Python数据分析之pandas学习(基础操作)
一.pandas数据结构介绍
在pandas中有两类非常重要的数据结构,即序列Series和数据框DataFrame。Series类似于numpy中的一维数组,
除了通吃一维数组可用的函数或方法,而且其可通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame
类似于numpy中的二维数组,同样可以通用numpy数组的函数和方法,而且还具有其他灵活应用,后续会介绍到。
二.pandas数据结构之Series
#使用模块之前先导入
import pandas as pd
from pandas import Series
from pandas import DataFrame
import numpy as np
1.series
Series是一种类似与一维数组的对象,由下面两部分组成
values:一组数据(ndarray)
index:相关的数据索引标签
1)Series的创建
两种创建方式:
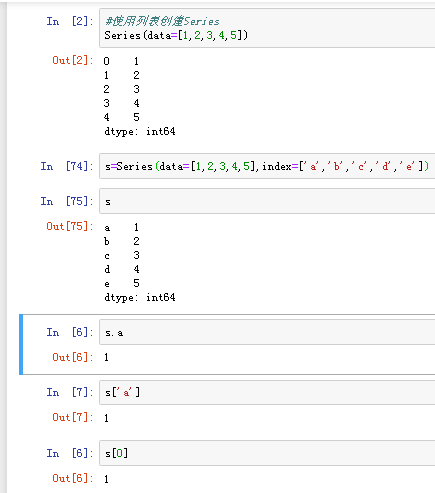
(1)由列表或numpy数组创建
默认索引为0到n-1的整形索引
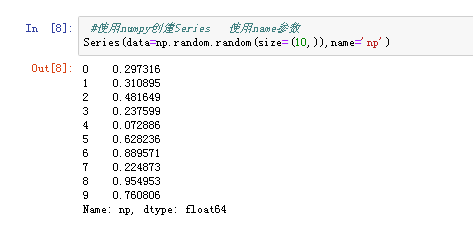
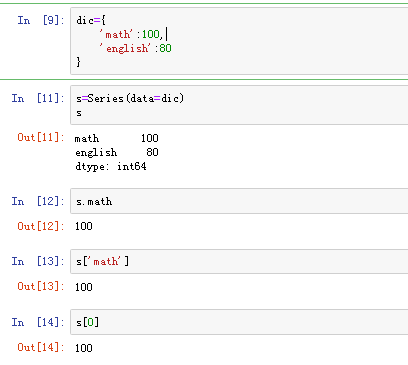
(2)由字典创建:不能在使用index.但是依然存在默认索引 注意:数据源必须为一维数据
2)Series的索引和切片
