Java原子类中CAS的底层实现
Java原子类中CAS的底层实现
从Java到c++到汇编, 深入讲解cas的底层原理.
介绍原理前, 先来一个Demo
以AtomicBoolean类为例.先来一个调用cas的demo.
主线程在for语句里cas忙循环, 直到cas操作成功返回true为止.
而新开的一个县城new Thread 会在4秒后,将flag设置为true, 为了让主线程能够设置成功.(因为cas的预期值是true, 而flag被初始化为了false)
现象就是主线程一直在跑for循环. 4秒后, 主线程将会设置成功, 然后输出时间差, 然后终止for循环.
public class TestAtomicBoolean {
public static void main(String[] args) {
AtomicBoolean flag = new AtomicBoolean(false);
long start = System.currentTimeMillis();
new Thread(()->{
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag.set(true);
}).start();
for(;;){
if(flag.compareAndSet(true,false)){
System.out.println(System.currentTimeMillis() - start);
System.out.println("inner loop OK!");
break;
}
}
}
}
这里只是举了一个例子, 也许这个例子也不太恰当, 本文只是列出了这个api的调用方法而已, 重点在于介绍compareAndSet()方法的底层原理.
Java级源码AtomicBoolean.java
发现AtomicBoolean的compareAndSet()调用的是unsafe里的compareAndSwapInt()方法.
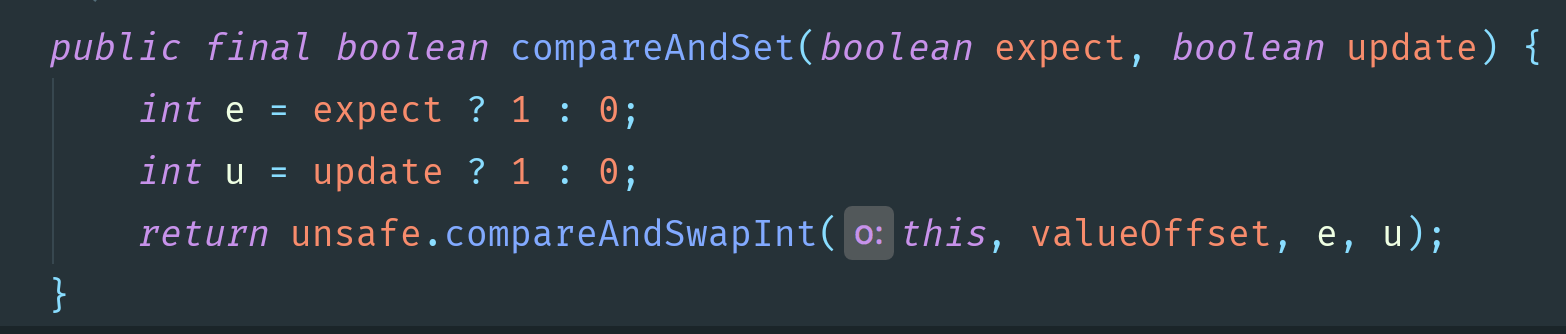
Java级源码Unsafe.java
有的同学可能好奇, 其中的unsafe是怎么来的.
在AtomicBoolean类中的静态成员变量:

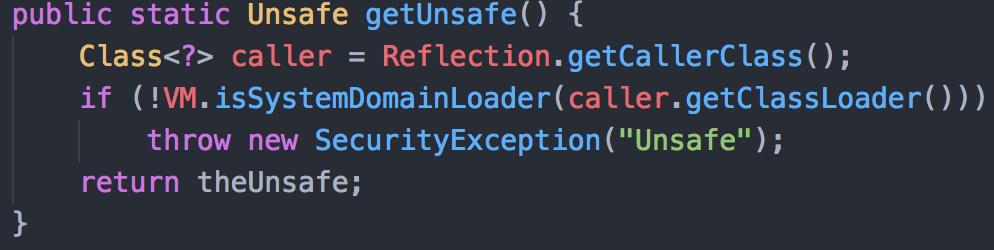
如果还要细究Unsafe.getUnsafe()是怎么实现的话....那么我再贴一份Unsafe类里的getUnsafe的代码:
首先, 在Unsafe类里, 自己就有了一个自己的实例.(而且是单例的)

然后Unsafe类里的getUnsafe()方法会进行检查, 最终会return这个单例 theUnsafe.
