<爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况:
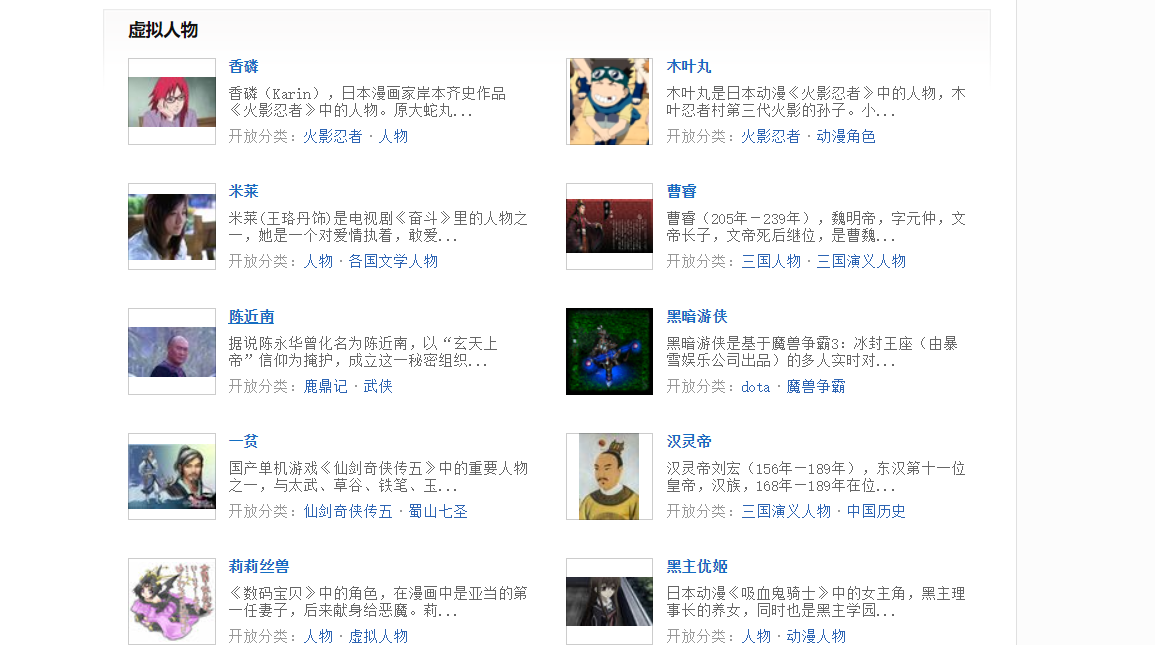
代码:
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup as bs
import re
import time
import pymysql def get_one_page(url):
#得到一页的内容
try:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
return None def parse_one_page(html):
#使用BeautifuSoup解析一页的内容
soup = bs(html,'lxml')
for data in soup.find_all('div',class_="photo"):
name = data.a['title']
href = "https://baike.baidu.com"+data.a['href']
img = data.img['src']
#有些人物没有图片,图片链接有误需要拼接
if re.search("^/static",img):
img ="https://baike.baidu.com" + img
yield {
'name':name,
'href':href,
'img':img
} def write_mysql(item):
#写入Mysql数据库
conn = pymysql.connect(
host='localhost',
user='root',
password='',
database='baidu',
charset='utf8' # 别写成utf-8
)
cursor = conn.cursor() # 建立游标 sql = "insert into baidu_baike(name,href,img) values(%s,%s,%s)"
cursor.execute(sql,(item['name'],item['href'],item['img'])) # 注意excute的位置参数的问题
conn.commit() # 修改值的时候,一定需要commit
cursor.close() # 关闭
conn.close() # 关闭 def main(url):
#主函数
html = get_one_page(url)
items = parse_one_page(html)
for item in items:
write_mysql(item) if __name__ == '__main__':
#分析URL构成,拼接URL
for i in range(1,7):
url = "http://baike.baidu.com/fenlei/虚拟人物?limit=30&index=" + str(i) + "&offset=" + str(
30 * (int(i) - 1)) + "# gotoList"
main(url)
print('正在爬取第%s页'%i)
time.sleep(1)
print("全部写入成功!")