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是一个Series类型)
(1) 显式索引
使用index中的元素作为索引值
使用s.loc[](推荐):注意,loc中括号中放置的一定是显式索引
注意:此时是闭区间
(2)隐式索引:
使用整数作为索引值
使用.iloc[](推荐) iloc中括号中放置的必须是隐式索引
注意:此时是半开区间

切片:隐式索引切片和显式索引切片
显式索引切片:index和loc
隐式索引切片:整数索引值和iloc
3)Series的基本概念
可以把Series看成是一个有序的字典
向Series增加一行:相当于给字典增加一组键值对
可以通过shape,size,index,values等得到series的属性

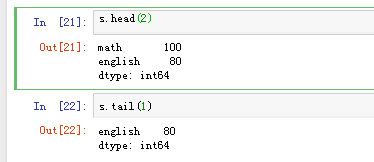
可以使用s.head()和s.tail()分别查看前n个值和后n个值:
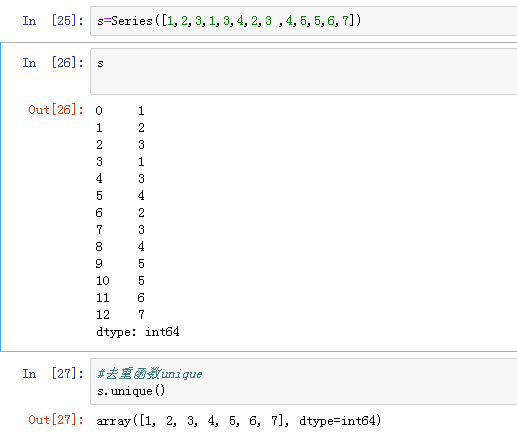
对Series元素进行去重:
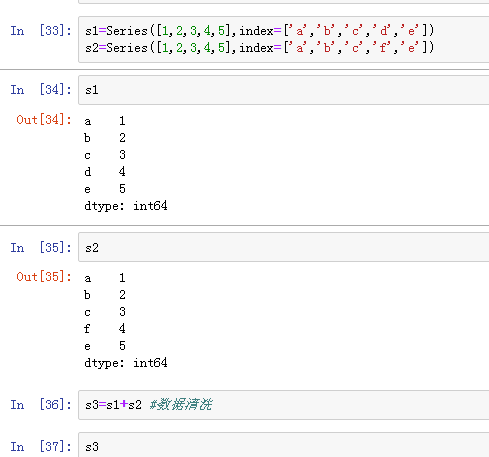
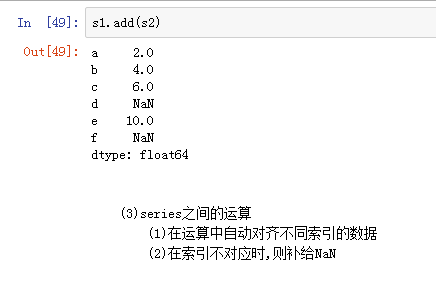
当索引没有对应值时,可能出现缺失数据NaN(not a number)的情况 使得两个Series进行相加:

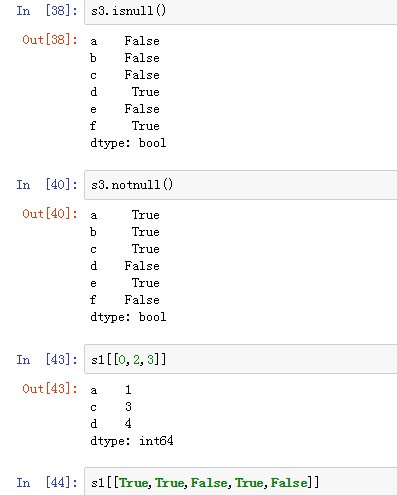