刚刚跑去取介绍了getUnsafe()方法...接下来继续讲解cas...
刚才说到了AtomicBoolean类里的compareAndSet()方法内部其实调用了Unsafe类里的compareAndSwapInt()方法.
Unsafe类里的compareAndSwapInt源码如下:
(OpenJDK8的源码里路径: openjdk/jdk/src/share/classes/sun/misc/Unsafe.java)
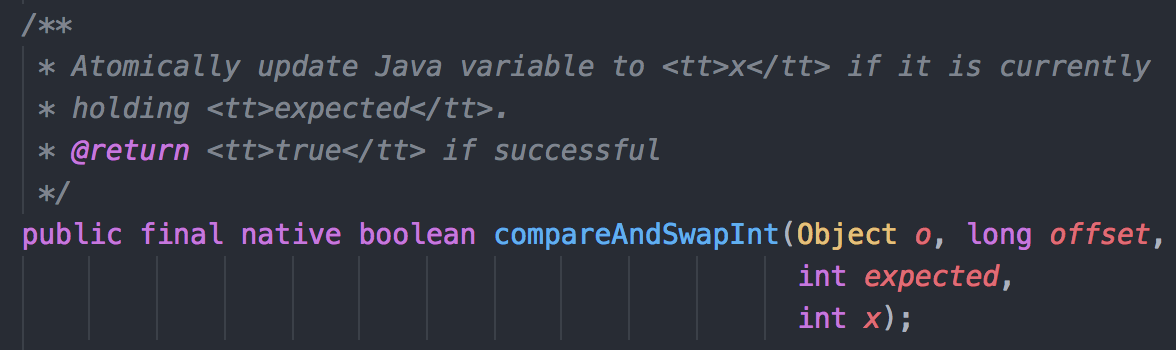
发现这里是一段native方法.说明继续看源码的话, 从这里就开始脱离Java语言了....
c++级源码Unsafe.cpp
本源码在OpenJDK8里的路径为: openjdk/hotspot/src/share/vm/prims/unsafe.cpp

(这里临时跑题一下: 如果说要细究 UNSAFE_ENTRY 是什么的话...UNSAFE_ENTRY 就是 JVM_ENTRY, 而 JVM_ENTRY 在interfaceSupport.hpp里面定义了, jni相关.如果想看的话, 源码路径在OpenJDK8中的路径是这个:
openjdk/hotspot/src/share/vm/runtime/interfaceSupport.hpp)
回到本文的主题cas....上面截图的这段代码, 看后面那一句return, 发现其中的使用到的是Atomic下的cmpxchg()方法.