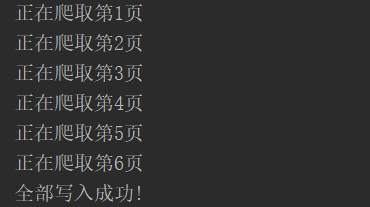
运行结果:
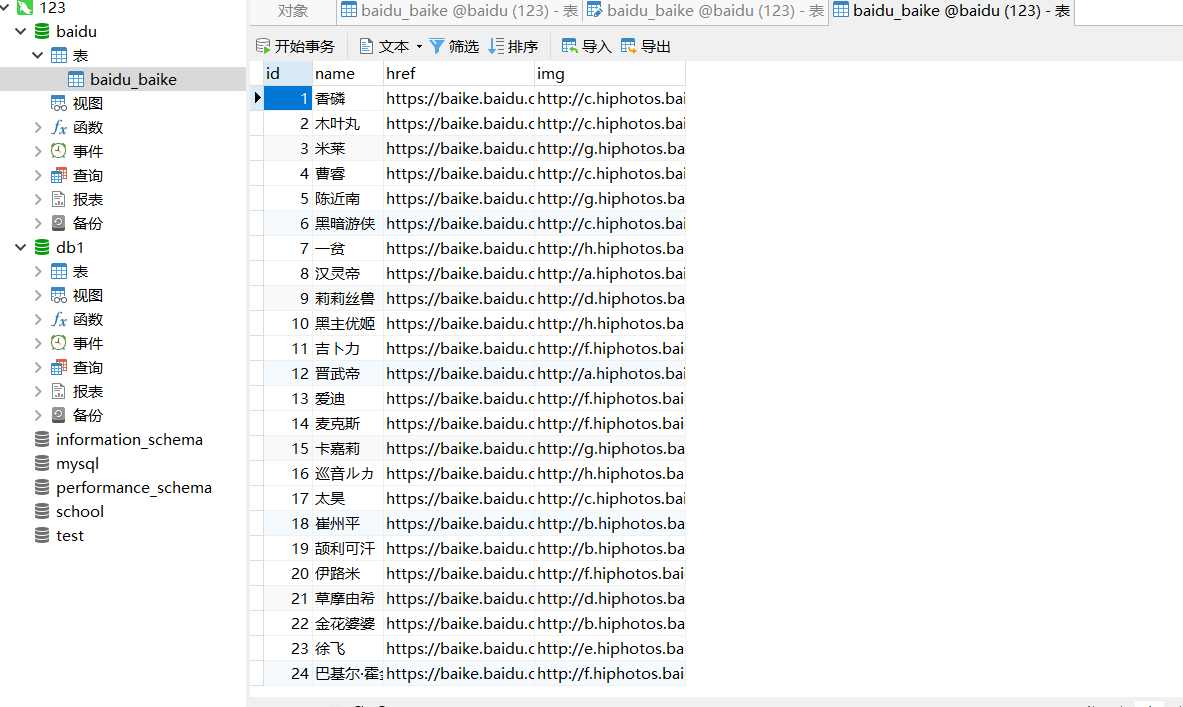
mysql数据库结果:
<爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库的更多相关文章
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- java 如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)
这是老师所布置的作业 说一下我这里的爬去并非能把百度词条上的内容一字不漏的取下来(而是它分享链接的一个主要内容概括...)(他的主要内容我爬不到 也不想去研究大家有好办法可以call me) 例如 互 ...
随机推荐
- Flutter 类似viewDidAppear 的任务处理
前言 在任务之中 ,有些实时任务比较重的需求,需要在类似 iOS viewDidAppear 里面执行数据请求任务,如:上一个页面返回pop 后执行网络请求任务.在flutter中如何实现呢? 目前 ...
- input的placeholder颜色修改
input[type=text]::-webkit-input-placeholder { /* WebKit browsers / color: #999; } input[type=text]:- ...
- vba增删改查数据库
你在EXCEL中增加一个列名为ID,后在VBA中写以下代码,并引用Microsoft ActiveX Data Objects 2.8后执行Public Sub 写入SQL2008()Dim cnn ...
- Android 开发 框架系列 OkHttp拦截器
前言 此篇博客只讲解okhttp的拦截器功能的详细使用,如果你还不太了解okhttp可以参考我另外一篇博客 Android 开发 框架系列 OkHttp使用详解 添加Interceptor的简单例子 ...
- ES5给object扩展的一些静态方法
1. Object.create(prototype[, descriptors]) : 创建一个新的对象 1). 以指定对象为原型创建新的对象 2). 指定新的属性, 并对属性进行描述 value ...
- [JZOJ1904] 【2010集训队出题】拯救Protoss的故乡
题目 题目大意 给你一个树形的网络,每条边从父亲流向儿子.根节点为原点,叶子节点流向汇点,容量为无穷大. 可以给一些边扩大容量,最多总共扩大\(m\)容量.每条边的容量有上限. 求扩大容量后最大的最大 ...
- 【JZOJ6342】Tiny Counting
description analysis 首先不管\(a,b,c,d\)重复的情况方案数是正逆序对之积 如果考虑\(a,b,c,d\)有重复,只有四种情况,下面括号括起来表示该位置重复 比如\(\{a ...
- scala 中List的简单使用
/** * scala 中List的使用 * */ object ListUse { def main(args: Array[String]): Unit = { def decorator(l:L ...
- 数据库实例性能调优利器:Performance Insights
Performance Insights是什么 阿里云RDS Performance Insights是RDS CloudDBA产品一项专注于用户数据库实例性能调优.负载监控和关联分析的利器,以简单直 ...
- maven项目引入外部第三方jar包,引入、本地编译、第三方jar一起打到jar中、在linux机器中解决classnotfound(配置classpath),笔记整理。
文章目录 引用的第三方jar的目录结构(示例) 引入第三方jar进行dependency使项目内能import 本地编译 第三方jar一起打到jar中 在linux机器中解决classnotfound ...