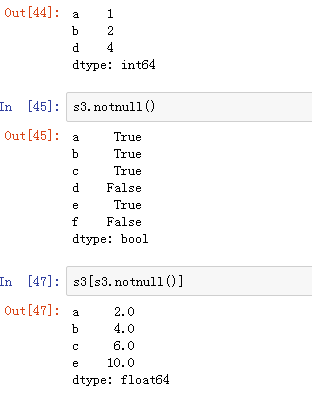
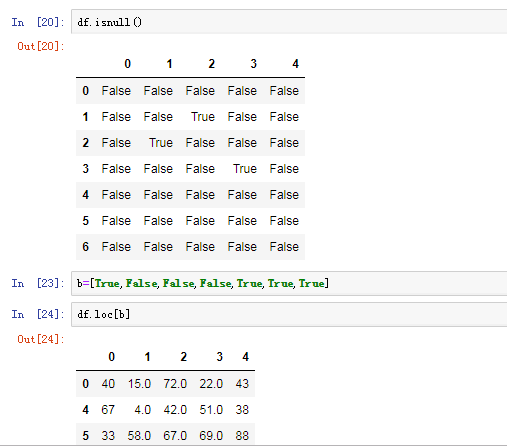
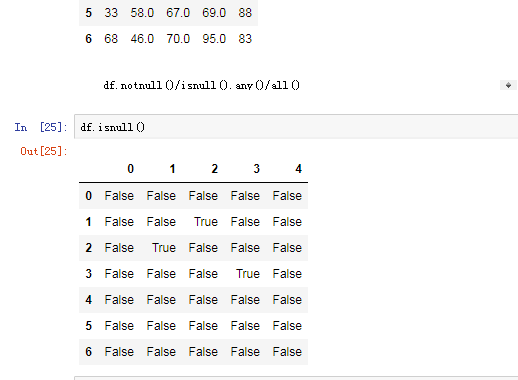
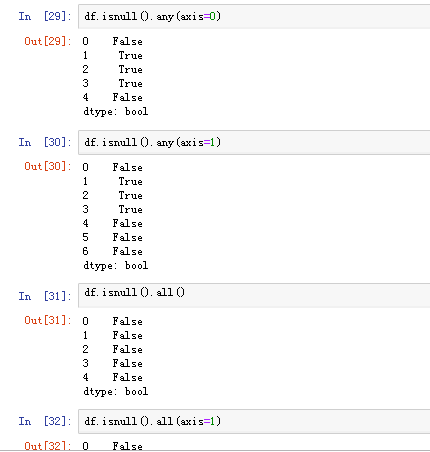
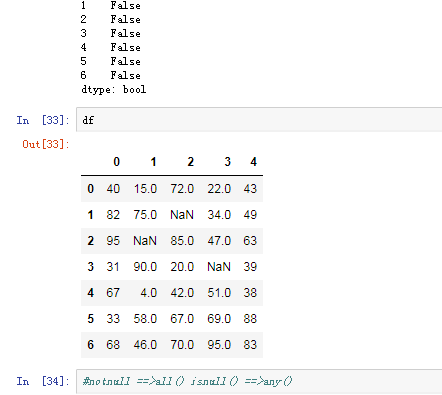
可以使用pd.isnull(),pd.notnull(),或者s.isnull(),notnull(),函数检测缺失数据
4)Series的运算 (1)+ - * / (2) add() sub() mul() div() :s1.add(s2,fill_value=0)
三.pandas数据结构之DataFrame
DataFrame是一个[表格型]的数据结构.DataFrame由按一定顺序排列的多列数据组成.设计之初也是将Series的使用场景从一维拓展到多维.DataFrame既有的行索引,又有列索引
行索引:index
列索引:columns
值:values
1)DataFrame的创建
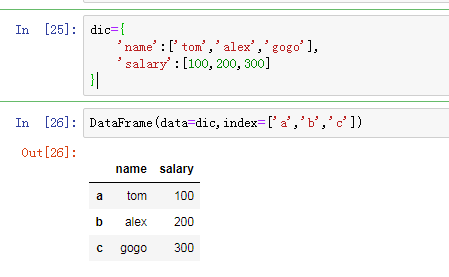
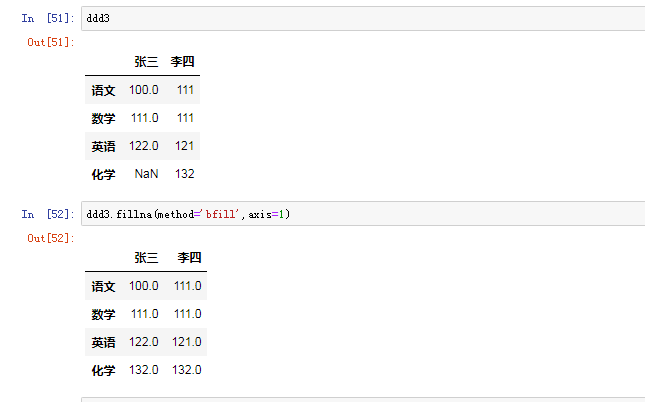
最常用的方法是传递一个字典创建.DataFrame以字典的键作为每一[列]的名称,
以字典的值(一个数组)作为每一列
此外,DataFrame会自动 加上每一行的索引.