c++级源码atomic.cpp
本段源码对应OpenJDK8的路径是这个: openjdk/hotspot/src/share/vm/runtime/atomic.cpp
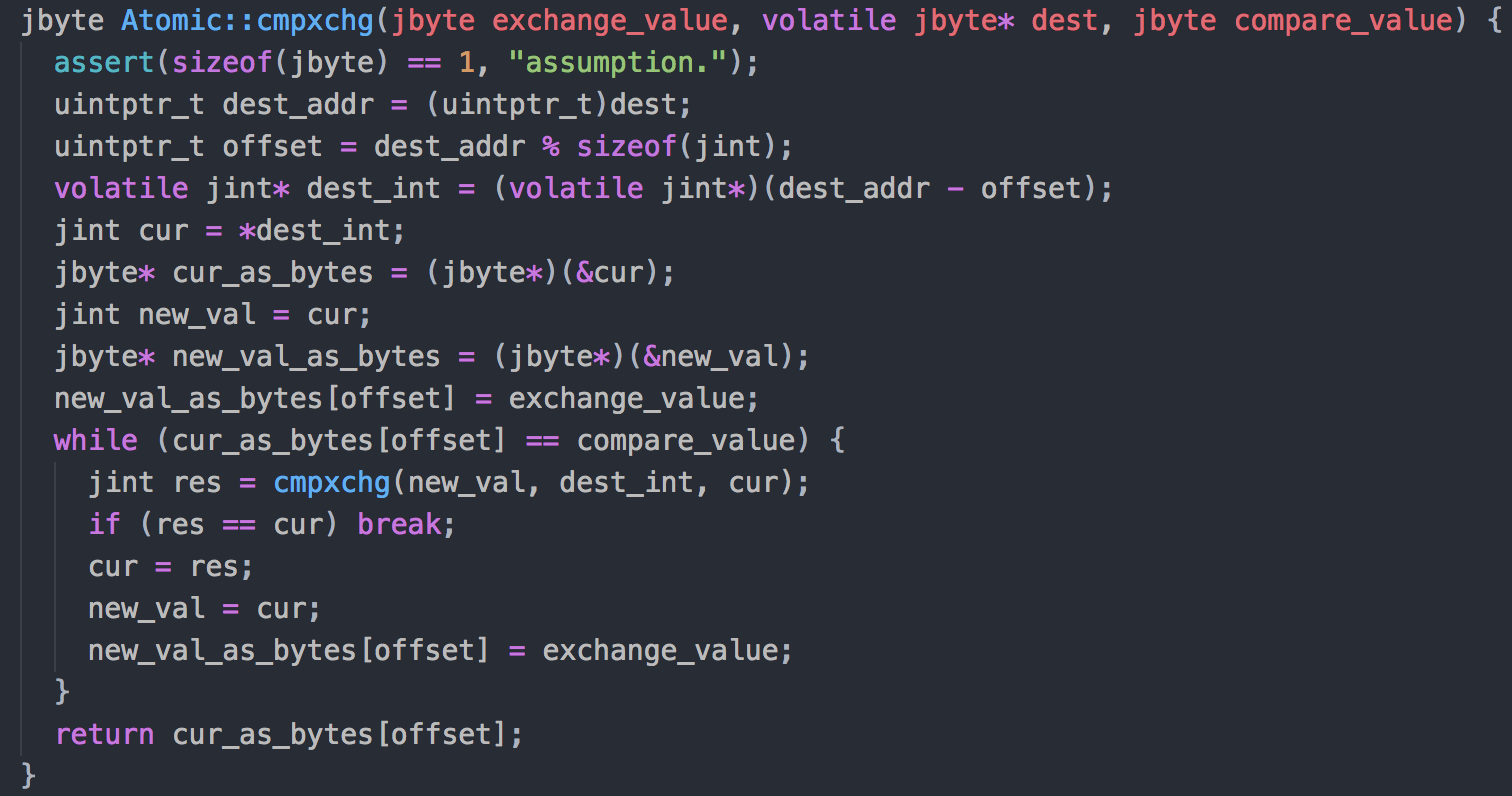
其中的cmpxchg为核心内容. 但是这句代码根据操作系统和处理器的不同, 使用不同的底层代码.

而atomic.inline.hpp里声明如下:
可见 ...不同不同操作系统, 不同的处理器, 都要走不同的cmpxchg()方法的实现.
