[0].strip() for house in houseInfo]
houseType = [house.text.split("|")[1].strip() for house in houseInfo]
area = [house.text.split("|")[2].strip() for house in houseInfo]
direction = [house.text.split("|")[3].strip() for house in houseInfo]
flood = [flo.text.split("-")[0] for flo in floodInfo]
href = [house.find("a")["href"] for house in houseInfo]
totalPrice = [(re.findall("\d+", price.text))[0] for price in priceInfo]
unitPrice = [(re.findall("\d+", price.text))[1] for price in priceInfo]
#将爬取到的所有二手房的详细信息整合到house列表中
house = [name, href, houseType, area, direction, flood, totalPrice, unitPrice]
4、将数据存储到Excel表格中
#将二手房的详细信息存储到Excel表格Lianjia_I.xlsx中
workBook = xlwt.Workbook(encoding="utf-8") #创建Excel表,并确定编码方式
sheet = workBook.add_sheet("Lianjia_I") #新建工作表Lianjia_I
headData = ["小区名称", "链接", "户型", "面积", "朝向", "楼层", "价格(万)", "单价"] #表头信息
for col in range(len(headData)):
sheet.write(0, col, headData[col])
for raw in range(1, len(name)):
for col in range(len(headData)):
sheet.write(raw, col, house[col][raw-1])
workBook.save(".\Lianjia_I.xlsx")
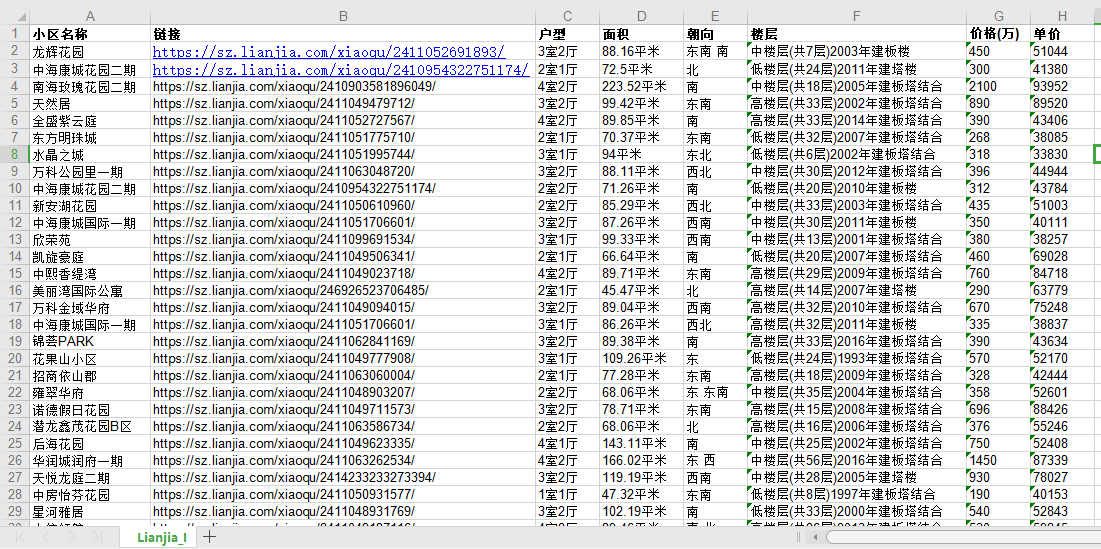
3、效果展示
4、完整代码:
# -* coding: utf-8 *-
# author: wangshx6
# date: 2018-11-04
# description: 爬取链家深圳二手房首页的房子名称、户型、面积、价格等详细信息
import requests
import re
import xlwt
from bs4 import BeautifulSoup
# 目标网址
targetUrl = "https://sz.lianjia.com/ershoufang/"
#发送请求,获取响应
response = requests.get(targetUrl).text
'''利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice'''
soup = BeautifulSoup(response, "html.parser")
houseInfo = soup.find_all("div", class_ = "houseInfo")
priceInfo = soup.find_all("div", class_ = "priceInfo")
floodInfo = soup.find_all("div", class_ = "flood")
name = [house.text.split("|")[0].strip() for house in houseInfo]
houseType = [house.text.split("|")[1].strip() for house in houseInfo]
area = [house.text.split("|")[2].strip() for house in houseInfo]
direction = [house.text.split("|")[3].strip() for house in houseInfo]
flood = [flo.text.split("-")[0] for flo in floodInfo]
href = [house.find("a")["href"] for house in houseInfo]
totalPrice = [(re.findall("\d+", price.text))[0] for price in priceInfo]
unitPrice = [(re.findall("\d+", price.text))[1] for price in priceInfo]
house = [name, href, houseType, area, direction, flood, totalPrice, unitPrice]
# print(href, name, houseType, area, direction, totalPrice, unitPrice)
#将数据列表存储到Excel表格Lianjia_I.xlsx中
workBook = xlwt.Workbook(encoding="utf-8")
sheet = workBook.add_sheet("Lianjia_I")