使用字典创建的\DataFrame后,则columns(列索引)参数将不可被使用
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN
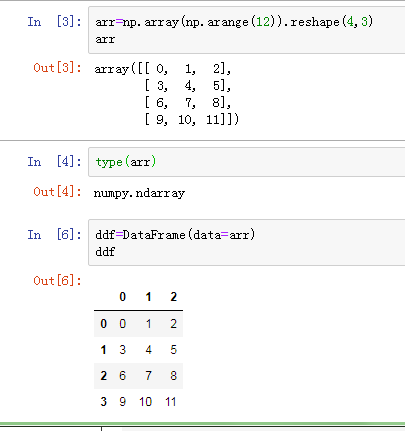
(1)使用numpy创建DataFrame:

Dataframe的属性:
values,colunmns,index,shape

(2)使用字典创建DataFrame
(3)使用多维数组创建
2)DataFrame的索引
(1)对列进行索引
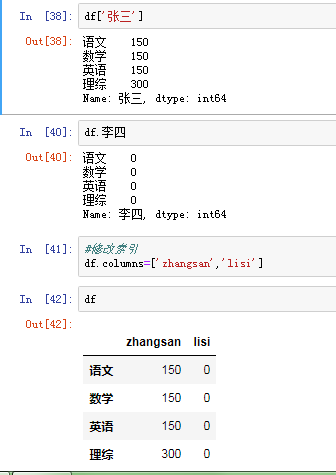
通过类似字典的方式df['q']
通过属性的方式 df.q
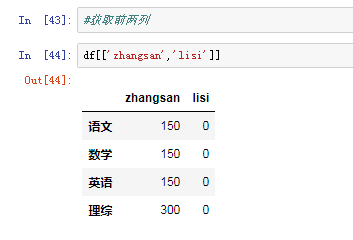
可以将DataFrame的列获取为一个Series.返回的Series拥有原DataFrame相同的索引 ,且name的属性也已经设置好了,就是相应的列名
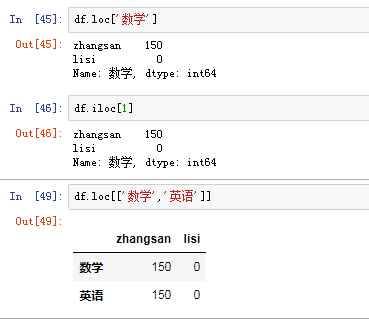
(2)对行进行索引 使用.loc[]加index来进行行索引(显示索引)