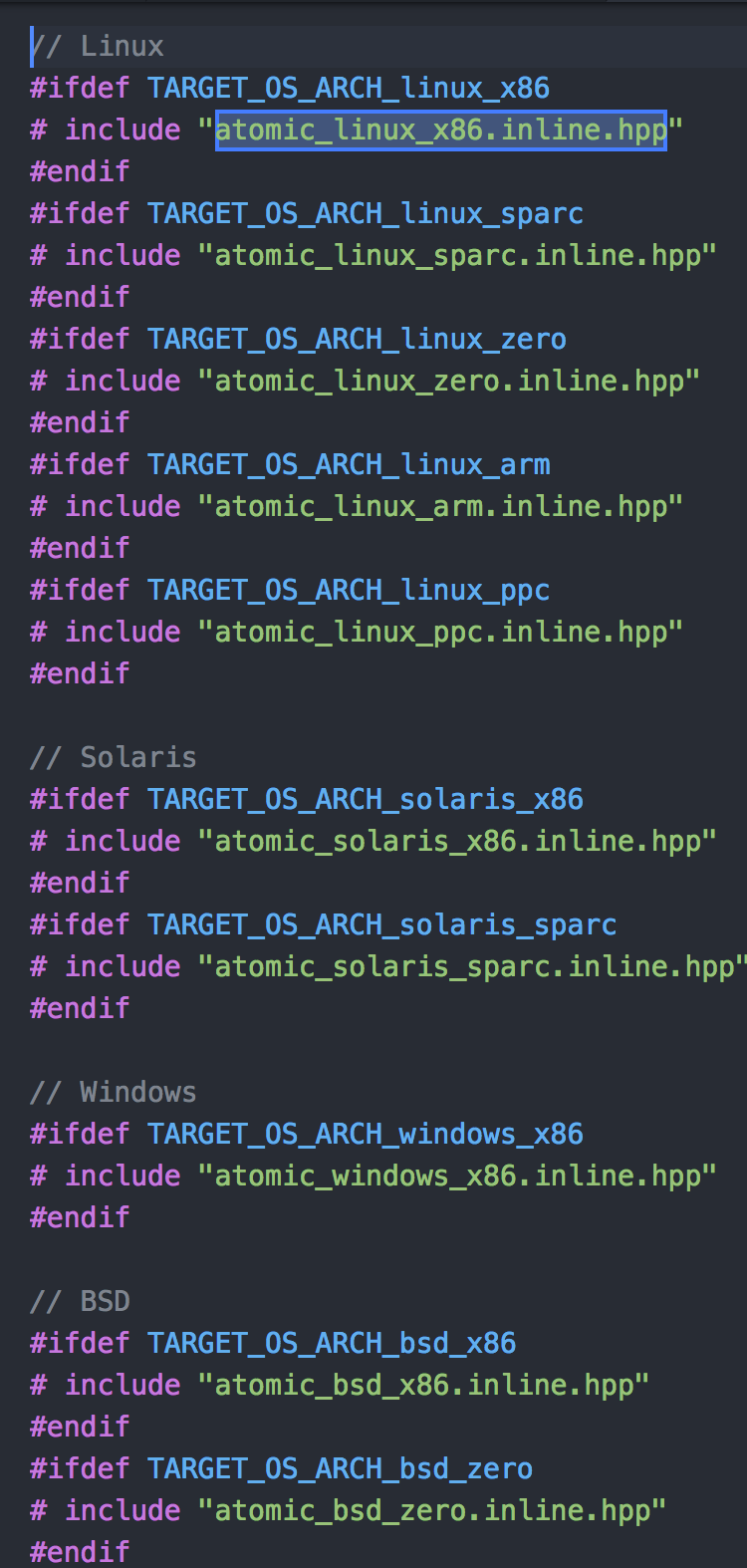
咱们接下来以其中的linux操作系统 x86处理器为例 , atomic_linux_x86.inline.hpp
汇编级源码atomic_linux_x86.inline.hpp
OpenJDK中路径如下: openjdk/hotspot/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp
看到了__asm__, 说明c++要开始内联汇编了,说明继续看代码的话, 将会是汇编语言.
这是一段内联汇编:

其中 __asm__ volatile 指示了编译器不要改动优化后面的汇编语句, 如果进行了优化(优化是为了减少访问内存, 直接通过缓存, 加快取读速度), 那么就在这段函数的周期内, 某几个变量就相当于常亮了, 其值可能会与内存中真实的值有差异.
2018.6.7更新: 10天没更新了, 由于实习结束, 这几天手头没电脑, 而且租房火车回学校等各种问题繁杂...