headData = ["小区名称", "链接", "户型", "面积", "朝向", "楼层", "价格(万)", "单价"]
for col in range(len(headData)):
sheet.write(0, col, headData[col])
for raw in range(1, len(name)):
for col in range(len(headData)):
sheet.write(raw, col, house[col][raw-1])
workBook.save(".\Lianjia_I.xlsx")
python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息的更多相关文章
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- python爬虫:爬取链家深圳全部二手房的详细信息
1.问题描述: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中 2.思路分析: (1)目标网址:https://sz.lianjia.com/ershoufang/ (2)代码结构 ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- 43.scrapy爬取链家网站二手房信息-1
首先分析:目的:采集链家网站二手房数据1.先分析一下二手房主界面信息,显示情况如下: url = https://gz.lianjia.com/ershoufang/pg1/显示总数据量为27589套 ...
- python 爬虫 requests+BeautifulSoup 爬取巨潮资讯公司概况代码实例
第一次写一个算是比较完整的爬虫,自我感觉极差啊,代码low,效率差,也没有保存到本地文件或者数据库,强行使用了一波多线程导致数据顺序发生了变化... 贴在这里,引以为戒吧. # -*- coding: ...
- <爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况: 代码: import requests from requests.exceptions import RequestException from bs4 import Beautiful ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- python爬虫——利用BeautifulSoup4爬取糗事百科的段子
import requests from bs4 import BeautifulSoup as bs #获取单个页面的源代码网页 def gethtml(pagenum): url = 'http: ...
随机推荐
- ios 开发常用函数
rand() ----随机数 abs() / labs() ----整数绝对值 fabs() / fabsf() / fabsl() ----浮点数绝对值 floor() / floorf() / f ...
- Object公用方法
Object是所有类的父类,任何类都默认继承Object. Object类到底实现了哪些方法? 1.clone方法 保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否 ...
- Spring文件上传Demo
package com.smbea.controller; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
- TP5.0搭建restful API 应用
1.配置环境变量,如果没配置会显示如下错误. 配置方法 1)右键此电脑-> 属性-> 高级系统设置->环境变量->Path 2)在Path后加上php目录的名称 如:E:\PH ...
- sharepoint2007就地升级2010系列(二)环境概述及升级前准备
环境介绍:1台2GB的虚机 现在是windows server 2008 sp2 X64 +SQL 2005+SQL2005 sp3+sharepoint2007+sharepoint2007SP2 ...
- 栅格那点儿事(四D)
统计值与空值 在上一篇的内容里反复提到了一个统计值.那这个统计值是怎么来的,具体是干嘛用的呢? 统计值主要就是用于栅格数据的显示和重分类,顾名思义就是一个波段中所有像元值的一个统计信息,最大值,最小值 ...
- zabbix web端有数据但是没有图形
zabbix web端有数据但是没有图形 我遇到的情况是,在配置 zabbix 网站目录时,修改了zabbix 目录的所有者和所属组,以使得 zabbix/conf/zabbix.conf.php 文 ...
- centos部署vue项目
参考链接 nodejs服务器部署教程二,把vue项目部署到线上 打包 #在本地使用以下命令,打包 npm run build #打包之后本地会出现dist文件夹.将dist文件夹以及package.j ...
- winxp如何开启SNMP服务
1.先安装SNMP组件 开始——> 控制面板——>添加或删除程序——>添加/删除windows组件——>管理和监视工具(前面方框选择后)——>详细信息——>简 ...
- 笨办法学Python(三十一)
习题 31: 作出决定 这本书的上半部分你打印了一些东西,而且调用了函数,不过一切都是直线式进行的.你的脚本从最上面一行开始,一路运行到结束,但其中并没有决定程序流向的分支点.现在你已经学了 if, ...