使用.iloc[]加整数来进行行索引(隐式索引)
同样返回一个Series,index为原来的columns
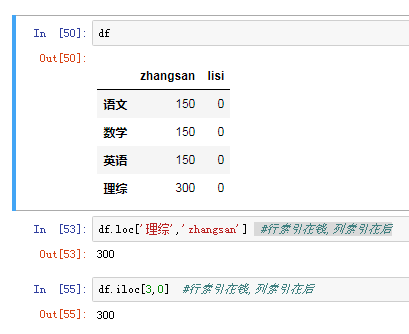
(3)对元素索引的方法 使用列索引
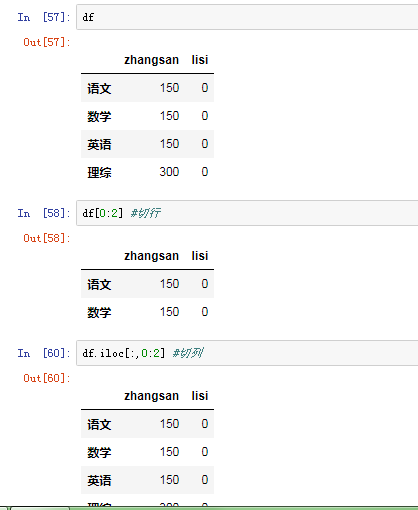
使用行索引(iloc[3,1] or loc ['c','q']) 行索引在前,列索引在后
3)切片 注意: 直接使用中括号时候: 索引表示的是列索引,切片表示的是行切片
4)DataFrame的运算
同Series一样:
在运算中自自动对齐不同索引的数据
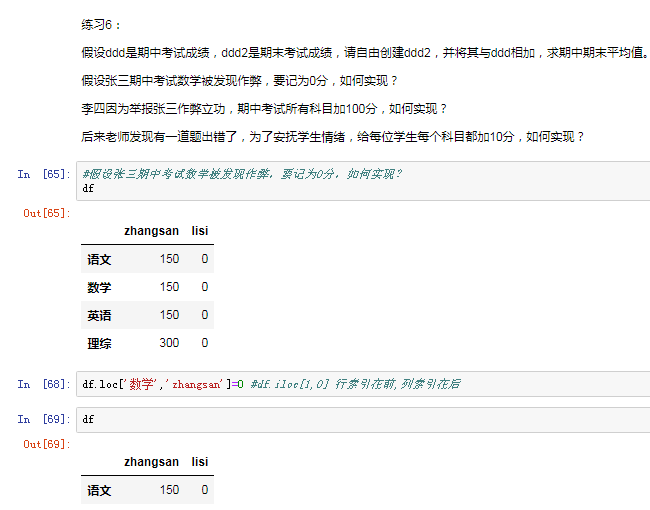
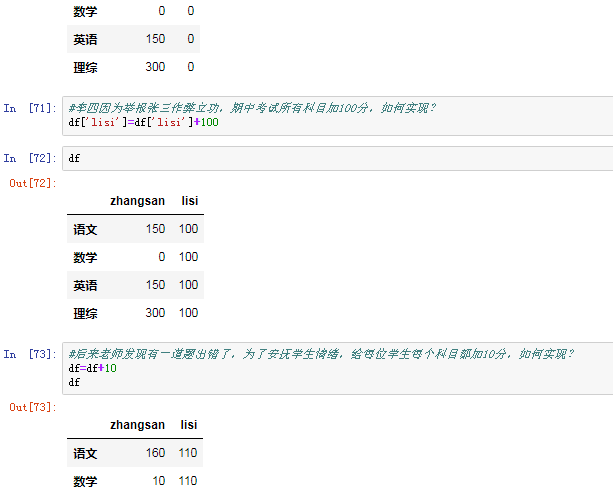
如果索引不对应,则补给NaN 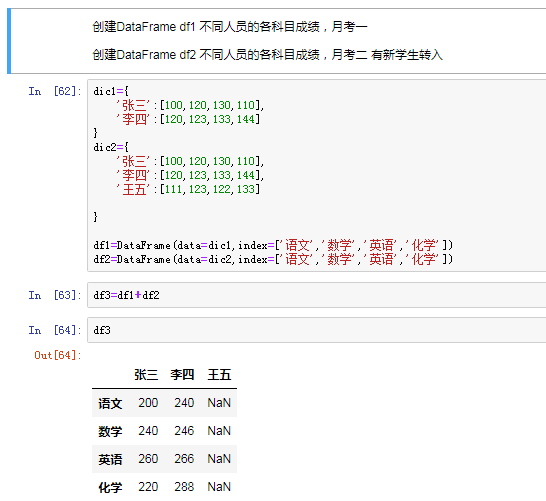
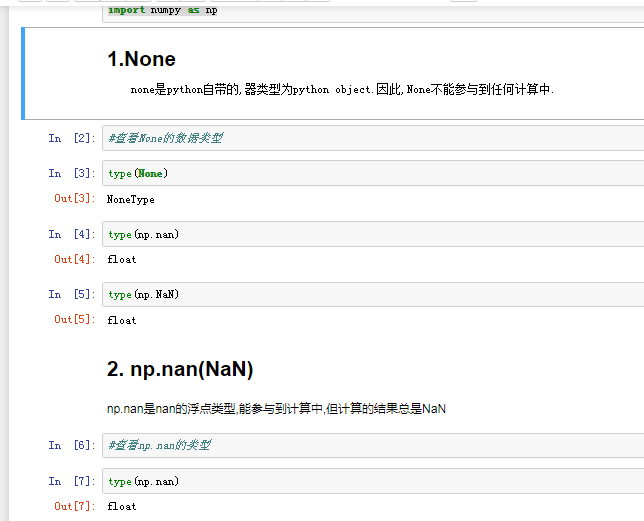
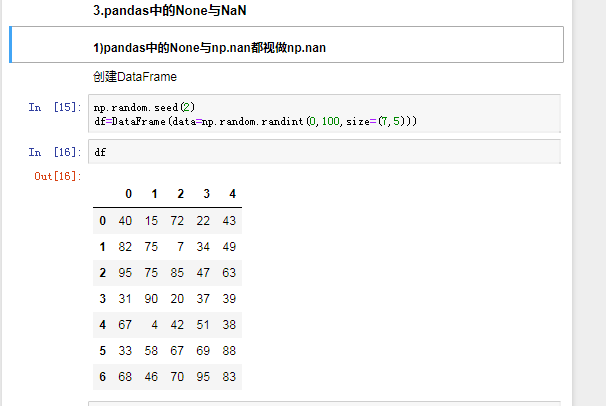