了解汇编指令cmpxchg
环境
怼代码之前...先把环境介绍一下...汇编的指令细节方便会有所不同, 比如__asm__ 和asm不一定一样, 又比如 asm(...) 和 asm{...} 的括号问题, 又比如 汇编指令的首操作数和第2操作数的含义是颠倒的, 也就是`mov 操作数1, 操作数2` , 要改写成`mov 操作数2, 操作数1`...反正很乱..我也不专门搞汇编, 我只能保证我这里使用g++进行编译能正常运行.(linux下或者mac下用g++编译是没问题的, windows就不知道了...)
内联汇编格式
有些同学可能会对上面突如其来的汇编语句感到迷茫...
先来一下内联汇编的语法格式:
asm volatile("Instruction List"
: Output
: Input
: Clobber/Modify);
其中的Output和Input大家很好理解, 但是Clobber/Modify是什么意思呢:
(下面关于Clobber/Modify的内容引用自:https://blog.csdn.net/dlh0313/article/details/52172833)
有时候,当你想通知GCC当前内联汇编语句可能会对某些寄存器或内存进行修改,希望GCC在编译时能够将这一点考虑进去;那么你就可以在Clobber/Modify部分声明这些寄存器或内存
大家可以看看上面图片中openJDK中的汇编代码, 里面的Clobber/Modify部分是"cc"和"memory", memory好理解, 就是内存. 那么"cc"是什么呢?
当一个内联汇编中包含影响标志寄存器eflags的条件,那么也需要在Clobber/Modify部分中使用"cc"来向GCC声明这一点
内联汇编的简单例子
接下来展示一个简单的c++内联汇编的程序: a是1000, 通过汇编来给b变量也赋值为1000
#include<iostream>
using namespace std;
int main() {
int a = 1000, b = 0;
asm("movl %1,%%eax\n"
"movl %%eax,%0\n"
: "=r"(b)
: "r" (a)
: "%eax");
cout << "a := " << a << endl;
cout << "b := " << b << endl;
return 0;
}
首先在c++里定义了a=1000, b=0;
然后看asm里的第一行冒号, 这里表示Output ` : "=r"(b) `, b是第0个参数, 等号(=)表示当前输出表达式的属性为只写, r表示寄存器
然后看asm里的第一行冒号, 这里表示Input `: "r" (a)`, a是第1个参数, r表示寄存器.
然后看asm里的第一行指令 `movl %1,%%eax\n` , 将第0个参数的值(变量a)传入到寄存器eax中
然后看asm里的第二行指令 `movl %%eax,%0\n` , 将寄存器eax的值传给第一个参数(变量b)
接下来使用c++的cout进行输出, 查看是否赋值成功, 结果如下:

再来一个简单汇编例子
用汇编给a变量赋值为100
#include<iostream>
using namespace std;
int main() {
int a = 0;
asm("movl $100,%%eax\n"
"movl %%eax,%0\n"
: "=r"(a)
: /*no input*/
: "%eax", "memory");
cout << "a := " << a << endl;
return 0;
}
(当然如果用的熟练, 就不需要使用两句mov来实现这个功能. 可以直接 movl $100, %0 ,就可以实现把100赋值给a变量了. 这里只是为了演示使用寄存器, 所以先给寄存器eax存上100, 再把寄存器的值赋值给a, 用寄存器eax做了一个中间的临时存储)
程序运行结果如下:

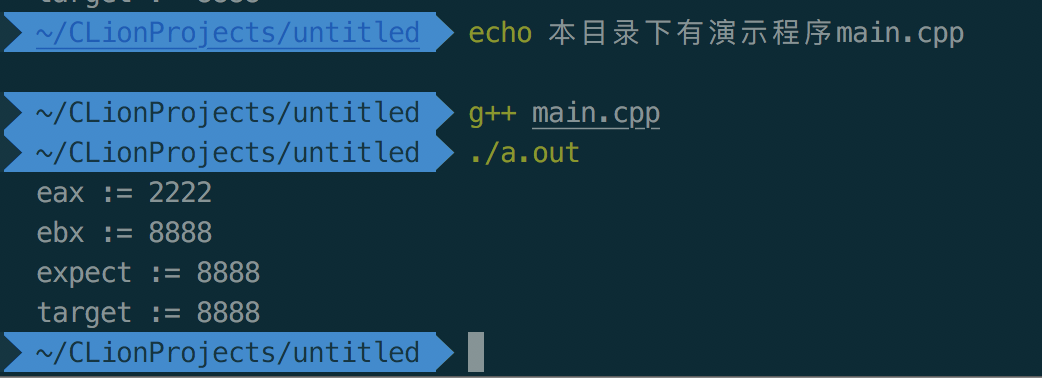
内联汇编cmpxchg(cmpxchg比对成功)
(有同学不会编译运行g++下的cpp, 我顺便也在这里做一个示范吧.....)
#include<iostream>
using namespace std;
int main() {
int cpp_eax = 0;
int cpp_ebx = 0;
int expect = 2222;
int target = 8888;
asm("movl %2, %%eax \n" /*将2222存入到eax寄存器中*/
"movl %3, %%ebx \n" /*将8888存入到ebx寄存器中*/
"cmpxchg %%ebx, %2 \n" /*如果变量expect的值与寄存器eax的值相等(成功), 那么ebx的值就赋给expect*/
"movl %%eax, %0 \n" /*将寄存器eax的值赋值给变量cpp_eax*/
"movl %%ebx, %1 \n" /*将寄存器ebx的值赋值给变量cpp_ebx*/
:"=r"(cpp_eax), "=r"(cpp_ebx), "+r"(expect) /*等于号表示可写, 加号表示可写可读*/
:"r"(target)
/*cpp_eax是%0, cpp_ebx是%1, expect是%2, target是%3*/
:"%eax", "%ebx", "memory", "cc");
cout << "eax := " << cpp_eax << endl;
cout << "ebx := " << cpp_ebx << endl;
cout << "expect := " << expect << endl;
cout << "target := " << target << endl;
}
运行方式和结果如下:
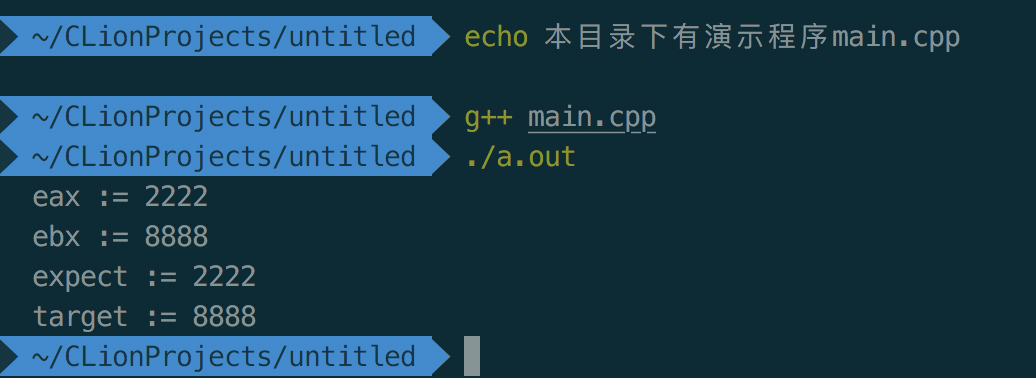
内联汇编cmpxchg(cmpxchg比对失败)
如果cmpxchg指令中的第二个操作数与寄存器eax进行比对, 发现值不一样的时候, 就会比对失败, 那么expect的值就会赋值给eax, 而expect的值保持不变.