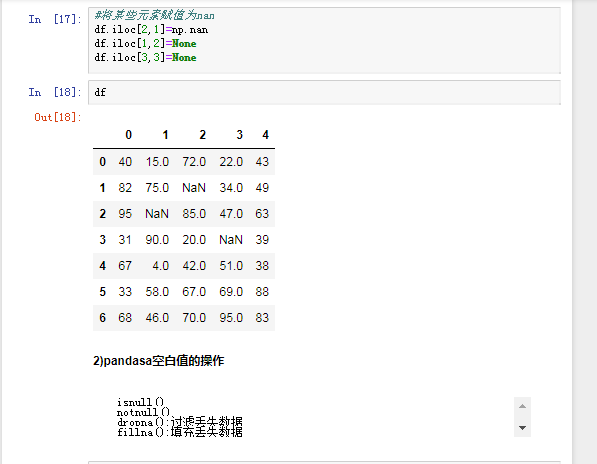
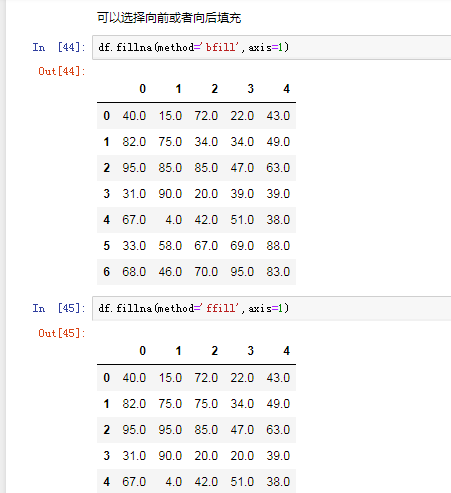
四.pandas之丢失数据的处理
有两种丢失数据
None
np.nan(NaN)



Python数据分析之pandas学习(基础操作)的更多相关文章
- Python数据分析之pandas学习
Python中的pandas模块进行数据分析. 接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利 ...
- 08:Python数据分析之pandas学习
1.1 数据结构介绍 参考博客:http://www.cnblogs.com/nxld/p/6058591.html 1.pandas介绍 1. 在pandas中有两类非常重要的数据结构,即序列Ser ...
- Python数据分析库pandas基本操作
Python数据分析库pandas基本操作2017年02月20日 17:09:06 birdlove1987 阅读数:22631 标签: python 数据分析 pandas 更多 个人分类: Pyt ...
- Python数据分析之pandas基本数据结构:Series、DataFrame
1引言 本文总结Pandas中两种常用的数据类型: (1)Series是一种一维的带标签数组对象. (2)DataFrame,二维,Series容器 2 Series数组 2.1 Series数组构成 ...
- 数据分析05 /pandas的高级操作
数据分析05 /pandas的高级操作 目录 数据分析05 /pandas的高级操作 1. 替换操作 2. 映射操作 3. 运算工具 4. 映射索引 / 更改之前索引 5. 排序实现的随机抽样/打乱表 ...
- Pandas的基础操作(一)——矩阵表的创建及其属性
Pandas的基础操作(一)——矩阵表的创建及其属性 (注:记得在文件开头导入import numpy as np以及import pandas as pd) import pandas as pd ...
- Python 数据分析:Pandas 缺省值的判断
Python 数据分析:Pandas 缺省值的判断 背景 我们从数据库中取出数据存入 Pandas None 转换成 NaN 或 NaT.但是,我们将 Pandas 数据写入数据库时又需要转换成 No ...
- Python数据分析之Pandas操作大全
从头到尾都是手码的,文中的所有示例也都是在Pycharm中运行过的,自己整理笔记的最大好处在于可以按照自己的思路来构建矿建,等到将来在需要的时候能够以最快的速度看懂并应用=_= 注:为方便表述,本章设 ...
- Python数据分析之pandas入门
一.pandas库简介 pandas是一个专门用于数据分析的开源Python库,目前很多使用Python分析数据的专业人员都将pandas作为基础工具来使用.pandas是以Numpy作为基础来设计开 ...
随机推荐
- oracle 调整输出的列宽、行宽
调整列宽 col 列名 format a20 调整行宽 set linesize 150
- myeclipse.ini
myeclipse10 32位 我的配置 #utf8 (do not remove) #utf8 (do not remove) -startup ../Common/plugins/org.ecli ...
- 1 ffmpeg介绍
重点讲解解码的过程.FFmpeg可以进行X264编码.软编码效率是非常低的.即时你编VGA的话它的效率也很低.
- 框架之Struts2
相比较hibernate简单了许多 案例:使用Struts2框架完成登录功能 需求分析 1. 使用Struts2完成登录的功能 技术分析之Struts2框架的概述 1. 什么是Struts2的框架 * ...
- linux鸟哥的私房菜
这书还是感觉非常棒,真的是授之以渔而不是授之以鱼.我觉得只需要掌握一个命令就可以了man -k KEYWORD 比如我想查找和防火墙相关的命令,那么 man -k firewall 结果是ufw 然后 ...
- zookeeper生成节点、删除节点 For Java
源码地址https://github.com/Bellonor/myhadoop2.x/tree/master/myhadoop2.x/src/main/java/com/jamesfen/zooke ...
- linux sdcv命令
一.简介 sdcv全称为stardict console version,是终端下的词典. 二.安装 1)安装sdcv yum install -y sdcv 2)安装字典 http://www. ...
- Luogu 1081 [NOIP2012] 开车旅行
感谢$LOJ$的数据让我调掉此题. 这道题的难点真的是预处理啊…… 首先我们预处理出小$A$和小$B$在每一个城市的时候会走向哪一个城市$ga_i$和$gb_i$,我们有链表和平衡树可以解决这个问题( ...
- SDUT 3342 数据结构实验之二叉树三:统计叶子数
数据结构实验之二叉树三:统计叶子数 Time Limit: 1000MS Memory Limit: 65536KB Submit Statistic Problem Description 已知二叉 ...
- IDEA内嵌Jetty启动SpringMvc项目
这段时间本意是想要研究一下Netty的多线程异步NIO通讯框架,看完原理想要做下源码分析.查找资料发现Jetty框架底层支持用Netty做web请求的多线程分发处理,于是就筹备着将Jetty框架内嵌到 ...