#include<iostream>
using namespace std;
int main() {
int cpp_eax = 0;
int cpp_ebx = 0;
int expect = 2222;
int target = 8888;
asm("movl $77, %%eax \n" /*将字面量77存入到eax寄存器中*/
"movl %3, %%ebx \n" /*将8888存入到ebx寄存器中*/
"cmpxchg %%ebx, %2 \n" /*如果变量expect的值与寄存器eax的值不相等(失败), 那么expect的值就赋给eax*/
"movl %%eax, %0 \n" /*将寄存器eax的值赋值给变量cpp_eax*/
"movl %%ebx, %1 \n" /*将寄存器ebx的值赋值给变量cpp_ebx*/
:"=r"(cpp_eax), "=r"(cpp_ebx), "+r"(expect) /*等于号表示可写, 加号表示可写可读*/
:"r"(target)
/*cpp_eax是%0, cpp_ebx是%1, expect是%2, target是%3*/
:"%eax", "%ebx", "memory", "cc");
cout << "eax := " << cpp_eax << endl;
cout << "ebx := " << cpp_ebx << endl;
cout << "expect := " << expect << endl;
cout << "target := " << target << endl;
}
cmpxchg指令结论
1.指令格式: CMPXCHG 操作数1 (8位/16位/32位寄存器), 操作数2(可以是任意寄存器或者内存memory)
2.指令作用: 将累加器AL/AX/EAX(也就是%eax)中的值与第2操作数(目的操作数)比较,如果相等,第首操作数(源操作数)的值装载到第2操作数,zf置1。如果不等, 第2操作数的值装载到AL/AX/EAX并将zf清0
3.该指令只能用于486及其后继机型。
lock前缀
本段的文字理论介绍引用自(http://www.weixianmanbu.com/article/736.html):
在单处理器系统中是不需要加lock的,因为能够在单条指令中完成的操作都可以认为是原子操作,中断只能发生在指令与指令之间。
在多处理器系统中,由于系统中有多个处理器在独立的运行,即使在能单条指令中完成的操作也可能受到干扰。
在所有的 X86 CPU 上都具有锁定一个特定内存地址的能力,当这个特定内存地址被锁定后,它就可以阻止其他的系统总线读取或修改这个内存地址。这种能力是通过 LOCK 指令前缀再加上下面的汇编指令来实现的。当使用 LOCK 指令前缀时,它会使 CPU 宣告一个 LOCK# 信号,这样就能确保在多处理器系统或多线程竞争的环境下互斥地使用这个内存地址。当指令执行完毕,这个锁定动作也就会消失。
#include<iostream>
using namespace std;
int main() {
int cpp_eax = 0;
int cpp_ebx = 0;
int expect = 2222;
int target = 8888;
__asm__ __volatile__("movl $2222, %%eax \n" /*将字面量2222存入到eax寄存器中*/
"movl %3 , %%ebx \n" /*将8888存入到ebx寄存器中*/
"lock;" "cmpxchg %%ebx, %2 \n" /*如果变量expect的值与寄存器eax的值不相等(失败), 那么expect的值就赋给eax*/
"movl %%eax, %0 \n" /*将寄存器eax的值赋值给变量cpp_eax*/
"movl %%ebx, %1 \n" /*将寄存器ebx的值赋值给变量cpp_ebx*/
:"=r"(cpp_eax), "=r"(cpp_ebx), "=m"(expect) /*等于号表示可写, 加号表示可写可读*/
:"r"(target)
/*cpp_eax是%0, cpp_ebx是%1, expect是%2, target是%3*/
:"%eax", "%ebx", "memory", "cc");
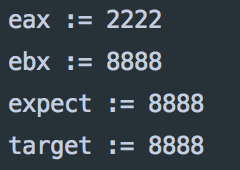
cout << "eax := " << cpp_eax << endl;
cout << "ebx := " << cpp_ebx << endl;
cout << "expect := " << expect << endl;
cout << "target := " << target << endl;
}
结果如下:
注意, 如果加lock前缀的话, 指令的第2操作数必须是存储在内存中的, 语句格式是这样` lock; cmpxchg 操作数1(寄存器), 操作数2(内存) ` .所以, expect作为output的时候是这样声明的: "=m"(expect)
如果不是操作的内存, 那么会报异常. 操作数2必须是内存...在这里卡了很久
Java原子类中CAS的底层实现的更多相关文章
- java:原子类的CAS
当一个处理器想要更新某个变量的值时,向总线发出LOCK#信号,此时其他处理器的对该变量的操作请求将被阻塞,发出锁定信号的处理器将独占共享内存,于是更新就是原子性的了. 1.compareAndSet- ...
- 源码编译OpenJdk 8,Netbeans调试Java原子类在JVM中的实现(Ubuntu 16.04)
一.前言 前一阵子比较好奇,想看到底层(虚拟机.汇编)怎么实现的java 并发那块. volatile是在汇编里加了lock前缀,因为volatile可以通过查看JIT编译器的汇编代码来看. 但是原子 ...
- 死磕 java原子类之终结篇(面试题)
概览 原子操作是指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何线程上下文切换. 原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序不可以被打乱,也不可以被切割 ...
- JUC源码学习笔记4——原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法
JUC源码学习笔记4--原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法 volatile的原理和内存屏障参考<Java并发编程的艺术> 原子类源码基于JDK8 ...
- 对Java原子类AtomicInteger实现原理的一点总结
java原子类不多,包路径位于:java.util.concurrent.atomic,大致有如下的类: java.util.concurrent.atomic.AtomicBoolean java. ...
- Java原子类AtomicInteger实现原理的一点总结
java原子类不多,包路径位于:java.util.concurrent.atomic,大致有如下的类: java.util.concurrent.atomic.AtomicBoolean java. ...
- Java原子类--AtomicLongArray
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3514604.html AtomicLongArray介绍和函数列表 在"Java多线程系列-- ...
- Java原子类操作原理剖析
◆CAS的概念◆ 对于并发控制来说,使用锁是一种悲观的策略.它总是假设每次请求都会产生冲突,如果多个线程请求同一个资源,则使用锁宁可牺牲性能也要保证线程安全.而无锁则是比较乐观的看待这个问题,它会假设 ...
- Java 原子类 java.util.concurrent.atomic
Java 原子类 java.util.concurrent.atomic 1.i++为什么是非线程安全的 i++其实是分为3个步骤:获取i的值, 把i+1, 把i+1的结果赋给i 如果多线程执行i++ ...
随机推荐
- Vue的安装及使用快速入门
一.安装vue 1.安装node.js,安装完node.js之后,npm也会自动安装 查询是否安装成功的命令: node -v npm -v 2.全局安装脚手架工具vue-cli,命令如下: npm ...
- 基于GPS数据建立隐式马尔可夫模型预测目的地
<Trip destination prediction based on multi-day GPS data>是一篇在2019年,由吉林交通大学团队发表在elsevier期刊上的一篇论 ...
- Springboot整合Kfka
1.首先在pom文件添加依赖 The managed version is 1.1.7.RELEASE The artifact is managed in org.springframework.b ...
- Step by Step Recipe for Securing Kafka with Kerberos
Short Description: Step by Step Recipe for Securing Kafka with Kerberos. Article I found it is a lit ...
- C# .NET 0配置使用Wcf(半成品)
设计原则:万物皆对象 背景:微软提供了一套强大的通信框架Wcf,了解请看百度百科:ttps://baike.baidu.com/item/Wcf/7374854?fr=aladdin 虽然这套通信框架 ...
- MySQL工作原理
Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的. mysql原理图各个组件说明: 1. connectors 与其他编程语言中的sql 语句进行交互,如php.java等. 2. M ...
- vue 动态样式
<p :style="{width:'4px',height: '24px',background: '#f7ce51'}"></p> <p:styl ...
- 菜鸟学IT之python词云初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822 1. 下载一长篇中文小说. 2. 从文件读取待分析文本. txt = ...
- Hive基础知识
一.产生背景 1.MapReudce编程繁琐,需要编写大量的代码 2.HDFS中存放的都是文件,在HDFS中没有Scheme的概念,无法用SQL进行快速的查询. 二.Hive的概念 Hive是基于Ha ...
- SpringCloud---熔断降级理解、Hystrix实战(五)
SpringCloud---熔断降级理解.Hystrix实战(五) https://www.cnblogs.com/qdhxhz/p/9581440.html https://blog.csdn.ne ...